 PXÀPY) si è usata l'indipendenza di X e Y. Con PX/PY/PX,Y si è indicata la variabile aleatoria che esprime la probabilità di un generico stato del sistema, rispettivamente, X/Y/(X,Y).
PXÀPY) si è usata l'indipendenza di X e Y. Con PX/PY/PX,Y si è indicata la variabile aleatoria che esprime la probabilità di un generico stato del sistema, rispettivamente, X/Y/(X,Y).7. Suggerimenti e risposte ai quesiti.
| 1 |
Supponendo l'anno di nascita non bisestile, supponendo, in assenza di altre informazioni, che le date di nascita siano equiprobabili, l'entropia è log2365=8.5117. Per tener conto della bisestilità occorre utilizzare le considerazioni successive al quesito 1. Dopo che le hai lette prova a risolvere nuovamente l'esercizio. Dopo controlla la tua soluzione con la seguente:
Supponendo di non avere informazioni per valutare se la persona è nata in un anno bisestile, considero equiprobabili le date scelte tra 4 anni consecutivi, pari a 365À4+1=1461 giorni. La probabilità del 29/2 è 1/1461, quella delle altre date è 4/1461. L'entropia è quindi: û365À4/1461Àlog24/1461û1/1461Àlog21/1461 = 8.5069+ 0.0072 = 8.5141. È di poco maggiore di 8.5117, in quanto la nascita nel giorno 29/2 è un evento raro.
Torna al punto 1
| 2 |
û0.7Àlog20.7û0.3Àlog20.3=0.8813<1; vedi anche il 2░ punto dopo il quesito 3. Pr(TT or CC) = 0.72+0.32=0.58; Pr(not (TT or CC)) = 0.42; dal grafico si può ottenere per l'entropia il valore approssimato 0.45+0.53 = 0.98▒0.01; col calcolo si ottiene 0.98145à, da cui si può ottenere 0.98 come arrotondamento a due cifre.
Torna al punto 2
| 3 |
H(X,Y) = M(ûlog PX,Y) = M(ûlog (PXÀPY)) = M(ûlog PX û log PY) = H(X) + H(Y) dove nella seconda trasformazione (PX,Y PXÀPY) si è usata l'indipendenza di X e Y. Con PX/PY/PX,Y si è indicata la variabile aleatoria che esprime la probabilità di un generico stato del sistema, rispettivamente, X/Y/(X,Y).
| 4 |
Il procedimento di assegnazione di 0 e 1 a eventi il più possibile equiprobabili garantisce (in base alla osservazione che precede il quesito) l'ottimalità del codice. Ecco la codifica di alcuni caratteri:
û: 000 a: 001 e: 010 o: 0110 i: 0111 s: 1000 à q: 11111110 ': 11111111
Nota 1. L'ottimalità vale solo in quanto ci siamo ristretti ai codici letterali. Allargandosi, non vale più. Infatti le lettere vicine in un testo sono correlate: alla "q" segue in genere la "u", alla "h" segue in genere una vocale, à . Sarebbe più economico un codice che codifichi non singole lettere, ma blocchi di lettere.
Nota 2. Spesso, nella trasmissione delle informazioni, non si usano codici ottimali ma si privilegiano codifiche a quantità fisse di bit per ogni carattere e/o si codificano lettere o gruppi di lettere con uno o più bit aggiuntivi rispetto al necessario, bit che vengono utilizzati come delimitatori o segnali di "controllo". Infatti, nel caso di qualche errore di codificazione, trasmissione o decodificazione (perdita o confusione accidentale dei segni 0 e 1), un errore locale, non individuato, rischierebbe di compromettere la decodifica dell'intero documento.
Torna al punto 4
| 5 |
(1) n=1; (2) scrivi "0."; (3) scrivi n volte "1"; (4) scrivi "0"; (5) poni n=n+1; (6) vai a (3) è un algoritmo che genera il numero irrazionale (= non periodico), e trascendente, ma non casuale, 0.10110111011110à . Altri esempi sono π, e, 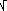 2 e sin 3, che sono generabili con vari possibili algoritmi. Si noti che i numeri reali generabili con un algoritmo (ovvero di cui possiamo conoscere, potenzialmente, tutte le cifre che vogliamo) sono una infinità numerabile, essendo tale la quantità dei programmi che si possono descrivere con un linguaggio formale: la conoscenza delle cifre della stragrande maggioranza dei numeri reali non è alla nostra portata.
2 e sin 3, che sono generabili con vari possibili algoritmi. Si noti che i numeri reali generabili con un algoritmo (ovvero di cui possiamo conoscere, potenzialmente, tutte le cifre che vogliamo) sono una infinità numerabile, essendo tale la quantità dei programmi che si possono descrivere con un linguaggio formale: la conoscenza delle cifre della stragrande maggioranza dei numeri reali non è alla nostra portata.
| 6 |
Nel primo caso la scelta dei parametri (a, c, à) ha prodotto una successione con periodo lungo 4
(tutte le definizioni del tipo
Nel terzo caso siamo di fronte a un metodo diverso; sembra che si ottengano moltissimi valori diversi.
Il procedimento grafico evidenzia la "bontà" del generatore di Poligon (uscite analoghe si avrebbero per il generatore del QBasic o di JavaScript). Per il secondo caso (in cui le uscite sono state divise per M in modo da avere valori tra 0 e 1) viene messo in luce che la distribuzione non è molto uniforme e che vi sono delle evidenti correlazioni tra le uscite (si vedano le strisce di punti). Per il terzo caso sembra che si ottenga una buona distribuzione di punti analoga a quella del generatore di Poligon, QBasic, …. Ma non è proprio così si veda il seguito del paragrafo.
| <<< Paragrafo precedente | INDICE |