
Sul teorema limite centrale
(faremo quache calcolo con la versione del software R accessibile da qui, in cui la sommatoria
è indicata sum,
il coefficiente binomiale
Supponiamo che una fabbrica di biscotti disponga di un forno che bruciacchi i biscotti con la frequenza p (ossia questa è la probabilità che un biscotto sia bruciacchiato) e che venda i biscotti in confezioni da n pezzi. Qual è la probabilità che in una confezione il numero N dei biscotti bruciacchiati sia k?
Se n = 6 e p = 1/8 la probabilitŕ che esattamente i primi 4 biscotti siano bruciacchiati è (1/8)·(1/8)·(1/8)·(1/8)·(7/8)·(7/8) = (1/8)4·(7/8)2. Questo valore dobbiamo moltiplicarlo per i possibili sottoinsiemi di 4 elementi che possono essere formati da un insieme di 6 elementi:
C(6,4) = (6·5·4·3)/(4·3·2·1) = 6/4·5/3·4/2·3/1 = 6·5/2/1 = 3·5 = 15
Dunque, nel nostro caso particolare, la probabilità che vi siano 4 biscotti bruciacchiati è C(6,4)·(1/8)4·(7/8)2 = 15·(1/8)4·(7/8)2 = 0.0028038 = 0.28% (arrotondando). Procedo analogamente per gli altri valori di k.
In generale:
Pr(N = k) = C(n, k) · pk · (1 – p)n–k
Questa legge di distribuzione viene chiamata legge di distribuzione binomiale (o di Bernoulli). Si applica a tutte le situazioni in cui si ripete n volte la prova su una variabile casuale che può assumere solo due valori, in cui p è la probabilità di uno di questi due valori e N è il numero delle volte in cui questo valore esce.
Un altro esempio d'uso: in una certa popolazione di individui adulti di una data regione si sa che una particolare malattia infantile ha colpito in media 1 persona su 10; prese del tutto a caso 1000 persone adulte di quella regione qual č la probabilitŕ che almeno 100 siano state colpita da essa? Il calcolo:
k = 100:1000; sum( choose(1000,k)*(1/10)^k*(9/10)^(1000-k) )*100 # 51.54%
Ecco qualche grafico. Il primo rappresenta la binomiale con p = 0.2 e n = 5. Gli altri rappresentano quelle per p = 0.2 e n = 10, n = 30.

Si noti come all'aumentare di n l'istogramma di distribuzione tende ad assumere una forma simile alla gaussiana. Come mai? La binomiale di ordine n è ottenibile come somma di n termini uguali ad una variabile casuale ad uscite in 0 ed 1 (ad esempio, nel caso dei 6 biscotti, è la somma di 6 variabili ad uscite in 0 od 1).
Si può dimostrare che se Ui (i intero positivo) sono n variabili casuali (numeriche)
indipendenti con la stessa legge di distribuzione, allora
al crescere di n la variabile casuale
| ( | (x1– m)2 + (x2– m)2 + … (xn– m)2 | ) | 1/2 |
| ——————————————— | |||
| n−1 |
Ovvero,
al crescere di n la variabile casuale
| ( | (x1– m)2 + (x2– m)2 + … (xn– m)2 | ) | 1/2 |
| ——————————————— | |||
| n·(n−1) |
Il primo "σ" è la deviazione standard (sd nella versione del software
R richiamata all'inizio), il secondo è la deviazione standard della media
(sdM, ovveri
Sotto a sinistra il grafico della gaussiana e il richiamo della sua definizione e di alcune sue proprietà.
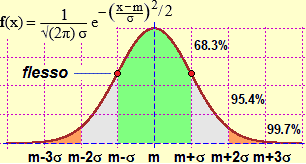
La proprietŕ ora richiamata costituisce il teorema limite centrale, che intreccia la probabilitŕ e la statistica ed č alla base di tutte le applicazioni di quest'area della matematica. Un primo aspetto è che il fatto che la media di pressoché tutti i fenomeni casuali, comunque siano distribuiti, abbia andamento gaussiano ci consente di stimare la precisone della media ottenuta o, nel caso si stia simulando un fenomeno, la precisone della probabilitŕ di esso.
