# [ sono riprodotte solo alcune immagini; per le altre uscite grafiche
# e alfanumeriche eseguire i comandi ]
# Vediamo come analizzare i dati raccolti in una tabella come questa, in cui,
# per 20 individui, è indicato con 1/2 il sesso maschile/femminile, con 1,2,3
# la fascia (crescente) di reddito, con 0,1,… il numero di auto possedute dal
# nucleo familiare, con 0/1 se non si è/si è fumatori.
 # I dati sono stati raccolti nel file "sraf" (gli 'a capo' sono stati messi
# per facilitare la lettura: R "capisce" che il comnado è su più righe)
sraf <- c(
1,1,1,0,
1,3,1,0,
2,3,2,0,
2,2,0,1,
2,3,3,0,
2,1,1,0,
1,2,1,0,
2,1,2,1,
2,2,1,1,
2,1,0,0,
1,2,1,1,
1,1,2,0,
1,1,2,1,
1,2,0,0,
2,3,3,0,
1,1,1,0,
1,3,2,0,
2,1,2,1,
2,2,0,1,
2,3,3,0)
# Ora voglio metterli in una tabella 20×4. Provo:
sraf1 <- matrix(sraf, nrow=20, ncol=4); sraf1
# Dalle uscite capisco che il programma ha letto i dati colonna per colonna.
# Per farglieli leggere riga per riga dovevo introdurre i dati diversamente:
# sraf <- c(
# 1,1,2,2,2,2,1,2,2,2,1,1,1,1,2,1,1,2,2,2,
# 1,3,3,2,3,1,2,1,2,1,2,1,1,2,3,1,3,1,2,3,
# 1,1,2,0,3,1,1,2,1,0,1,2,2,0,3,1,2,2,0,3,
# 0,0,0,1,0,0,0,1,1,0,1,0,1,0,0,0,0,1,1,0)
# Questo sarebbe il modo standard da impiegare.
# Oppure posso fare così:
sraf1 <- matrix(sraf, nrow=20, ncol=4, byrow=TRUE)
sraf1
# OK. Posso aggiungere i "nomi": i numeri da 1 a 20 per le righe, i nomi
# che rappresentano che cosa sono i vari dati per le colonne:
nomi <- list(1:20,c("sesso","reddito","n.auto","fumo"))
sraf1 <- matrix(sraf, nrow=20, ncol=4, byrow=TRUE, dimnames=nomi)
sraf1
# La tabellina sopra raffigurata posso visulizzarla col comando seguente
# ( poi la chiudo cliccando [x] )
edit(sraf1)
#
# Voglio estrarre ed esaminare i dati della prima colonna (sesso)
sesso <- sraf1[,1]; sesso
# e farne l'istogramma
hist(sesso)
# Mi conviene scegliere gli estremi degli intervalli, centrati in 1 e 2:
hist(sesso,c(0.5,1.5,2.5),col="yellow")
# Aggiungo una griglia, tracciando delle rette orizzontali tratteggiate
abline(h=1:11,lty=3)
# Tracciamo l'istogramma con le densità invece che con le frequenze assolute.
hist(sesso,c(0.5,1.5,2.5),freq=FALSE,col="yellow")
abline(h=seq(0.1,0.6,0.1),lty=3)
# Posso stabilire la scala verticale in modo da leggere meglio l'istogramma:
hist(sesso,c(0.5,1.5,2.5),freq=FALSE,col="yellow",ylim=c(0,0.6))
abline(h=seq(0.1,0.6,0.1),lty=3)
# Posso colorare diversamente le colonne e mettere un titolo alternativo:
hist(sesso,c(0.5,1.5,2.5),freq=FALSE,ylim=c(0,0.6),col=c("cyan","pink"),main="M/F")
abline(h=seq(0.1,0.6,0.1),lty=3)
# I dati sono stati raccolti nel file "sraf" (gli 'a capo' sono stati messi
# per facilitare la lettura: R "capisce" che il comnado è su più righe)
sraf <- c(
1,1,1,0,
1,3,1,0,
2,3,2,0,
2,2,0,1,
2,3,3,0,
2,1,1,0,
1,2,1,0,
2,1,2,1,
2,2,1,1,
2,1,0,0,
1,2,1,1,
1,1,2,0,
1,1,2,1,
1,2,0,0,
2,3,3,0,
1,1,1,0,
1,3,2,0,
2,1,2,1,
2,2,0,1,
2,3,3,0)
