Affrontiamo l'esercizio con degli script, poi vedremo come farlo con R.
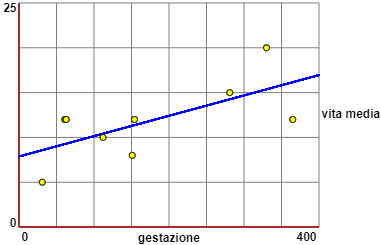
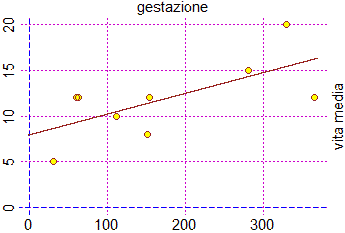
L'immagine a destra è stata ottenuta con questo script,
avendo calcolato la retta di regressione y = 0.0227*x+7.873 (vedi sotto) con questo altro script.
Ovviamente la retta di regressione ottenuta è solo indicativa; possiamo concludere solo che la relazione tendenzialmente è crescente.
Per altri commenti:
 Correlazione tra variabili casuali neGli Oggetti Matematici.
Correlazione tra variabili casuali neGli Oggetti Matematici.