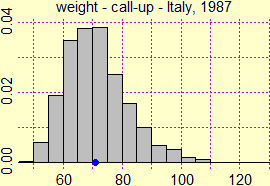
Un esempio. Sopra a destra è riprodotto l'istogramma di distribuzione dei
pesi (in kg) registrati in Italia al primo contingente delle visite di leva nel 1987 (4170 visite), che, come è evidente, non ha andamento gaussiano
(al di lŕ di ciň che viene fatto credere spesso agli alunni, la distribuzione gaussiana non si presenta spesso in natura:
si distribuiscono grosso modo in tale maniera le altezze delle persone adulte di un dato sesso appartenti ad un certo gruppo razziale,
le lunghezze di una certa specie di pesci, …, una durata temporale registrata a mano da diverse persone con dei cronometri di precisione, …).
Il peso medio è di 70.977 kg. Se in quello stesso anno avessimo preso altri campioni di giovani maschi di quell'etŕ, ciascuno di 4170 persone,
avremmo ottenuto valori medi diversi. Che cosa devo prendere come peso medio dell'intero insieme di giovani?
I calcoli con R, e poi le spiegazioni:
source("http://macosa.dima.unige.it/r.R")
pesi = scan("http://macosa.dima.unige.it/R/weight.txt")
# Read 4170 items
# I pesi sono "troncati" agli interi, per avere valutazioni corrette aggiungo 1/2
pesi = pesi+1/2; mean(pesi)
# 70.97674
hist(pesi, col="grey") # Ho ottenuto l'istogramma, che vedo non ha andamento simmetrico
sdM(pesi) # Ho calcolato la deviazione standard dalla media
# 0.1630916
# Al 68.3% il peso medio sta tra:
mean(pesi)-sdM(pesi); mean(pesi)+sdM(pesi)
# 70.81365 71.13983
# Al 99.7% il peso medio sta tra:
mean(pesi)-sdM(pesi)*3; mean(pesi)+sdM(pesi)*3
# 70.48746 71.46601
I dati erano N = 4170 e la loro media č m = 70.977. Se ripetessi la prova con N altri individui
della stessa categoria presi a caso otterei altri valori della media che comunque
si distribuirebbero secondo una gaussianacon σ = sd/√N = sdM = 0.163.
Posso concludere che al 68.3%, nel 1987, il peso medio (in kg) di un
italiano maschio della stessa etŕ è 70.977±0.163, al 99.7% (ossia con pratica certezza) è
70.977±0.163·3 = 70.977±0.489, ovvero 71±0.5 kg.
Altro esempio: se con un apparato misuratore ad alta sensibilitŕ ottengono le 7 misure (in una data unitŕ di misura) 7.3, 7.1, 7.2, 6.9, 7.2, 7.3, 7.4, posso calcolarne la media (7.2000…), la deviazione standard (0.061721) e il suo triplo (0.185), e concludere che il "valore vero" della misura al 99.7% č 7.200±0.185.
misure = c( 7.3, 7.1, 7.2, 6.9, 7.2, 7.3, 7.4 ) mean(misure); sdM(misure); sdM(misure)*3 # 7.2 0.06172134 0.185164 mean(misure)-sdM(misure)*3; mean(misure)+sdM(misure)*3 # 7.014836 7.385164
Anche per valutare gli esiti di una simulazione si usa
questa proprietŕ (qui trovi qualche esempio). Vediamo che cosa si puň ottenere:
Qual è la probabilitŕ (estraendo 10 carte da un mazzo da 40) di ottenere almeno un tris (cioč 3 o 4 carte dello stesso valore)?
Si puň ottenere, con 107 prove, al 99.7%, (38.436±0.047)% ovvero (38.44±0.05)%.