# Ora voglio metterli in una tabella 20×4. Provo:
sraf1 <- matrix(sraf, nrow=20, ncol=4); sraf1
# Dalle uscite capisco che il programma ha letto i dati colonna per colonna.
# Per farglieli leggere riga per riga dovevo introdurre i dati diversamente:
# sraf <- c(
# 1,1,2,2,2,2,1,2,2,2,1,1,1,1,2,1,1,2,2,2,
# 1,3,3,2,3,1,2,1,2,1,2,1,1,2,3,1,3,1,2,3,
# 1,1,2,0,3,1,1,2,1,0,1,2,2,0,3,1,2,2,0,3,
# 0,0,0,1,0,0,0,1,1,0,1,0,1,0,0,0,0,1,1,0)
# Questo sarebbe il modo standard da impiegare.
# Oppure posso fare così:
sraf1 <- matrix(sraf, nrow=20, ncol=4, byrow=TRUE)
sraf1
# OK. Posso aggiungere i "nomi": i numeri da 1 a 20 per le righe, i nomi
# che rappresentano che cosa sono i vari dati per le colonne:
nomi <- list(1:20,c("sesso","reddito","n.auto","fumo"))
sraf1 <- matrix(sraf, nrow=20, ncol=4, byrow=TRUE, dimnames=nomi)
sraf1
# La tabellina sopra raffigurata posso visulizzarla col comando seguente
# ( poi la chiudo cliccando [x] )
edit(sraf1)
#
# Voglio estrarre ed esaminare i dati della prima colonna (sesso)
sesso <- sraf1[,1]; sesso
# e farne l'istogramma
hist(sesso)
# Mi conviene scegliere gli estremi degli intervalli, centrati in 1 e 2:
hist(sesso,c(0.5,1.5,2.5),col="yellow")
# Aggiungo una griglia, tracciando delle rette orizzontali tratteggiate
abline(h=1:11,lty=3)
# Tracciamo l'istogramma con le densità invece che con le frequenze assolute.
hist(sesso,c(0.5,1.5,2.5),freq=FALSE,col="yellow")
abline(h=seq(0.1,0.6,0.1),lty=3)
# Posso stabilire la scala verticale in modo da leggere meglio l'istogramma:
hist(sesso,c(0.5,1.5,2.5),freq=FALSE,col="yellow",ylim=c(0,0.6))
abline(h=seq(0.1,0.6,0.1),lty=3)
# Posso colorare diversamente le colonne e mettere un titolo alternativo:
hist(sesso,c(0.5,1.5,2.5),freq=FALSE,ylim=c(0,0.6),col=c("cyan","pink"),main="M/F")
abline(h=seq(0.1,0.6,0.1),lty=3)
 #
# Posso affiancare i due istogrammi in finestre diverse, col comando dev.new:
dev.new(width=3,height=3,xpos=100,ypos=30) # dimensiono la prima finestra
hist(sesso,c(0.5,1.5,2.5),col="yellow")
dev.new(width=3,height=3,xpos=500,ypos=30) # dimensiono l'altra ugualmente ma la sposto a destra
hist(sesso,c(0.5,1.5,2.5),freq=FALSE,col="yellow")
