
| In un particolare ambito si vuole valutare la relazione tra due grandezze (misurate in opportune unità) al fine di individuare una eventuale relazione lineare tra di esse. Supponiamo che si ottengano i dati che vengono generati usando, in R, le seguenti istruzioni. Studia il problema usando i concetti di retta di regressione e di correlazione lineare. Cerca eventualmente qui come implementare questi concetti in R. | |
 | Supponiamo di ottenere dati come quelli rappresentati nella figura. Ecco che cosa potrei ottenere: |
cor(x,y) [1] 0.9928424 # Ho trovato che c'e' un alto coefficiente di correlazione regression1(x,y) 0.4984 * x + 33.51 # La retta di regressione è y = 0.4984 * x + 33.51 f = function(x) 0.4984 * x + 33.51; graph1(f, 100,1100, "seagreen") |
Il valore alto del coefficiente di correlazione (0.993) è influenzato dal fatto che i dati
sono pochi? (se i dati fossero 2 ci sarebbe un'unica retta che passa per essi; se i dati fossero 3 sarebbe abbastanza
facile che fossero quasi allineati).
Per avere una valutazione che tenga conto della quantitŕ dei dati occorre battere:
cor.test(x,y, conf.level = 0.95) 95 percent confidence interval: 0.961709 0.998829
L'intervallo di confidenza al 95% è l'intervallo in cui, con la probabilità del 95%, cade il valore esatto del coefficiente di correlazione. In definitiva per i nostri dati c'è una altissima probabilità che siano linearmente correlati e, con probabilità del 95%, il coeff. di correlazione è circa tra 0.962 e 0.999.
Il docente può usare esercizi come questo anche per compiti in classe, facendo mettere ai vari alunni, in testa al file, set.seed(N) con N numeri interi diversi.
Per altri commenti:
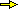 Correlazione tra variabili casuali neGli Oggetti Matematici
e questo esercizio.
Correlazione tra variabili casuali neGli Oggetti Matematici
e questo esercizio.