es. altri programmi
RUN
S T A T
Esempi (1 variabile) Esempi (più variabili) Help
sintesi comandi
[per riferimenti teorici vedi Oggetti Matematici (voci: distrib., val.med., percentili, indici di pos. e dispers., leggi di distrib., limti in prob., sistemi di var. casuali, correlaz.)]
E s e m p i (in 1 variabile)
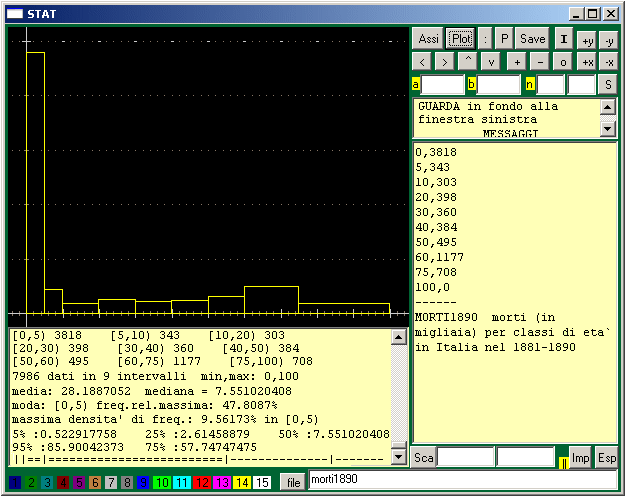
## Dati classificati in intervalli (di ampiezza diversa o uguale)
I dati sono battuti nel formato che si vede nella finestra scorrevole a destra.
"---" indica che la parte successiva non deve essere letta.
Gli output relativi ai percentili e ai box-plot sono stati ottenuti cliccando [S].
L'istogramma e' stato ottenuto cliccando [Plot].
|
|
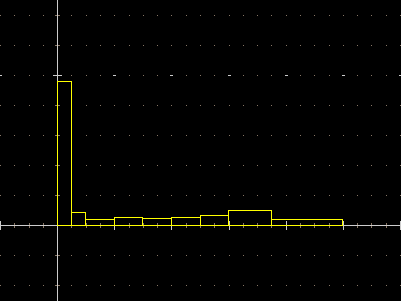 | Ecco come appare cambiando la scala con un clic su [Sca] con nei relativi box: |
legenda: ----|----|====|====|----|----
min 5% 25% 50% 75% 95% max
0 100
||==|=========================|--------------|------- 1890
3 7 57
---------------------|-------------|=====|====|----|- 1990
66 78
[il 50% centrale delle età di morte si è concentrato e spostato a destra; l'età mediana di morte si è spostata da 7 anni a 78 anni; prima il 25% dei nati non superava i 3 anni, un secolo dopo questa soglia si è spostata a 66 anni]
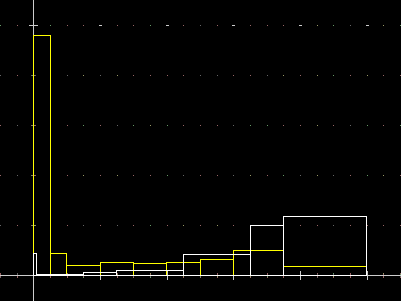 | Oppure, fatto il nuovo istogramma, con un doppio clic su [P] c'è la possibilità si sovrapporlo al precedente. |
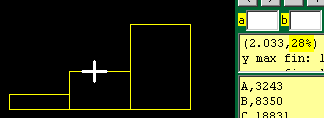  | Cliccando ripetutamente [Plot] si ottengono istogramma e diagramma a settori circolari. Se non si traccia il reticolato i valori (cliccando [Assi] si cambia la visualizzazione di assi e reticolato) possono essere individuati cliccando sulla finestra grafica e osservando le coordinate che appaiono nella finestra in alto a destra. |
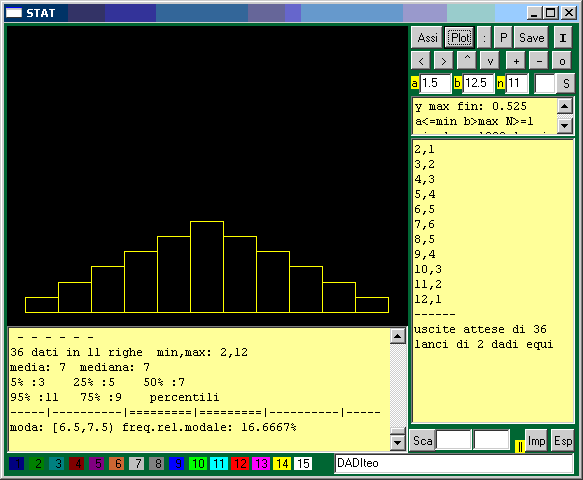 |
 | Per tracciare l'istogramma occorre specificare l'intervallo [a,b) da prendere come base e il numero degli intervallini in cui ripartirlo. Qui si sono scelti 11 intervallini e si è preso [a,b) = [1.5,12.5) in modo che ogni intervallino fosse centrato su una delle possibili uscite; si poteva scegliere anche [2,13). |
 | Se prima di cliccare [Plot] si mette '%' nel box vicino a [S] si ottiene (nella finestra sotto a quella grafica) la stampa delle frequenze percentuali corrispondenti all'istogramma; nel caso della distribuzione teorica del lancio di due dadi si ha: 2.7778 5.5556 8.3333 11.111 13.889 16.667 13.888 11.111 8.3333 5.5556 2.7778 |
