Come analizzare con R tabelle presenti nel sito dell'ISTAT
Sul sito dell'Istat si possono trovare tabelle
di dati rappresentati in diversi formati. Si tratta di dati classificati, diversi dai dati di tipo
scientifico o dai dati singoli raccolti in indagini di tipo sociale. Vediamo come analizzarli.
Possiamo selezionare i dati, copiarli in un documento di testo ed eventualmente modificarli,
in modo da renderli facilmente leggibili con R. Oppure possiamo provare a rendere un po' più automatica la cosa. Vediamolo con due esempi.
(1) Vediamo un primo esempio (il caso, per comodità di illustrazione, è semplice: in vero si sarebbe fatto prima a incollare e copiare i singoli dati: vedi più avanti).
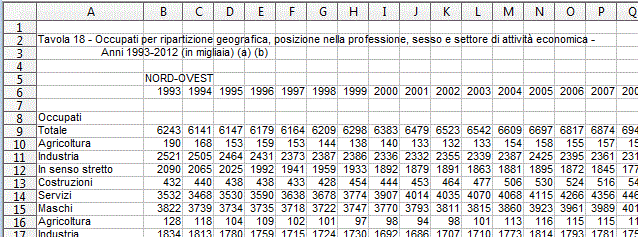
Dal sito dell'Istat cerchiamo una tabella di dati da rappresentare. Le tabelle, in genere, sono in formato leggibile direttamente da OpenOffice e da Excel, o da altri fogli di calcolo, o in formato CSV (vedi), di lettura universale. Scarichiamo la tabella in formato CSV. Ecco un esempio:
La posso visualizzare con OpenOffice, o un altro foglio di calcolo (specificando, dalla finestra di dialogo che si apre, come sono separati i dati, in che formato sono, ...):
Posso, poi, copiare i dati che mi interessano, ad esempio gli occupati nei vari settori in tutta Italia nel 2012 e incollarli in un nuovo foglio di calcolo (preoccupandomi che le varie colonne siano incollate ben allineate):
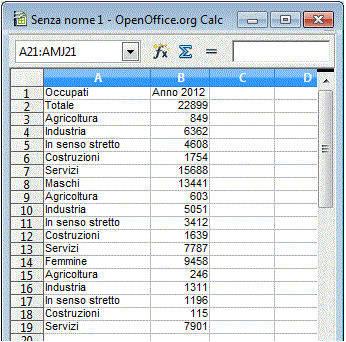
Posso poi salvare la tabella in formato CSV e da qui aprirla e modificarla,
salvandola in formato testo, o copiarla direttamente e incollarla
in un documento di formato testo. Ecco che cosa posso ottenere:
clicca
Modifico il file in modo da esaminare solo quello che mi interessa:
Maschi, Femmine
Agricoltura, 603, 246
Industria, 5051, 1311
Servizi, 7787, 7901
Supponiamo che il file sia salvato col nome "tab18.txt". Lo esamino
con R:
readLines("http://macosa.dima.unige.it/schede/bivar/tab18.txt",n=3)
ottenendo:
"Maschi, Femmine" "Agricoltura, 603, 246" "Industria, 5051, 1311"
Vedo che c'è una riga di intestazioni, che i dati sono separati da ","; non specifico (con "dec="," o dec=".") come è indicato il punto decimale in quanto i dati sono interi:
dati <- read.table("http://macosa.dima.unige.it/schede/bivar/tab18.txt",sep=",",header=TRUE)
str(dati) # controllo che cosa ho caricato
dati # la stampa della tabella
prop.table(dati) # la stampa dei rapporti dati/totale
prop.table(dati)*100 # la stampa della distrib. percentuale
prop.table(dati[,1])*100 # quella dei soli maschi (col.1)
prop.table(dati[,2])*100 # quella delle sole femmine (col.2)
# Per fare l'istogramma 3D carico il seguente file:
source("http://macosa.dima.unige.it/R/isto3D.txt")
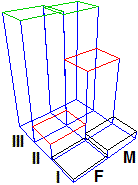
isto3D(dati,-130,30,0)
# volendo aggiungere delle scritte posso ad es. fare:
text(0.2,0.3,"I",col="black",cex=1.5)
text(0.2,0.25,"II",col="red",cex=1.5)
text(0.2,0.2,"III",col="green",cex=1.5)
text(-0.2,-0.4,"F M",col="blue",cex=1.5)
(*1000) Maschi Femmine
