 §2, punto B) che l'ipotesi viene testata con un livello di confidenza del 95%: è la probabilità che, se l'ipotesi fosse "vera", la regione di coerenza contenga il valore di χ2, ovvero il test dia esito positivo.
§2, punto B) che l'ipotesi viene testata con un livello di confidenza del 95%: è la probabilità che, se l'ipotesi fosse "vera", la regione di coerenza contenga il valore di χ2, ovvero il test dia esito positivo.8. Altri TEST di SIGNIFICATIVITA`. Esempi tratti da prove scritte di esami di maturita`
Il "test χ2" considerato nel paragrafo precedente è un "test di adattamento": è usato per valutare l'adattamento di una certa distribuzione teorica a una serie di dati sperimentali. Non è l'unico test di adattamento, ma è il più usato e quello che ha un più vasto campo di applicazione.
Un altro test di adattamento d'uso frequente è il test di Kolmogorov, che usa come misuratore della discordanza il massimo dei valori assoluti degli scarti tra frequenza cumulata e distribuzione cumulata teorica. Esso è tuttavia applicabile solo quando la distribuzione teorica sia completamente nota, non nel caso in cui alcuni suoi parametri siano calcolati a partire dai dati statistici; in altre parole, non tiene conto dei gradi di libertà.
Se si assume come regione di non rifiuto (o, meglio, di coerenza o conformità tra dati e teoria) il 95% centrale, cioè l'intervallo compreso tra il percentile di ordine 2.5 e il percentile di ordine 97.5, si dice anche ( §2, punto B) che l'ipotesi viene testata con un livello di confidenza del 95%: è la probabilità che, se l'ipotesi fosse "vera", la regione di coerenza contenga il valore di χ2, ovvero il test dia esito positivo.
Il complemento a 1 del livello di significatività è l'ampiezza della regione complementare, cioè della regione critica (o di incoerenza); tale ampiezza viene invece chiamata livello di significatività (in questo caso è: 1–95%=5%): è la probabilità che, se l'ipotesi fosse "vera", la regione di incoerenza contenga il valore di χ2, ovvero il test dia ("erroneamente") esito negativo.
Esistono molti altri tipi di test statistici, oltre ai test di adattamento e al test a cui abbiamo accennato nel §2 (accettazione dell'ipotesi che 3/7 sia Pr(A) come plausibile con un certo livello di significatività). Vediamone qualcun altro a partire da un (discutibile) quesito tratto dalla prova scritta di matematica dell'esame di maturità del 1994/95 per le classi che hanno sperimentato il P.N.I. (Piano Nazionale Informatica):
Nella tabella seguente sono riportati i dati di un'indagine campionaria, relativamente ad alcune regioni e al 1990, sulla distribuzione delle abitazioni secondo la superficie abitata (area espressa in metri quadrati):
|
Il candidato: a) stimi la superficie media abitata nelle tre regioni e la deviazione standard delle stime, assumendo come valore rappresentativo di ogni classe il valore medio; b) rappresenti mediante diagrammi opportuni le distribuzioni marginali, rispettivamente per regioni e per superficie; | ||||||||||||||||||||||||||
c) verifichi l'ipotesi: non c'è differenza significativa (5%) tra le medie delle superfici delle diverse regioni;
d) verifichi l'ipotesi: non c'è differenza significativa (5%) tra le distribuzioni relative alle diverse regioni.
Vediamo come interpretare (o correggere) il testo e come affrontare le soluzioni.
Quesito a. Il testo parla di valore medio. In realtà si vuole indicare il valore centrale degli intervalli (che, volendo, si può calcolare facendo la media aritmetica degli estremi). Nel caso del primo intervallo, 50-95, cioè [50,96), il valore centrale è 50+semiampiezza = 50+23 = 73. I valori centrali degli altri intervalli sono 103.5, 121, 166. Quindi la stima della superficie abitata in Liguria è ML = (130·73+11·103.5+…)/(130+ 11+…) = 12184.5/152 = 80.16… = 80 (arrotondando). Analogamente MC = 102.84=103, MS = 92.85 = 93.
Le deviazioni standard (s.q.m.), calcolate con una delle formule viste o con una CT, sono 19.79 (=20), 18.78 (=19), 27.78 (=28).
|
Quesito b. Le distribuzioni marginali sono le distribuzioni dei totali per riga e per colonna ( |
 |
Si noti che l'istogramma relativo alle regioni non dà informazioni sulla distribuzione "reale" degli appartamenti nelle tre regioni, ma solo la distribuzione relativa agli appartamenti del campione complessivo, che, evidentemente, non è stato scelto in modo che ci fosse proporzionalità tra i campioni delle singole regioni e il numero di appartamenti presenti in esse (non è un campione rappresentativo dell'unione delle 3 regioni).