A destra è raffigurato l'istogramma sperimentale di 1000 uscite di RND+RND (RND: variabile casuale con distribuzione uniforme in [0,1)). Cliccando [Plot] con N nel box a sinistra di [S] si fa sì che l'istogramma sia normalizzato (le y non sono le frequenze, ma le densità di frequenza, in modo che l'area totale sia 1). In questo modo l'istogramma sperimentale è confrontabile con il grafico della funzione densità teorica. La cosa può essere fatta esportando il grafico in modo che sia rappresentabile col programma Poligon, oppure salvando l'immagine come BMP e sovrapponendola poi con quella analoga ottenuta per la funzione densità (scegliendo opportunamente le scale), oppure, come è stato fatto a lato, importando il grafico della funzione (registrato come file GFU): vedi l'HELP. |
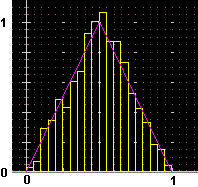  |
| Se prima di cliccare [Plot] si mette '/' nel box vicino a [S] si ottiene invece di un istogramma una poligonale di distribuzione: vedi la figura sotto al centro, riferita ai dati rappresentati a sinistra mediante un istogramma; a destra è raffigurata l'unione delle due figure ottenuta mediante un doppio clic su [P] (se esse sono state tracciate una dopo l'altra). |
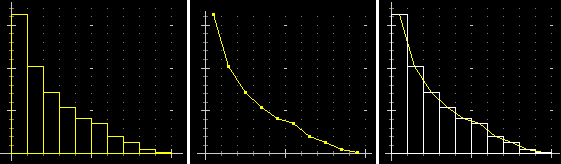 |
## Per importare un file di dati numerici, registrato da qualche parte con estensione STF e scritto nei modi sopra visti, oltre che usare [Imp], puoi scriverne percorso+nome e cliccare [I]. Se vuoi puoi aggiungere ulteriori dati, o concatenare più file. Volendo puoi scrivere un elenco di file con un apice ' in testa e attivare man mano quello che vuoi analizzare togliendo l'apice davanti ad esso. |  |
 | Per inserire Percordo+NomeFile nel box di [Imp] puoi usare il bottone [file], selezionare il file e cliccare [Apri]. La finestra di dialogo che si apre puoi usarla anche per [Esp]. Puoi pure usarla per esaminare o modificare un file: basta che clicchi sul suo nome (col pulsante destro) e selezioni Apri o Apri con dal menu a tendina che si apre. |
## I box-plot delle altezze di uno stesso campione di ragazzi in due diverse età (i file, in realtà, sono stati generati con una simulazione mediante il programma Fa_Rnd.Bas). | |
min,max: 135, 159 5% :139 25% :144 50% :148 95% :157 75% :152 --------|----------|========|=======|----------|----- min,max: 158,189 5% :163 25% :170 50% :175 95% :186 75% :179 ---------|----------|=======|=======|----------|----- | |
Se si preme [S] con 130 e 200 nei box A e B e con S nel box a sinistra di [S], si ottengono i box-plot riferiti all'intervallo [130,200], il che consente di confrontare l'evoluzione della posizione e della dispersione dei dati. | |
[130 200]
---|---|=|==|---|--
----|----|==|===|---|--- | 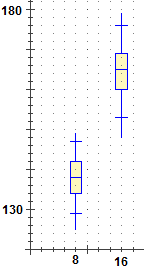 |
I valori di min, max e dei percentili calcolati da Stat possono essere utilizzati anche per tracciare i box-plot mediante