Agricoltura 603 246
Industria 5051 1311
Servizi 7787 7901
% Maschi Femmine
Agricoltura 2.6 1.1
Industria 22.1 5.7
Servizi 34.0 34.5
|
% Maschi Agricol. Industria Servizi 4.5 37.6 57.9 % Femmine Agricol. Industria Servizi 2.6 13.9 83.5 |
 |
Per curiosità, come sono state aggiunte le scritte nella figura sopra a destra (la riga # è stata eseguita per trovare le coordinate, moltiplicate per 10; sono state messe le scritte [adj è stato inserito per allineare a destra/sinistra le scritte]; poi il tutto è stato eseguito senza la riga #):
isto3D(dati,-130,30,0) # t <- seq(-10,10,1); text(t/10,0,floor(t)); text(0,t/10,floor(t)) text(-0.23,-0.22,"III",adj=1) text(-0.16,-0.28,"II",adj=1) text(-0.09,-0.36,"I",adj=1) text(0.21,-0.29,"M",adj=0) text(0.1,-0.37,"F",adj=0)
|
Ecco come avrei fatto selezionando e copiando i dati dal foglio di calcolo, incollandoli in un
qualunque editor, separandoli con "," e, quindi, incollandoli, e costruendo direttamente la tabella, in R. Metto i dati in una "array", colonna per colonna, e dò le dimensioni della tabella (n.righe,n.colonne): # I dati e le dimensioni della tabella
T0 <- c(603,5051,7787, 246,1311,7901)
T <- array(T0,dim=c(3,2)); T
[,1] [,2]
[1,] 603 246
[2,] 5051 1311
[3,] 7787 7901
# Se voglio, metto i 3+2 nomi
nomi <- list(c("primario","secondario","altro"),c("M","F"))
T <- array(T0,dim=c(3,2),dimnames=nomi); T
M F
primario 603 246
secondario 5051 1311
altro 7787 7901
# Gli istogrammi di F e M assumendo come totale F+M barplot(T[,1]/sum(T)*100,ylim=c(0,40)) abline(h=axTicks(2),lty=3) dev.new() # ho aperto una nuova finestra grafica barplot(T[,2]/sum(T)*100,ylim=c(0,40)) abline(h=axTicks(2),lty=3) |
 |
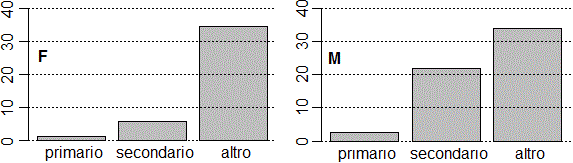
(2) Vediamo un secondo esempio. Osserviamo sul sito dell'Istat una tabella che fornisce, regione per regione, per vari annni, la percentuale degli abitanti con almeno 6 anni che hanno letto almeno un libro nel corso dell'anno (potremmo cercarla mettendo nella casella di ricerca del sito dell'Istat ad esempio "6 anni letto almeno un libro 2013 xls"). Scarichiamo la tabella. Il file è qui: daistat.xls Otteniamo qualcosa di questo genere (riprodotto parzialmente):
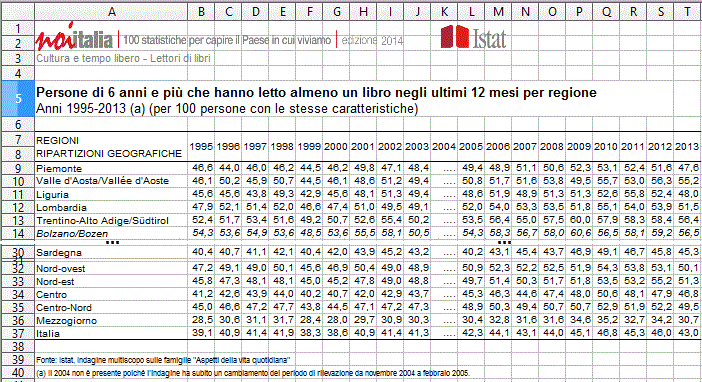
Per esaminarla con R ci conviene salvarla in formato CSV ("Salva con nome", "Salva come", "Testo CSV"); potremmo registrare i numeri in formato inglese, ma lasciamoli in formato italiano; prima di salvarla cancelliamo la colonna del 2004, K, in cui non ci sono dati; per far questo selezioniamo le colonne L e T e le spostiamo a sinistra di un posto. Ci viene chiesto con quali separatori di campo e di testo esportare il file: scegliamo ";" come separatore di campo (non posso lasciare "," avendolo lasciato come separatore tra parte intera e parte frazionaria) e non mettiamo nulla come separatore di testo (al posto delle virgolette). Otteniamo il file daistat.csv, che ha il seguente aspetto, visto con un editor di testo:
;;;;;;;;;;;;;;;;;;
Cultura e tempo libero - Lettori di libri;;;;;;;;;;;;;;;;;;
...