# Chiudiamo le due finestre grafiche.
#
# Posso impiegare il comando dev.new tutte le volte che voglio conservare
# i grafici precedenti.
#
# Posso mettere i due istogrammi in un'unica finestra suddivisa in parti:
dev.new(width=5,height=3); par(mfrow=c(1,2))
# Ho aperto una finestra grafica, che poi posso ridimensionare col mouse
# (potevo anche non aprirla: lo avrebbe fatto automaticamente il programma).
# Predispongo R a suddividerla in due parti: 1 riga e 2 colonne
hist(sesso,c(0.5,1.5,2.5),col="yellow"); abline(h=axTicks(2),lty=3)
hist(sesso,c(0.5,1.5,2.5),freq=FALSE,col="yellow"); abline(h=axTicks(2),lty=3)
# Chiudiamo la finestra.
#
# Un modo "testo" per ottenere gli istogrammi è il comando stem che traccia
# il diagramma stem-and-leaf. Vediamolo del reddito (3ª colonna):
stem(sraf1[,3]) # [,n] indica l'n-ma colonna, [n,] l'n-ma riga
#
# Come analizzare congiuntamente reddito e numero di auto possedute?
ra <- sraf1[,2:3]; ra
# traccio i punti "reddito, n.auto":
plot(ra)
# o, meglio:
plot(ra,pch=19)
abline(h=axTicks(2),v=axTicks(1),col="red",lty=3)
#
# Posso affiancare i due istogrammi in finestre diverse, col comando dev.new:
dev.new(width=3,height=3,xpos=100,ypos=30) # dimensiono la prima finestra
hist(sesso,c(0.5,1.5,2.5),col="yellow")
dev.new(width=3,height=3,xpos=500,ypos=30) # dimensiono l'altra ugualmente ma la sposto a destra
hist(sesso,c(0.5,1.5,2.5),freq=FALSE,col="yellow")
# Chiudiamo le due finestre grafiche.
#
# Posso impiegare il comando dev.new tutte le volte che voglio conservare
# i grafici precedenti.
#
# Posso mettere i due istogrammi in un'unica finestra suddivisa in parti:
dev.new(width=5,height=3); par(mfrow=c(1,2))
# Ho aperto una finestra grafica, che poi posso ridimensionare col mouse
# (potevo anche non aprirla: lo avrebbe fatto automaticamente il programma).
# Predispongo R a suddividerla in due parti: 1 riga e 2 colonne
hist(sesso,c(0.5,1.5,2.5),col="yellow"); abline(h=axTicks(2),lty=3)
hist(sesso,c(0.5,1.5,2.5),freq=FALSE,col="yellow"); abline(h=axTicks(2),lty=3)
# Chiudiamo la finestra.
#
# Un modo "testo" per ottenere gli istogrammi è il comando stem che traccia
# il diagramma stem-and-leaf. Vediamolo del reddito (3ª colonna):
stem(sraf1[,3]) # [,n] indica l'n-ma colonna, [n,] l'n-ma riga
#
# Come analizzare congiuntamente reddito e numero di auto possedute?
ra <- sraf1[,2:3]; ra
# traccio i punti "reddito, n.auto":
plot(ra)
# o, meglio:
plot(ra,pch=19)
abline(h=axTicks(2),v=axTicks(1),col="red",lty=3)