il programma Poligon (tra i file per Poligon trovi il demo boxplot.dm che esemplifica come fare). Ecco a destra che cosa
si può ottenere per i dati precedenti, nell'ipotesi che le età dei due gruppi di ragazzi siano 8 e 16 anni. | |
ba .616 ca .052 cb .577 da .129 db .046 dc .066 ea .285 eb .309 ec-.107 ed-.129 fa-.211 fb-.153 fc .224 fd .043 fe-.709 ga-.203 gb-.166 gc .224 gd .201 ge-.710 gf .783 ha-.063 hb-.141 hc .007 hd-.120 he-.105 hf .089 hg-.004
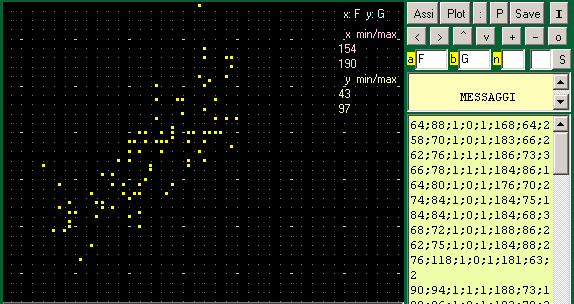
Si vede che il sesso e' fortemente correlato (negativamente in quanto abbiamo codificato il sesso femminile con un numero maggiore) con altezza (F) e peso (G). E' poi abbastanza correlato col battito (le femmine hanno battito piu' alto). L'essere fumatore (D) non manifesta particolari correlazioni. Clicco [S] con MO mel box a sinistra ottengo i coefficienti Ordinati:
gf .783 ba .616 cb .577 eb .309 ea .285 gc .224 fc .224 gd .201 da .129 hf .089 dc .066 ca .052 db .046 fd .043 hc .007 hg-.004 ha-.063 he-.105 ec-.107 hd-.120 ed-.129 hb-.141 fb-.153 gb-.166 ga-.203 fa-.211 fe-.709 ge-.710
Troviamo che le piu' correlate (positivamente) sono altezza e sesso e (negativamente) peso e sesso (le femmine tendenzialmente pesano meno).
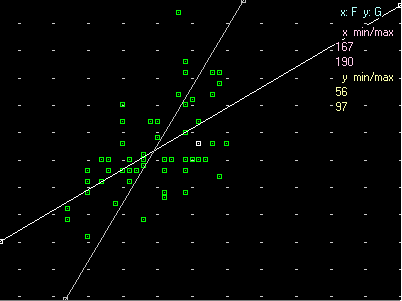
Per una conferma, con [Plot] avendo messo F e G nei box A e B, traccio il diagramma di dispersione:
[Nota: la finestra grafica ha Altezza/Larghezza = 3:4]
 |
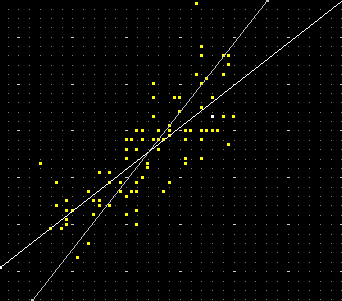
| Se aggiungo RXY ottengo anche la retta di regressione di y in funzione di x. Se voglio ottenere entrambte le rette metto RXYX. Ottengo la figura seguente, che viene tracciata in una scala tale che l'ampiezza dell'angolo formato dalle due rette di regressione decresce con il coefficiente di correlazione (0°: correlazione 1 o -1, 90°: correlazione 0) |
 |
|
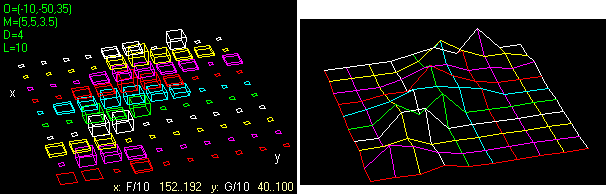
Quelle che seguono sono invece delle rappresentazioni della distribuzione di (altezza, peso) ottenute con [Plot] avendo messo F/10 e G/10 nei box A e B e 3D nel box S, dando un Nome al file e aprendolo poi col programma TreDim (il file Nome corrisponde all'istogramma, il file NomeP, generato automaticamente, corrisponde alla rappresentazione poliedrica a destra; per aprire il file da TreDim individua con [file]; l'indirizzo del file viene caricato nella finestra di input; poi clicca [I]). Il punto di vista può essere modificato dal programma TreDim, così come l'altezza delle colonne (basta, per es., mettere il comando z=0.5z per dimezzarla o z=3z per triplicarla). |
 |
ba .607 ca-.015 cb .482 da .058 db-.016 dc-.031 ea - eb - ec - ed - fa .045 fb .056 fc .161 fd .000 fe - ga-.095 gb-.066 gc .182 gd .175 ge - gf .590 ha .045 hb-.111 hc .012 hd-.180 he - hf .053 hg-.131