REGIONI
RIPARTIZIONI GEOGRAFICHE;1995;1996;1997;1998;1999;2000;2001;2002;2003;2005;2006;2007;2008;2009;2010;2011;2012;2013
;;;;;;;;;;;;;;;;;;
Piemonte;46,6;44,0;46,0;46,2;44,5;46,2;49,8;47,1;48,4;49,4;48,9;51,1;50,6;52,3;53,1;52,4;51,6;47,6
...
;;;;;;;;;;;;;;;;;;
Nord-ovest;47,2;49,1;49,0;50,1;45,6;46,9;50,4;49,0;48,9;50,9;52,3;52,2;52,5;51,9;54,3;53,8;53,1;50,1
...
Fonte: Istat, Indagine multiscopo sulle famiglie "Aspetti della vita quotidiana";;;;;;;;;;;;;;;;;;
A questo punto dal file tolgo i commenti, riduco qualche "nome" e ottengo il file daistat2.csv, che ha il seguente aspetto, visto con un editor di testo:
RIPART_GEO;1995;1996;1997;1998;1999;2000;2001;2002;2003;2005;2006;2007;2008;2009;2010;2011;2012;2013
Piemonte;46,6;44,0;46,0;46,2;44,5;46,2;49,8;47,1;48,4;49,4;48,9;51,1;50,6;52,3;53,1;52,4;51,6;47,6
...
Sardegna;40,4;40,7;41,1;42,1;40,4;42,0;43,9;45,2;43,2;40,2;43,1;45,4;43,7;46,9;49,1;46,7;45,8;45,3
N-O;47,2;49,1;49,0;50,1;45,6;46,9;50,4;49,0;48,9;50,9;52,3;52,2;52,5;51,9;54,3;53,8;53,1;50,1
...
Sud;28,5;30,6;31,1;31,7;28,4;28,0;29,7;30,9;30,3;30,4;32,8;31,6;31,6;34,6;35,2;32,7;34,2;30,7
Italia;39,1;40,9;41,4;41,9;38,3;38,6;40,9;41,4;41,3;42,3;44,1;43,1;44,0;45,1;46,8;45,3;46,0;43,0
Supponiamo di non aver scaricato il file e recuperiamolo da rete, e proviamo ad esaminarne qualche riga:
readLines("http://macosa.dima.unige.it/schede/bivar/daistat2.csv",n=4)
[1] "RIPART_GEO;1995;1996;1997;1998;1999;2000;2001;2002;2003;2005;2006;2007;2008;2009;2010;2011;2012;2013"
[2] "Piemonte;46,6;44,0;46,0;46,2;44,5;46,2;49,8;47,1;48,4;49,4;48,9;51,1;50,6;52,3;53,1;52,4;51,6;47,6"
...
Visto che i dati sono separati da ";" e che il separatore tra parte intera e frazionaria è ",", carichiamo i dati in una tabella nel modo seguente:
dati <- read.table("http://macosa.dima.unige.it/schede/bivar/daistat2.csv",sep=";",dec=",")
str(dati)
'data.frame': 29 obs. of 19 variables:
$ V1 : Factor w/ 29 levels "Abruzzo","Basilic",..: 21 19 28 12 13 25 3 26 29 9 ...
$ V2 : num 1995 46.6 46.1 45.6 47.9 ...
$ V3 : num 1996 44 50.2 45.6 52.1 ...
$ V4 : num 1997 46 45.9 43.8 51.4 ...
$ V5 : num 1998 46.2 50.7 49.3 52 ...
$ V6 : num 1999 44.5 44.5 42.9 46.6 ...
$ V7 : num 2000 46.2 46.1 45.6 47.4 50.7 53.6 48 43.3 50.4 ...
$ V8 : num 2001 49.8 48.6 48.1 51 ...
$ V9 : num 2002 47.1 51.2 51.3 49.5 ...
$ V10: num 2003 48.4 49.4 49.4 49.1 ...
$ V11: num 2005 49.4 50.8 48.6 52 ...
$ V12: num 2006 48.9 51.7 51.9 54 ...
$ V13: num 2007 51.1 51.6 48.9 53.3 ...
$ V14: num 2008 50.6 53.8 51.3 53.5 ...
$ V15: num 2009 52.3 49.5 51.3 51.8 ...
$ V16: num 2010 53.1 55.7 52.6 55.1 57.9 56.5 59.3 53.7 56.3 ...
$ V17: num 2011 52.4 53 55.8 54 ...
$ V18: num 2012 51.6 56.3 52.4 53.9 ...
$ V19: num 2013 47.6 55.2 48 51.5 ...
