Per studiare il legame tra la temperatura ambientale e il numero
di parti difettose che escono da una particolare linea di produzione
un'azienda registra per circa una ventina di giorni le temperature
massime e la quantità dei difetti riscontrati, ottenendo
i dati allegati
(caricabili in fomato testo).
Traccia il relativo diagramma di dispersione, calcola il coefficiente di correlazione
lineare e valuta se puoi concludere qualcosa circa la relazione
tra temperatura e parti difettose prodotte.

x: 24.2,22.7,30.5,28.6,25.5,32,28.6,26.5,25.3,26,24.4,24.8,20.6,25.1,21.4,23.7,23.9,25.2,27.4,28.3,28.8,26.6
y: 25,31,36,33,19,24,27,25,16,14,22,23,20,25,25,23,27,30,33,32,35,24
y = 0.8810414328482716*x + 3.0326490515091074
correlation coefficient: 0.4189439540499162
Con questo script ottengo le uscite precedenti.
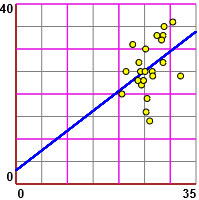
Il grafico a lato è stato ottenuto con questo script,
in cui oltre ai punti ho rappresentato la retta di regressione.
Come coefficiente di correlazione ho ottenuto
0.419.
Risulta esserci una debole correlazione positiva tra le due grandezze, che andrebbe ulteriormente esplorata ed eventualmente confermata da altri dati.
Per avere una valutazione che tenga conto anche della quantità dei dati posso calcolare il p-value
(vedi qui) utilizzando il software
online WolframAlpha. Vediamo come.
correlation test [(24.2,22.7,...,26.6),(25,31,...,24)]
correlation: 0.418944 p-value: 0.0522986 = 5.22986%
Ho ottenuto p-value > 5%, a conferma della scorrelazione.
|
|  |
Invece degli script precedenti potevo impiegare R, ottenendo esiti
come i seguenti:
readLines("http://macosa.dima.unige.it/om/esr/pro/difetti.txt",n=3)
# "'temperatura max, parti difettose"
# "24.2;25"
# "22.7;31"
## Capisco come devo caricare i dati:
dati= read.table("http://macosa.dima.unige.it/om/esr/pro/difetti.txt",header=FALSE,skip=1,sep =";")
str(dati) # esamino velocemente i dati
# 'data.frame': 22 obs. of 2 variables:
# $ V1: num 24.2 22.7 30.5 28.6 25.5 32 28.6 26.5 25.3 26 ...
# $ V2: int 25 31 36 33 19 24 27 25 16 14 ...
x=dati$V1; y=dati$V2; range(x); range(y)
# 20.6 32.0 14 36
BF=3; HF=2.5
Plane(0,35, 0,40); POINT(x,y, "brown")
regression1(x,y)
# Traccio la retta di regressione (senza imporre che passi per (0,0):
# non avrebbe senso in quanto lo 0 assoluto della temperatura non è 0°)
regression1(x,y)
# 0.881 * x + 3.033
f = function(x) 0.881 * x + 3.033; graph1(f, 0,35, "seagreen")
cor(x,y)
# 0.418944
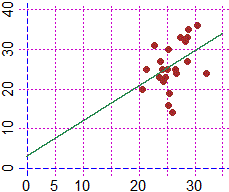 |
Dall'esame dei dati risulta esserci
una debole correlazione positiva tra le due grandezze, che andrebbe
ulteriormente esplorata ed eventualmente confermata da altri dati.
Nota.
Per avere una valutazione che tenga conto della quantitŕ dei dati occorre battere:
cor.test(x,y, conf.level=0.90)
# 90 percent confidence interval:
# 0.06894562 0.67711431
Come si vede, si ottiene un amplissimo intervallo di confidenza, che include quasi lo 0.
|
Per altri commenti:
 Correlazione tra variabili casuali
neGli Oggetti Matematici.
Correlazione tra variabili casuali
neGli Oggetti Matematici.