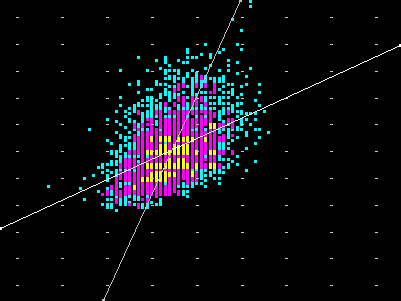
| Una conferma col diagramma di dispersione: |
 |
 |
Se voglio analizzare solo la variabile casuale A (battito cardiaco), dopo aver eliminato i filtri, metto 'A' sia nel box A che nel box B e clicco [S]: ottengo tutte le statistiche relative a essa:
Analisi del campo A
92 dati in 92 righe min,max: 48,100
media: 72.8695652 mediana: 70 [o 72]
5% :58 25% :64 50% :70
95% :92 75% :80 percentili
----------|-----|=====|=========|-----------|--------
sc.quad.med.= 10.948712 varianza = 119.87429
sqm.statistico= 11.008705 var.stat.= 121.19159
sqm.stat.della media=1.1477369 var.st.med=1.3172999
coeff.variazione = 15.0251%
coeff.asimmetria = 0.39088
Se poi aziono [Plot] (impostando intervallo e numero di classi) possono ottenerne l'istogramma di distribuzione:
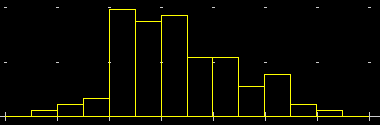
moda: [60,65) freq.rel.modale: 19.5652%
Se voglio la matrice di correlazione solo tra battiti, altezza e peso posso cancellare (temporaneamente) gli altri campi cliccando [S] con FC a sinistra e H nel box N, in modo da eliminare 'attività fisica'. Faccio lo stesso con B nel box N, in modo da eliminare 'battiti dopo'. Ora la colonna B è 'fatta corsa'. Rifaccio lo stesso ed elimino 'fatta corsa'. E allo stesso modo elimino 'fumatore' e 'sesso'. Poi clicco [S] con M a sinistra e ottengo:
ba -.211
ca -.203 cb .783
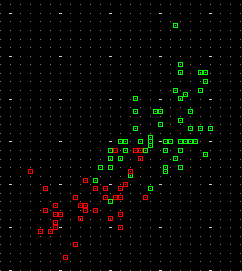
Se i dati sono molti può essere utile evidenziare con colori diversi quelli delle zone
in cui cadono con maggiore frequenza mettendo una "C" nel box N prima di cliccare {Plot}.
Ecco che cosa si ottiene nel caso del diagramma Altezza-Peso di un grande campione di maschi ventenni:
- - - - - - - - -
Nel caso di un sistema di variabili casuali X,Y in cui so che alla uscita di X uguale a 0 deve corrispondere l'uscita di Y uguale a 0 non ha molto senso porsi il problema di individuare tanto la retta di regressione y=a*x+b quanto la retta di regressione y=a*x (con a che minimizza i quadrati degli scarti tra gli Yi e gli a*Xi) vincolata a passare per (0,0). Occorre cliccare [Plot] con RXYO a sinistra di [S]. Ecco che cosa si ottiene nel caso delle quattro coppie di dati sotto riprodotte (il programma calcola anche l'intervallo di confidenza al 95% per a)
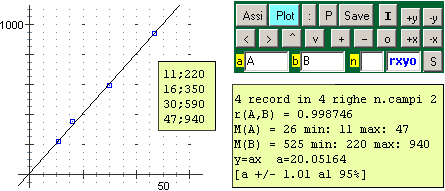
- - - - - - - - -
Supponiamo, ora, di aver caricato dei dati omogenei, ad esempio i voti degli alunni di una classe nelle 8 prove scritte che un insegnante utilizza per assegnare il voto di "scritto" finale:
4;6;5;7;6;4;6;7
6;6;7;7;5;6;7;6
5;7;6;7;6;7;5;7
7;6;8;9;7;7;8;7
5;8;7;6;5;6;7;6
3;5;4;6;5;4;3;5
8;7;6;9;8;7;9;10
...