# essendo pochi i dati posso visualizzarli tutti digitando:
dati
# o posso visualizzarli in "tabella" con
edit(dati)
# ottenendo:
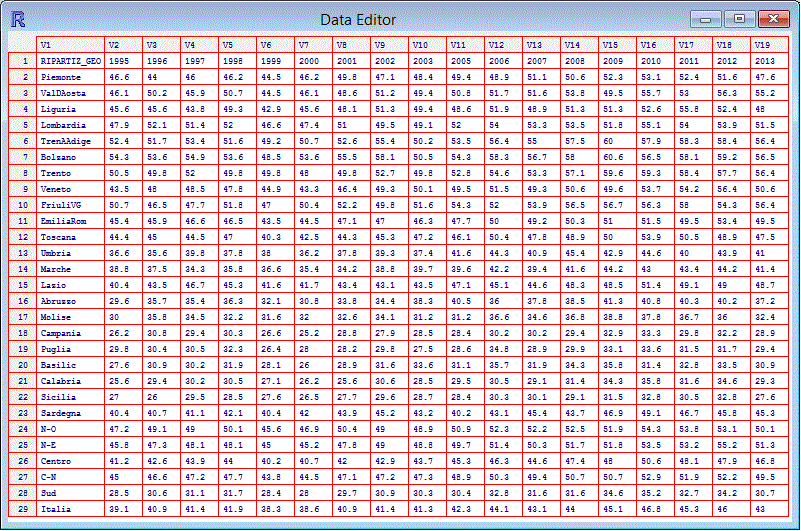
A questo punto posso elaborare i dati con R. Vediamo solo un paio di esempi. Innanzi tutto prima occorre osservare i dati. Vedo che manca un anno (il 2004). Ne terremo conto dopo. Proviamo a analizzare come si diversifica il fenomeno in Italia, e come la cosa è cambiata dal 1995 (colore nero) al 2013 (colore rosso).
anno1995 <- dati$V2[2:29]; anno2013 <- dati$V19[2:29] regioni <- dati$V1[2:29] names(anno1995) <- regioni barplot(anno1995,las=2) abline(h=axTicks(2),lty=3, col="brown") barplot(anno2013,las=2,angle=45,density=8,border="red",add=TRUE,col="red")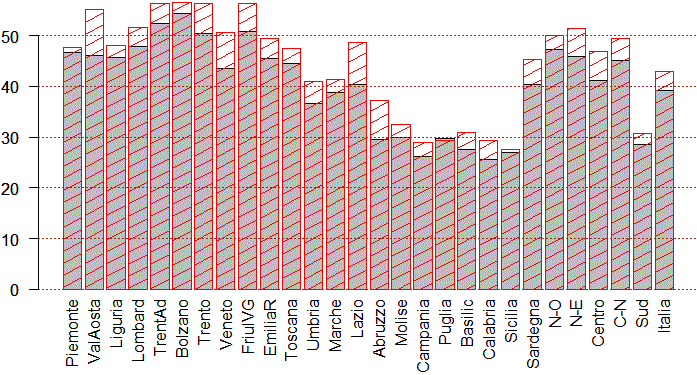
Vediamo, poi, come è evoluto il fenomeno nel corso degli anni (si noti il "salto" del 2004):
anni <- dati[1,2:19] liguria <- dati[4,2:19] plot(c(1995,2013),c(0,60),type="n",xlab="",ylab="") abline(h=axTicks(2),v=axTicks(1),lty=3, col="brown") points(anni,liguria); lines(anni,liguria) aosta <- dati[3,2:19]; points(anni,aosta); lines(anni,aosta,col="red") sicilia <- dati[22,2:19]; points(anni,sicilia); lines(anni,sicilia,col="blue") puglia <- dati[19,2:19]; points(anni,puglia); lines(anni,puglia,col="magenta") italia <- dati[29,2:19]; points(anni,italia); lines(anni,italia,lty=3) text(2002.5,17.5,"liguria") text(2002.5,12.5,"val d'aosta",col="red") text(2002.5,7.5,"puglia",col="magenta") text(2002.5,2.5,"sicilia",col="blue") text(1997.5,37.5,"ITALIA")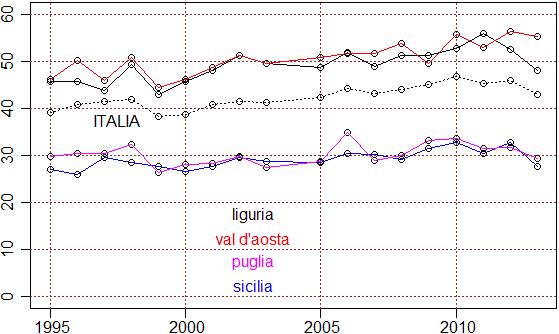
Abbiamo solo visto come usare R. Non ci occupiamo, qui, di analizzare i dati, per cui occorrerebbe aprire anche un'indagine sulla struttura e sui cambiamenti della composizione della popolazione nelle varie regioni (ad esempio per fasce di età, indagando anche il fenomeno dei trasferimenti per motivi di lavoro).