Quesito c. Il testo intende chiedere di verificare la plausibilità che le medie teoriche delle superfici abitate delle tre regioni non siano diverse, cioè che due a due abbiano differenza 0. Considero Campania e Liguria. Devo valutare se lo scarto da 0 della differenza tra le due medie sperimentali (102.84–80.16 = 22.68) è accettabile come "normale" con confidenza del 95%, cioè se l'intervallo di confidenza al 95% della differenza delle medie (l'intervallo in cui al 95% cade la differenza teorica, cioè la differenza riferita alla popolazione limite) contiene 0.
Nel testo, parlando di differenza significativa, si intenderebbe dire che si deve assumere 5% come livello di significatività, cioè come ampiezza della regione di rifiuto, ossia 100%–(probabilità di confidenza).
Le medie hanno, tendenzialmente, distribuzione gaussiana. La differenza delle medie è la media delle differenze, che sarà anch'essa, tendenzialmente, gaussiana. Devo trovare il σ di questa gaussiana. La varianza della differenza è la somma delle varianze; le varianze delle due medie (calcolate con STAT, una calcolatrice o un foglio di calcolo; nota fine §4) sono 2.593 e 0.147; quindi σ = 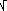 (2.593+0.147)
(2.593+0.147)
Al 95.4% (significatività del 4.6%) il valore dovrebbe cadere in [m–2σ, m+2σ] = [0–1.66·2, 0+1.66·2] = [–3.32, 3.32], che non contiene 22.68. A maggior ragione l'ipotesi è da rifiutare al livello di significatività del 5% (per avere una confidenza al 95% occorre prendere, invece di 2·σ, t·σ con t = 1.96; l'intervallo di confidenza diventa [1.66·1.96, 1.66·1.96] = [–3.25, 3.25]).
Quesito d. La richiesta equivale al fatto che le tre distribuzioni siano tendenzialmente proporzionali, cioè (vedi la scheda 3) al fatto che la modalità "regione" sia indipendente dalla modalità "superficie".
Dobbiamo quindi confrontare le frequenze sperimentali nelle 12 celle della tabella – la cella incrocio della riga "Liguria" e della colonna [50,96), …, quella incrocio di "Sicilia" e [131,200) – con le frequenze attese – i prodotti (frequenza di "Liguria")·(frequenza di [50,96)), …, (frequenza di "Sicilia")·(frequenza di [131,200)). Si fa ciò usando il test χ2. Si ottiene χ2=1342. Il programma Chi2Ind.bas che consente di calcolare il χ2 data la tabella.
I gradi di libertà sono (4–1)·(3-1) = 6; infatti fissate le frequenze totali delle 4 regioni e delle 3 classi di appartamento (sono i valori che uso per calcolare le frequenze attese), di ogni riga mi basta conoscere 3 celle (la quarta la ottengo usando la frequenza totale della riga) e, analogamente, di ogni colonna 3–1=2 celle. Dalla tabulazione di χ2 si ottiene la non normalità (al 95%) di questo valore: l'intervallo di normalità al 95% dovrebbe essere quello compreso tra i percentili di ordine 2.5 e 97.5, cioè [1.2, 14.4].
n. GRADI di liberta` = 6 Pr( chi2>K ) 2.5% 5% 10% 20% 30% 50% 70% 80% 90% 95% 97.5% K 1.2 1.6 2.2 3.0 3.8 5.3 7.2 8.4 10.5 12.6 14.4
Questi ultimi (quesiti c e d) sono tipici esempi in cui a occhio, guardando le tabelle, si vede che le ipotesi considerate sono sicuramente da rifiutare. I valori molto grandi di χ2 confermano bene ciò. Sono esempi in cui è abbastanza "stupido" porsi il problema di usare il test χ2. Dispiace che quesiti del genere vengano proposti agli esami di maturità (osserviamo, comunque, che nelle più recenti versioni dei "nuovi programmi" l'argomento "test" è stato ridimensionato o tolto, a seconda degli indirizzi).
Note.
• Alcuni usano il test χ2 non in modo "bilaterale" come si è fatto noi (e come, ad es., è detto si deve fare nei manuali di Ventsel e di Gilchrist), cioè rifiutando, come anormali, anche le ipotesi che danno luogo a valori di χ2 "piccoli", ma in modo "unilaterale", rifiutando solo i casi in cui si ottengono χ2 "alti" (ad es. a una significatività del 5% corrisponde un ordine di percentile non tra 2.5 e 97.5 ma sotto a 5). Costoro accettano l'ipotesi che una moneta per cui si ottengono uscite come quelle dei quesiti 12 e 14 sia equa. In effetti se effettuo il test rispetto all'ipotesi che l'uscita "testa" abbia probabilità del 45% ottengo, con quei dati, un valore di χ2 (9.7) ancora più anormale; ma se considero l'ipotesi che la probabilità sia del 48% ottengo un valore (1.4) più normale. In ogni caso, se la moneta fosse effettivamente equa tali uscite sarebbero altamente improbabili.