cliccando [S] con EG a sinistra ottiene sia la stampa delle medie degli 8 campi, ossia i voti medi della classe in ciascuno degli 8 scritti, sia il file MEDIE.GFU (o con altro nome) che li rappresenta in formato Poligon. Ecco i voti medi ottenuti e la loro rappresentazione grafica ottenuta aprendo il file con Poligon:
5.43;6.43;6.14;7.29;6;5.86;6.43;6.86 | 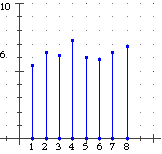 |
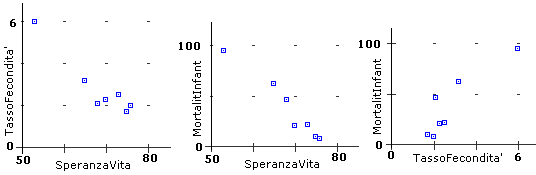
d(1,2)=4.579301 d(1,3)=6.230859 d(1,4)=3.381278 d(1,5)=6.225596 d(1,6)=5.367424 d(1,7)=5.192017 d(2,1)=4.579301 d(2,3)=2.081537 d(2,4)=1.219557 d(2,5)=1.94044 d(2,6)=1.361901 d(2,7)=1.124176 d(3,1)=6.230859 d(3,2)=2.081537 d(3,4)=3.044574 d(3,5)=.3142709 d(3,6)=.8697041 d(3,7)=1.164813 d(4,1)=3.381278 d(4,2)=1.219557 d(4,3)=3.044574 - - - - - - - - -
Se vogliamo studiare una tabella di dati come la seguente:
| 245 | 133 | 201 |
| 97 | 144 | 121 |
# Un altro esempio di tabella a doppia entratata, analogo al precedente, incorporato nel programma e richiamabile con SETTSESS e [Imp] (ricordiamo che se si battessero direttamente i dati nella finestra di input si dovrebbe mettere T nel box di [S] e cliccare [I]): |
 |
Sopra a destra, la distribuzione percentuale ottenuta con % e [S], sotto alcune rappresentazioni grafiche di essa ottenute generando (usando [Plot] con le indicazioni nei box A, B e di [S] illustrate sopra al centro) file da aprire col programma TreDim: |
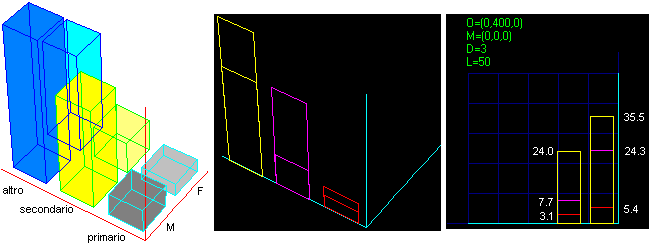 |
La figura a sinistra è stata salvata e modificata con Paint (invertiti i colori, riempite di colore le facce in modo da evidenziare meglio le colonne, aggiunte etichette). Quella al centro è stata ottenuta proiettando l'istogramma sul piano yz dando a TreDim il comando x=0. Quella a destra è stata ottenuta con y=0, si � fatto tracciare un reticolato con maglie ampie 10 e si è opportunamente modificata la direzione dello sguardo. |
1.2 30 10,1230 a,12325 2.3 41,9 20,3280 b,25450 11.25 2.5,2 30,750 c,12760 12 7,3 40,0 -3 12.5 dati in 6 dati classificati: classi dati freq.eventua- 1230 in [10,20) non nu- singoli li dopo ',' ...750 in [30,40) meriche
I dati già classificati in intervalli vanno messi mettendo su ogni riga elemento di separazione e frequenza separati da ','. Dopo l'ultimo elemento di separazione si mette ',' e poi 0 o niente o END. Vedi l�es. nella terza colonna.
Se si tratta di frequenze di modalità non numeriche (abitanti di regioni, ...) le modalità sono indicate con A, B,.. e le frequenze sono messe dopo ','. Vedi es. nell'ultima colonna.
Se disponi di dati dotati di frequenza relativa, devi moltiplicare le frequenze per una stessa costante (ad es. per il totale della popolazione o la numerosità del campione) in modo da ottenere frequenze interpretabili come assolute.
