| Con un sondaggio si chiede a 90 studenti di più classi di stimare il tempo giornaliero dedicato (mediamente) allo studio a casa. Si ottengono come risposte (in minuti): | ||||||||||
| nº studenti | tempo | nº studenti | tempo | nº studenti | tempo | nº studenti | tempo | |||
| 1 | 45 | 9 | 90 | 19 | 150 | 1 | 190 | |||
| 3 | 75 | 29 | 120 | 6 | 160 | 2 | 210 | |||
| 2 | 80 | 7 | 135 | 10 | 180 | 1 | 240 | |||
| 1) Qual è il tempo medio dedicato allo studio che si ottiene con questa indagine? | ||||||||||
| 2) Quanto vale il tempo mediano? | ||||||||||
| 3) Classifica i tempi medi negli intervalli di eguale ampiezza: [0, 30), [30, 60), … e traccia il corrispondente istogramma di distribuzione. Qual è / quali sono le classi modali? | ||||||||||
| 4) Classifica i tempi medi negli intervalli di eguale ampiezza: [0, 50), [50, 100), … e traccia il corrispondente istogramma di distribuzione. Qual è / quali sono le classi modali? | ||||||||||
| 5)
Chi ha fatto il sondaggio fa la convenzione di considerare "normali" i tempi di studio compresi
tra il 10° e il 90° percentile e di chiamare "secchione" chi studia per un tempo superiore
al "normale" e "fannullone" che studia per un tempo inferiore al "normale". Completa quanto segue: • il primo 10% di 90 dati è costituito dai primi 9 dati. • il primo 90% di 90 dati è costituito dai primi … dati. • quindi il 10° percentile è il valore del 9° dato, cioè … • e il 90° percentile è il valore del … dato, cioè … • tempi da "fannulloni": [0, … ) "normali": [ … , … ] da "secchioni": ( … , ∞). | ||||||||||
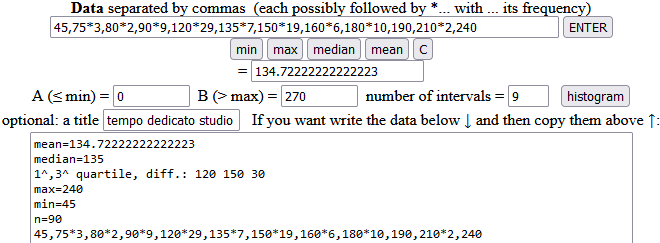
Ecco sotto calcoli e rappresentazioni ottenute con lo script histogram. Il tempo medio è 134.7…, che arrotondo a 135; in questo caso coincide, approssimativamente, col tempo mediano (il valore del 45° dato). Il primo 90% è costituito da primi 81 dati, il 10° percentile è 90, il 90° è 180; i tempi "normali", per chi ha elaborato i dati del sondaggio, sono quelli da 90 a 180 minuti.
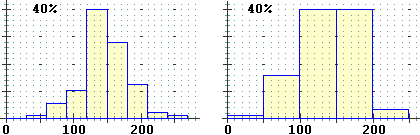
Con questi input ottengo l'istogramma sotto a sinistra:
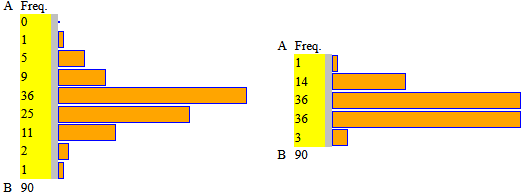
Con gli stessi input, modificando questi comandi:

ottengo l'istogramma sopra a destra.
Per altri commenti: 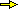 valori medi (2)
neGli Oggetti Matematici.
valori medi (2)
neGli Oggetti Matematici.
Ecco sotto calcoli e rappresentazioni ottenute col
programma  Stat di MaCoSa.
Stat di MaCoSa.
I dati caricati e analizzati con R (il primo istogramma è stato tracciato lasciando al programma la scelta degli intervalli, il 2° e il 3° sono stati tracciati mettendo gli intervalli richiesti, il 4° e il 5° specificando che sulla scala verticale si vuole l'indicazione delle densità di frequenza).
dati <- c(45,rep(75,times=3),80,80,rep(90,times=9),rep(120,times=29), rep(135,times=7),rep(150,times=19),rep(160,times=6),rep(180,times=10), 190,210,210,240) summary(dati) Min. 1st Qu. Median Mean 3rd Qu. Max. 45.0 120.0 135.0 134.7 150.0 240.0 hist(dati,right=FALSE) hist(dati,seq(0,270,30),right=FALSE) hist(dati,seq(0,250,50),right=FALSE) hist(dati,seq(0,250,50),right=FALSE,probability=TRUE) hist(dati,seq(0,270,30),right=FALSE,probability=TRUE)
45,1 75,3 80,2 90,9 120,29 135,7 150,19 160,6 180,10 190,1 210,2 240,1 | 90 dati in 12 righe min,max: 45,240 media: 134.722222 mediana: 135 10% :90 90% :180 |
 |