
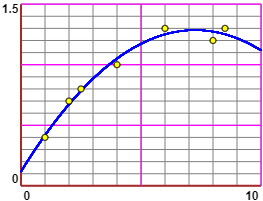
x: 1, 2, 2.5, 4, 6, 8, 8.5
y: 0.4,0.7,0.8,1.0,1.3,1.2,1.3
y = -0.02218173747387673*x^2+0.321872306582579*x+0.11790611648506874
Da rilevamenti sperimentali relativi a due grandezze x ed y, che sappiamo
essere legate da una funzione polinomiale di 2º grado,
otteniamo i seguenti valori:
x: 1, 2, 2.5, 4, 6, 8, 8.5
y: 0.4, 0.7, 0.8, 1.0, 1.3, 1.2, 1.3.
Delle x la precisione è trascurabile
(è dell'ordine di grandezza dei centesimi); le y invece sono
state ottenute con uno strumento ad alta sensiblità: ai valori
riportati non sappiamo associare una precisione. Usa dell'opportuno
software per determinare la funzione polinomiale che "meglio approssima"
i dati.
Utlizziamo un apposito script:
| Arrotondando, la funzione è x → -0.02218*x² + 0.3219*x + 0.1129.
Rappresento graficamente la funzione con questo script. |
 |
Vedi la voce  correlazione tra variabili casuali:
correlazione tra variabili casuali:
Con R:
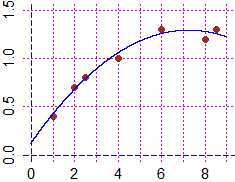
x <- c(1,2,2.5,4,6,8,8.5); y <- c(0.4,0.7,0.8,1.0,1.3,1.2,1.3)
plot(x,y)
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
a <- sum(x); b <- sum(x^2); c <- sum(x^3); d <- sum(x^4)
e <- sum(y); f <- sum(x*y); g <- sum(x*x*y)
ma <- matrix(data = c(n,a,b,a,b,c,b,c,d), nrow = 3, ncol = 3)
noti <- matrix(data = c(e,f,g), nrow = 3, ncol = 1)
S <- solve(ma,noti); S
# [,1]
# [1,] -0.12309735
# [2,] 0.43869241
# [3,] -0.03308057
F <- function(x) S[1]+S[2]*x+S[3]*x^2
curve(F,add=TRUE,col="blue")
# x -> -0.123+0.439*x-0.0331*x^2
#
# Ovvero:
source("http://macosa.dima.unige.it/r.R")
x=c(1,2,2.5,4,6,8,8.5); y=c(0.4,0.7,0.8,1.0,1.3,1.2,1.3)
regression2(x,y)
# -0.0222 * x^2 + 0.322 * x + 0.118
f = function(x) -0.0222 * x^2 + 0.322 * x + 0.118
Plane(0,9, 0,1.5); POINT(x,y, "brown")
graph1(f, 0,9, "blue")