Puoi richiamare esempi più organici su cui allenarti mettendo nella finestra qui sotto i seguenti nomi e premendo [Imp]:
DADITEO
DADI
MORTI1890
MORTI1990
ATTIV1871
ATTIV1971
RND
RND+RND
RND*RND
+12RND
Mettendo i seguenti nomi dopo aver analizzato RND, RND+RND e RND*RND puoi confrontarli con le curve lungo cui tendono a disporsi gli istogrammi sperimentali (normalizzati):
RND.GFU
RNDPIU.GFU
RNDPER.GFU.
Puoi importare anche sequenze di dati (a modalità numeriche) registrati in un FILE nel modo in cui li scriversti nella finestra di input. I file devono avere nome con estensione stf; devi metterne percorso+nome nel box in basso e cliccare [Imp]. Puoi anche mettere percorso+nome nella finestra di input e cliccare [I]; in questo modo, scrivendo su righe successive, puoi importare e concatenare piu' file di dati, ed eventualmente aggiungere uno o piu' dati in altre righe; per non far importare un file basta mettere ' in testa alla riga.
Con [file] puoi aprire una finestra di dialogo che ti consente di cercare un Percorso+NomeFile (se poi clicchi Apri/Open il file viene messo nel riquadro di [Imp/Esp]; altrimenti puoi copiarlo e incollarlo nella finestra di input.
I dati possono essere preceduti da righe di commento inizianti con ' (ciò
non vale per i dati riferiti a modalità non numeriche A,... B,... a meno che essi
non siano importati come file).
- - - - - - - - - -
STATISTICHE MULTIVARIATE.
Le spiegazioni precedenti si riferiscono all'analisi di un'unica grandezza (variabile casuale). Puoi analizzare anche piu' variabili casuali, ad es. peso (kg), altezza (cm) e sesso di un insieme di persone: per ogni individuo batti su una stessa riga separate da un ';' la misura del peso, quella dell'altezza e una codifica numerica del sesso (ad es. 1 per M e 2 per F). Se le stesse informazioni valgono per piu' individui puoi mettere '*N' (con N numero degli individui) in fondo alla riga. Ad es. nel caso di 4 persone di cui 2 con le stesse caratteristiche potrei avere:
57;169;2
68;177;1*2
62;171;2
Per far leggere i dati procedi come nel caso di una sola variabile: clicchi [I], ma dopo aver
messo 'T' (come Tabella) nel box a sinistra di [S]. In alternativa puoi importare un file di testo contenente una tabella di dati scritti in tal modo; il file deve avere estensione tab; puoi anche inserirlo nella finestra di lista, come si e' detto per i file STF.
Per analizzare i dati devi indicare le diverse variabili (ossia i 'campi' dei 'record') con, in ordine, A, B, ..., Z, AA, ..., AZ, come per le colonne di un foglio elettronico. Elaborazioni fattibili:
# [S] con L1 e L2 nei box A e B: correlazione tra le variabili casuali L1 e L2 e retta di regressione (L2 in funzione di L1), con Li scelto tra i nomi dei campi: A, B, C, ... (e indicazione degli intervalli di confidenza al 95%)
# Se si mettono L1=L2 si ha l'analisi statistica della sola variabile casuale indicata. Poi si puo' (scelti intervalli e numero classi) fare anche l'istogramma.
# [S] con M nel box a sinistra stampa la Matrice di correlazione. . Con M- non vengono stampati i nomi delle variabili; con M-- vengono diminuite anche le cifre significative dei coeff. di corr.; con M--- i coeff. sono espressi in decimi. Con MO si ha la stampa Ordinata (da coeff. max a coeff. min).
# [Plot] con L1 e L2 nei box A e B: diagramma di dispersione delle variabili casuali L1 e L2 (Li scelto tra i nomi dei campi: A, B, C, ...); nel box N puoi specificare il codice colore, o mettere la lettera C se vuoi che i punti siano colorati in modo diverso a seconda della densità (colore 11 -> 13 -> 14 per densità crescente)
# Se nel box a sinistra di [S] metti RXY o RYX o RXYX ottieni anche la rappresentazione delle rette di regressione (y in funzione di x, x in funzione di y o entrambe). Con RXYO ottieni quella (di y in funz. di x) vincolata a passare per O. Se invece vi metti A ottieni gli assi principali.