 # Ci sono molti punti sovrapposti. Potremmo fare un istogramma tridimensionale.
# Vediamo un modo più semplice, costruendo una tabella.
# Potrei farlo direttamente, classificando i dati:
# 0A 1A 2A 3A
# R1 1 3 4 0
# R2 3 3 0 0
# R3 0 1 2 3
# (ricordiamo che tabelle a 2 entrate come questa vengono dette "di contingenza")
# Facciamolo fare ad R (per avere idea di come farlo in situazioni più complesse)
#
# Classifichiamo le coppie "reddito, n.auto"
# Il numero di "righe" con reddito=i & n.auto=j: fissato (i,j)
# conto le righe in cui la prima colonna vale i e la seconda j
nra <- function(i,j) {n <- 0;
for(h in 1:20) n <- n + ifelse(ra[h,1]==i & ra[h,2]==j,1,0); n}
# La matrice "reddito, n.auto"
tcra <- c(
nra(1,0),nra(2,0),nra(3,0),
nra(1,1),nra(2,1),nra(3,1),
nra(1,2),nra(2,2),nra(3,2),
nra(1,3),nra(2,3),nra(3,3))
nomir <- list(c("R1","R2","R3"),c("0A","1A","2A","3A"))
tcra1 <- matrix(tcra,ncol=4,nrow=3,dimnames=nomir)
tcra1 # Eccola:
#
# Rappresentiamo graficamente la tabella con due diagrammi a barre
# che traccio nella medesima finestra:
dev.new(width=6,height=3); par(mfrow=c(1,2))
barplot(tcra1); abline(h=axTicks(2),lty=3)
# Metto come "titolo laterale" i "nomi"
title(ylab="R1 R2 R3")
#
# Nell'altra finestra traccio l'altro diagramma coi dati trasposti
# (scambio righe con colonne)
tcra2 <- t(tcra1)
barplot(tcra2); abline(h=axTicks(2),lty=3)
title(ylab="0a 1a 2a 3a")
# Ci sono molti punti sovrapposti. Potremmo fare un istogramma tridimensionale.
# Vediamo un modo più semplice, costruendo una tabella.
# Potrei farlo direttamente, classificando i dati:
# 0A 1A 2A 3A
# R1 1 3 4 0
# R2 3 3 0 0
# R3 0 1 2 3
# (ricordiamo che tabelle a 2 entrate come questa vengono dette "di contingenza")
# Facciamolo fare ad R (per avere idea di come farlo in situazioni più complesse)
#
# Classifichiamo le coppie "reddito, n.auto"
# Il numero di "righe" con reddito=i & n.auto=j: fissato (i,j)
# conto le righe in cui la prima colonna vale i e la seconda j
nra <- function(i,j) {n <- 0;
for(h in 1:20) n <- n + ifelse(ra[h,1]==i & ra[h,2]==j,1,0); n}
# La matrice "reddito, n.auto"
tcra <- c(
nra(1,0),nra(2,0),nra(3,0),
nra(1,1),nra(2,1),nra(3,1),
nra(1,2),nra(2,2),nra(3,2),
nra(1,3),nra(2,3),nra(3,3))
nomir <- list(c("R1","R2","R3"),c("0A","1A","2A","3A"))
tcra1 <- matrix(tcra,ncol=4,nrow=3,dimnames=nomir)
tcra1 # Eccola:
#
# Rappresentiamo graficamente la tabella con due diagrammi a barre
# che traccio nella medesima finestra:
dev.new(width=6,height=3); par(mfrow=c(1,2))
barplot(tcra1); abline(h=axTicks(2),lty=3)
# Metto come "titolo laterale" i "nomi"
title(ylab="R1 R2 R3")
#
# Nell'altra finestra traccio l'altro diagramma coi dati trasposti
# (scambio righe con colonne)
tcra2 <- t(tcra1)
barplot(tcra2); abline(h=axTicks(2),lty=3)
title(ylab="0a 1a 2a 3a")
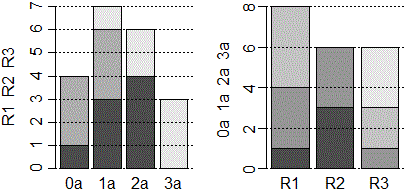 # Nel primo diagramma vedo che, nel nostro piccolo campione, sono di più le
# famiglie con un'auto sola e seguono quelle con due. Vedo anche che solo
# le famiglie con alto reddito hanno 3 auto. Nel secondo diagramma vedo ...
# Nel primo diagramma vedo che, nel nostro piccolo campione, sono di più le
# famiglie con un'auto sola e seguono quelle con due. Vedo anche che solo
# le famiglie con alto reddito hanno 3 auto. Nel secondo diagramma vedo ...