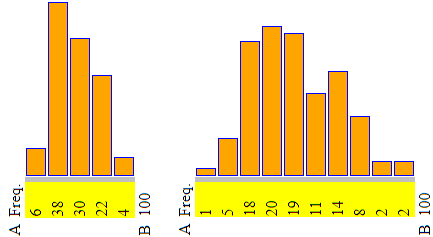
Allegato, qui, trovi un file contenente i pesi di 100 uova estratte a caso tra quelle prodotte giornalmente da galline di razza livornese di un'azienda avicola (i dati, reali, sono tratti dal volume "Che cos'è la statistica" di U.Pampallona e L. Ragusa Gilli). Supponiamo che le uova vengano vendute, a seconda del peso, e che i prezzi, all'ingrosso, siano di 9.8, 11, 13.1, 13.9 e 14.5 centesimi di euro per, in ordine, le uova che pesano meno 50 g, da 50 a 55 g esclusi, da 55 a 60 g esclusi, da 60 a 65 g esclusi, oltre 65 g. Rappresenta, con un opportuno istogramma, il peso delle uova, determinane peso medio e quartili e stima l'incasso in un giorno in cui siano prodotte e vendute esattamente 10 mila uova.
Ecco istogrammi e calcoli relativi al peso delle uova realizzati con lo script histogram:
Usando la classificazione sopra ottenuta e facendo il calcoli a mano o usando questa calcolatrice:

ottengo che l'incasso è di circa 1230 €. Il "circa" è dovuto al fatto che non sappiamo esattamente come si sono distribuite le 10 mila uova vendute nelle varie classi.
Per altri commenti:  distribuzione, valori medi (2) e
percentili neGli Oggetti Matematici.
distribuzione, valori medi (2) e
percentili neGli Oggetti Matematici.
| Osserviamo che i pesi delle uova, così come, ad esempio, i pesi della popolazione umana di un dato sesso, non hanno andamento simmetrico, come si potrebbe vedere bene raccogliendo molte più misure. |  |
Ecco istogramma media e quartili, e i comandi con cui con R, possono essere ottenuti (ipotizziamo di aver copiato i dati nel file "uova.txt"; avremmo pouto leggerli anche direttamente da rete oppure averli opportunamente copiati in R):
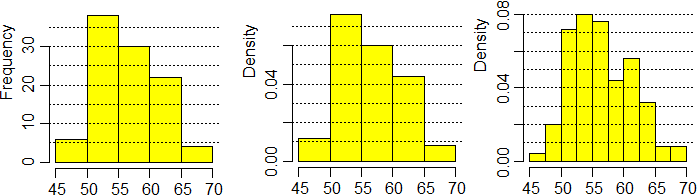
dati <- scan("uova.txt", skip=1)
hist(dati,right=FALSE,col="yellow")
abline(h=seq(5,40,5),lty=3)
## Ne rappresento anche le densit` di frequenza, con due scale:
dev.new(); hist(dati,freq=FALSE,right=FALSE,col="yellow")
abline(h=seq(0.01,0.08,0.01),lty=3)
dev.new(); hist(dati,seq(45,70,2.5),right=FALSE,freq=FALSE,col="yellow")
abline(h=seq(0.01,0.1,0.01),lty=3)
## Peso medio e quartili:
summary(dati)
# Min. 1st Qu. Median Mean 3rd Qu. Max.
# 47.19 52.72 55.34 56.27 60.06 69.68
L'incasso calcolato con R.
prezzi <- c(9.8,11,13.1,13.9,14.5)/100 ## I valori numerici corrispondenti all'istogramma: hist(dati,right=FALSE,plot=FALSE) # $counts # 6 38 30 22 4 # $density # 0.012 0.076 0.060 0.044 0.008 # ... ## Utilizzo la numerosità delle classi per determinare le frequenze ## relative e moltiplicarle per i prezzi e il numero totale dei dati sum( hist(dati,right=FALSE,plot=FALSE)$counts/length(dati)*prezzi*1e4 ) # 1233.6