# Se nel box a sinistra di [S] metti 3D e nei box A e B metti L1/M, L2/N e nei box di SCA metti a..b, c..d, puoi invece memorizzare l'istogramma 3D della distribuzione di (L1,L2) con L1/L2 classificato in [a,b)/[c,d) in M/N classi; il nome proposto, cambiabile, e' isto.prs; automaticamente, con una aggiunta di P (istoP.prs), viene memorizzata anche una rappresentazione poliedrica della distribuzione [se non indichi a,c,b,c, essi vengono scelti automaticamente]. Se invece
di 3D metti 3D2, le basi dell'istogramma vengono prese più piccole (in modo da facilitare la
distinzione delle colonne nel caso in cui siano molte).
# [S] con D nel suo box e con h e k nei box A e B: stampa la 'distanza' tra il record nella riga h e il record nella riga k (la distanza e' calcolata con la metrica euclidea interpratando i vari campi come coordinate, dopo aver normalizzato ogni campo in modo da avere media 0 e sqm 1). Record piu' vicini indicano maggiore somiglianza (rispetto alle variabili considerate). Se nei box A e B si mette '-' viene stampata la matrice di tutte le distanze (la cosa porta via molto tempo se i record sono molti: in tal caso conviene prima raggrupparli - vedi sotto).
# [S] con F nel box alla sua sinistra, L (nome di campo) nel box N e due valori h e k nei box A e B filtra i record che hanno il campo L di valore compreso tra h e k inclusi. Si possono operare successivamente piu' filtri (sullo stesso o su campi diversi). In questo modo si possono analizzare sottopopolazioni. Se si riaziona il comando con '-' nel box N tutti i filtri (e raggruppamenti, cancellazioni, aggiunte o sostituzioni - vedi sotto) vengono annullati.
Se lo si aziona con "+" o "++" o ... vengono cancellati i filtri e aggiunti 1 o 2 o ... campi, inizialmente con valore 1 in tutti i record; si tratta di campi in cui (con i comandi descritti sotto) si possono descrivere variabili casuali che sono funzioni di quelle descritte in altri campi.
# [S] con FC nel box alla sua sinistra, L (nome di campo) nel box N cancelli il campo L. Si possono operare successivamente piu' cancellazioni di campi (i nomi dei campi cambiano di conseguenza). Se in N metti L1,L2,... (in ordine alfabetico) vengono eliminati i campo L1,L2,...
# [S] con /n nel box alla sua sinistra, L (nome di campo) nel box N e due valori h e k nei box A e B classifica i dati del campo L nelle n classi ottenute con la partizione dell'intervallo [h,k); per ogni intervallino prende come rappresentante il centro. Si possono operare successive partizioni.
# [S] con '->' nel box alla sua sinistra, due eventuali valori h e k nei box A e B e un valore q nel box N, trasforma in q tutti i dati [tutti quelli che cadono nell'intervallo [h,k) se h e k sono stati inseriti]; se a destra di -> si mette un nome di campo, la trasformazione viene fatta solo per i dati di quel campo; se in N davanti al valore q si mette + o * i dati vengono addizionati/moltiplicati a/per q.
# [S] con *, /, - o + alla sua sinistra e con L1 e L2 nei box A e B moltiplica/sottrae/addiziona in ogni record al valore del campo L1 quello in L2 (se vuoi poi puoi cancellare L2 con FC - vedi sopra).
# [S] con FT alla sua sinistra, con A o B nel box N, e un numero k nel box A Filtra la riga o la colonna k della Tabella,
che possono essere analizzate come singole variabili; con - nel box N e FT in S si annulla il filtro.
# [I] con P nel box di [S] stampa (in fondo alla finestra di lista) i nuovi record dopo filtri, raggruppamenti, …; se metto anche un valore h nel box N stampa solo il singolo record h-esimo
# [S] con % nel box stampa i record con le frequenze espresse in forma percentuale.
# [S] con E nel box a sinistra da' la sequenza dei valori medi delle diverse variabili casuali; se metti 'E-' i valori vengono arrotondati con un numero inferiore di cifre; se metti 'EG' puoi anche memorizzare il file (per Poligon) che rappresenta graficamente la sequenza dei valori medi; il nome proposto, cambiabile, e' medie.gfu.
