 scheda2,§7] come, ad es., 75° percentile di N (n° teste uscite lanciando 10 monete eque) prendiamo 6 in quanto figura sottostante, a sinistra.
scheda2,§7] come, ad es., 75° percentile di N (n° teste uscite lanciando 10 monete eque) prendiamo 6 in quanto figura sottostante, a sinistra.5. PERCENTILI e funzione di RIPARTIZIONE (cumulativa). Alcune variabili casuali funzioni di altre variabili casuali: U=X^2, U=X*Y, U=X+Y con X e Y uniformi in [0,1).
Come vengono calcolate mediana e percentile di ordine p nel caso di una variabile aleatoria continua?
Nel caso discreto [ scheda2,§7] come, ad es., 75° percentile di N (n° teste uscite lanciando 10 monete eque) prendiamo 6 in quanto figura sottostante, a sinistra.

Con STAT si può ottenere il grafico della frequenza relativa cumulata esattamente nello stesso modo in cui si ottiene l'istogramma, a patto di mettere la lettera "C" nel box a sinistra di [S] prima di cliccare [Plot]. Se si mette "C/" invece che a scalini (come sopra a sinistra), il grafico viene realizzato mediante una interpolazione lineare (come sopra a destra).
|
Nel caso dell'analisi statistica di una variabile casuale ad uscite in un intervallo
che sia stata classificata in intervalli di diversa ampiezza, ovviamente, non posso interpretare
il grafico della frequenza cumulata come un "accumulo di colonne", se considero rettangoli con basi
proporzionali alle ampiezze degli intervalli. A lato è illustrato che cosa si può ottenere
con STAT per le frequenze cumulate di mor1, mor2 e mor3 [ E` illustrato anche graficamente come vengono determinati i percentili in questi casi (qui è raffigurata la determinazione della mediana di mor2). In questi casi posso interpretare il calcolo delle frequenze relative cumulate come il calcolo dell'area di sezioni sinistre dell'istogramma della densità di frequenza: |
 |
Passando dal caso "statistico" a quello "probabilistico"
alla frequenza relativa cumulata sostituiamo la funzione di ripartizione
(o di distribuzione cumulativa o funzione integrale di distribuzione)
 Pr(U≤x) Pr(U<x),
equivalente nel caso continuo), che, se la variabile casuale è continua,
permette di esprimere l'area delle sezioni sinistre della superficie sottostante
il grafico della funzione densità:
Pr(U≤x) Pr(U<x),
equivalente nel caso continuo), che, se la variabile casuale è continua,
permette di esprimere l'area delle sezioni sinistre della superficie sottostante
il grafico della funzione densità:
se f è una funzione densità, la corrispondente funzione di ripartizione F è: F(x) = a  x f
x f
se F è derivabile, si ha: F' = f.
Nel caso continuo, mentre la mediana è la soluzione dell'equazione F(x)=0.5, il percentile di ordine p è la soluzione dell'equazione F(x) = p/100.
|
F (come discende immediatamente dalle proprietà delle misure di probabilità) è non decrescente e, per x che tende all'estremo sinistro [destro] dell'intervallo di definizione di f, F(x) tende a 0 |  |
Se si sa esplicitare F-1, la soluzione di F(x)=p/100 è esprimibile come F-1(p/100).
Ad es. per la distribuzione esponenziale ho:
F(x) = 0 x a e– a x dx = 1 - e– a x e F-1(x) = –ln(1–x)/a = –ln(1–x)·m.
Quindi la mediana è –ln(1/2)·m.
Se effettuo questo calcolo prendendo come m la media dei dati T-TELEF2 ( scheda 1, quesito 9: m=8.97) trovo 6.2, in buon accordo con il valore sperimentale, 6.4.
Verificare che x
1/(π·(1+x2)) è una funzione densità,
determinarne la funzione di ripartizione, rappresentare graficamente le due funzioni.
[tale distribuzione, detta "di Cauchy", non ha media: Proviamo a studiare sperimentalmente e teoricamente le variabili aleatorie U=X2 e V=X·Y con X e Y variabili aleatorie con distribuzione uniforme in [0,1).
Per individuare la curva a cui tende l'istogramma di distribuzione di RND*RND (in scala verticale normalizzata), interpreto le coppie RND,RND man mano generate come punti che cadono nel quadrato [0,1]2.
Per una verifica posso esportare l'istogramma in Poligon, definire f(x)=-log(x) e sovrapporre ad esso il grafico di f tra 0.001 e 1; nella precedente figura contenente l'istogramma appare anche il grafico di f.
Del resto è facile ricavare che se t ha distribuzione uniforme, posto U=t2,
P(U≤x)=
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||





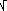 x e, quindi, f(x)=1/(2
x e, quindi, f(x)=1/(2