Possono esservi casi in cui ha senso usare il test χ2 o altri test in modo unilaterale, ma ciò deve essere giustificato. Si vedano anche le osservazioni critiche svolte nel punto (B) del §2 sui modi in cui sono formulate le ipotesi.
• Testare un'ipotesi H di diseguaglianza, come "k ≤ M(X)", è più complicato che testarne una di eguaglianza, come "M(X) = M(Y)" (è tale quella del quesito c precedente, che ho ricondotto a M(X–Y)=0): non basta analizzare come un certo valore si colloca rispetto a una data distribuzione. Il problema viene affrontato considerando la corrispondente ipotesi di eguaglianza (M(X)=k nell'esempio fatto), che viene chiamata ipotesi nulla (è l'ipotesi che la differenza tra M(X) e k sia nulla) e indicata con H0, e formulando una opportuna l'ipotesi alternativa H1.
Se H è k ≤ M(X), con testare H con il livello di significatività p% si intende: prendere M(X)=k come H0 e
Esempio (tratto, con modifiche, dal manuale di Gilchrist).
(1) Ho 20 dati (10.4, 9.3, 11.2, 10.1, 10.8, 9.7, 9.7, 8.2, 10.2, 10.6, 9.5, 10.0, 10.1, 10.2, 10.3, 9.2, 10.4, 8.8, 11.0, 8.7) relativi alla concentrazione X (grammi/litro) di un sale in una soluzione. Assumo che X sia distribuita gaussianamente. Voglio testare l'ipotesi che σ(X)=1.1 con la significatività del 5%.
Per trovare intervalli di confidenza della media, come si è visto, si usa il fatto che Mn(X) ha andamento gaussiano. Per trovare intervalli di confidenza per la varianza di una distribuzione gasussiana di s.q.m. σ si utilizza il fatto che la variabile statistica Varn(X)·n/σ ha distribuzione χ2(n–1).
Vediamo perché. Noto il valore m di M(X), calcolando Σ(Xi–m)2/n (i=1,…,n) per n prove Xi otterrei una stima corretta e non distorta di Var(X). Se non conosco M(X) e uso la media empirica Mn(X), il calcolo di Varn(X) (se X è gaussiana di s.q.m. σ) si comporta come la somma divisa per n dei quadrati delle n–1 gaussiane Xi–m aventi media 0 e s.q.m. σ. Poiché χ2(r) – come osservato nel paragrafo 7 – è la somma dei quadrati di r gaussiane con media 0 e s.q.m. 1, Varn(X)·n/σ2 ha distribuzione χ2(n–1). |
Coi miei dati ottengo 9.71 come V20(X)·20/(1.1)2, cioè come χ2(19) sperimentale. I percentili di ordine 2.5 e 97.5 sono ( tabella nel §7) 8.9 e 32.9; 9.71 sta quindi nella regione di coerenza.
(2) Se invece voglio testare l'ipotesi che σ(X)>1.1 considero "σ(X)=1.1 contro σ(X)>1.1" e prendo come sua regione di coerenza l'intervallo corrispondente al 95% sinistro della superficie delimitata dalla distribuzione 2; il 95° percentile è 30.1; 9.7 sta quindi nelle regione di coerenza: non rifiuto, quindi, "σ(X)=1.1", cioè non ritengo coerente "σ(X)>1.1".
(3) Se invece voglio testare l'ipotesi che σ(X)<1.1 considero "σ(X)=1.1 contro σ(X)<1.1", la cui regione di coerenza è quella a destra del 5° percentile, cioè 10.1; 9.7 non sta nella regione di coerenza: quindi, rispetto a questo test, ritengo coerente non "σ(X)=1.1" ma "σ(X)<1.1".
Quindi sia l'ipotesi σ(X)=1.1 (test 1) che l'ipotesi σ(X)<1.1 (test 3) non sono rifiutabili al livello di significatività del 5%. La apparente contraddizione di queste conclusioni mette in luce la natura convenzionale delle definizioni date, oltre che la natura probabilistica delle conclusioni (accettare/non accettare un'ipotesi non significa che essa sia vera/falsa).
• Accanto al concetto di livello di confidenza di un test, richiamato all'inizio del paragrafo, cioè la probabilità
| <<< Paragrafo precedente | Paragrafo successivo >>> |