Puoi richiamare esempi più organici su cui allenarti mettendo nella finestra qui sotto i seguenti nomi e premendo [Imp]:
BATTITO
MONDO
SETTSESS
GAUSS2
- - - - -
I bottoni [S] [Plot] [Sca] [Assi] [P] [I] [:] [o] possono essere azionati scrivendo comandi simili a quelli usati in Poligon nel box di [file] e cliccando [Imp]. Ad esempio per il tracciamento dell'istogramma di un file di dati (univariato) nell'intervallo [20,90) in 18 classi e in forma normalizzata puoi usare:
plot a:20 b:90 n:18 s:n
Se vuoi far apparire una scritta nella finestra grafica a partire dal punto x,y metti:
Puoi anche mettere più comandi in un'unica riga separati da "_".
Essi vengono eseguiti uno dopo
l'altro come se fossero stati azionati in successione.
Se separi due comandi con più "_", ad ogni ulteriore "_" viene effettuata una sosta di un secondo
tra l'esecuzione di un comando e quella dell'altro.
Se hai già scritto una riga di
comandi in qualche documento e l'hai copiata, invece di incollarla nel box File e cliccare [Imp],
puoi più semplicemente cliccare il bottone [CLP].
Il comando CLIP (o un click su [CLP]) consente di azionare
automaticamente una sequenza di comandi (con eventuali SOSTA N, N numero di sec, o AXES, per riportare alla rappresentazione standard di assi e punti, o ---, per l'arresto) di questo tipo memorizzati nel ClipBoard (ossia scritti e poi copiati da un documento di testo o da una stessa finestra di Stat).
I comandi TESTO+ TESTO- TESTO= consentono di ridimensionare i font.
L'uso di CLIP è comodo se devo comunicare ad altri quali comandi impiegare, se devo eseguire lo stesso tipo di comandi su più file, ... Esempio: se copio la seguente sequenza di comandi:
battito
s a:g b:g
s a:40 b:100 s:s
s a:1 b:1 n:e s:f
s a:g b:g
s a:40 b:100 s:s
s n:- s:f
s a:2 b:2 n:e s:f
s a:g b:g
s a:40 b:100 s:s
e poi aziono CLIP [Imp], carico automaticamente il file "battito" (incorporato nel programma) e analizzo e traccio
(sulla stessa porzione 40-100 della retta) i box-plot del campo G (peso) di tutti, di maschi
(ho filtrato i record il cui campo E vale 1) e di femmine (tolgo filtri e rifiltro, questa volta i record il cui campo E vale 2). Alla fine posso copiare dalle uscite i vari box-plot e metterli insieme raggruppati nel modo seguente:
40 100
+------------------------------------------------------+
------|------|=======|===|-------------|---------- MF
--|------|===|=====|-------|---------- M
---|----|==|==|--------| F
+------------------------------------------------------+
40 100
Altro esempio. Con:
battito
s n:+ s:f
s a:1 b:1 n:e s:f
s a:i b:g s:*
s a:i b:f s:/
s a:i b:f s:/
s a:0 b:1 n:*10000 s:->i
s a:i b:i
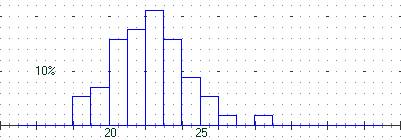
plot a:15 b:35 n:20 s:n
scrivi 19.8,-0.02:20
scrivi 24.8,-0.02:25
scrivi 16,0.095:10%
carico "battito", aggiungo un campo (sarà il campo I, il cui valore in tutti i record all'inizio è 1), filtro i maschi, metto in I il cosiddetto "indice di massa coporea"
pari al peso in kg diviso per il quadrato dell'altezza in m (moltiplico I per il campo G, poi lo divido 2 volte per G e
moltiplico per 10000, il rapporto tra m e cm quadrato), analizzo
questa nuova variabile e ne traccio l'istogramma (normalizzato), con qualche legenda:
Analisi del campo I
57 dati in 57 righe min,max: 18.621386,28.964735
media: 22.2282543 mediana: 22.1526465
sintesi comandi
- - - - -
Puoi impotare/esportare dati da un foglio di calcolo. Per importare in un foglio elettronico un file stf o tab seleziona col comando Apri o Importa (a seconda del prodotto) il nome del file e specifica qual è il delimitatore (virgola o punto e virgola a seconda che sia un stf o un tab). Per salvare da un foglio elettronico un file in formato Stat scegli SalvaCome o Esporta, scegli il formato txt o csv (comma separated values) e scegli il tipo di delimitatore, poi, alla fine, cambia l'estensione del file. Excel è meno flessibile e in genere usa automaticamente la virgola; devi poi tu aprire il file con NotePad/BloccoNote e cambiare eventualmente virgola in punto e virgola.