Statistica e Calcolo delle probabilità - Sintesi
0. Premessa
1. Approssimazioni, istogrammi ed altre rappresentazioni di dati distribuiti in modalità di tipo
non numerico
2. Rappresentazioni statistiche di dati numerici non classificati. Valori medi
3. Il caso dei dati interi e di quelli già classificati
4. Il calcolo delle probabilità
5. Leggi di distribuzione
6. Il teorema limite centrale. Altre leggi di distribuzione
7. Dipendenza e indipendenza stocastica
8. Sistemi di variabili casuali
9. Esercizi
0. Premessa
In questa scheda riassumiamo brevemente gli argomenti di statistica e probabilità affrontati negli anni precedenti.
1. Approssimazioni, istogrammi ed altre rappresentazioni di dati distribuiti in modalità di tipo non numerico
Consideriamo la tabella (1.1), in cui è riportato quanto si è speso in beni di consumo (alimenti, vestiti, automobili, …) e in servizi (taglio dei capelli, viaggi in treno, …) in Italia in due anni particolari.
| (1.1) |
| ||||||||||||||||||||||||||||||||||||||||
Nella tabella (1.2) abbiamo riportato gli stessi dati ma arrotondati ai miliardi. Ad esempio
77 749 milioni è più vicino a 78 000 milioni, ossia a
78 miliardi, che a 77 000 milioni, ossia a 77 miliardi, quindi viene arrotondato al primo
valore. In generale, per arrotondare un numero a n cifre si guarda la cifra n+1-esima: se questa è minore di 5 si
si sostituiscono con 0 tutte le cifre a destra del posto n, altrimenti si aumenta di uno la cifra di posto n e
si sostituiscono con 0 tutte le cifre alla sua destra. Si dice, anche, che 78 000 è
l'arrotondamento di 77 749 a 2 cifre significative.
Analogamente 951 000 è
l'arrotondamento di 950 502 a 3 cifre significative.
| (1.2) |
| ||||||||||||||||||||||||||||||||||||||||
Invece il troncamento ai miliardi è
77 000 milioni, ossia a 77 miliardi: per troncare un numero a n cifre si
sostituiscono, in ogni caso, con 0 tutte le cifre a destra del posto n. Si dice, anche, che 77 000
è il troncamento di 77 749 a 2 cifre significative.
Analogamente 950 000 è il
troncamento di 950 502 a 3 cifre significative.
Il numero 77 749 milioni, ossia 77 749 000 000, viene scritto più brevemente, e in modo più comprensibile, in notazione scientifica, ossia come 7.7749·1010.
Anche il software scrive i numeri molto grandi o molto piccoli in notazione scientifica. Ecco, ad esempio, come R (in cui, ad es., 5·10³ può essere scritto 5e3) rappresenta 950 502 milioni e 4 milionesimi:
950502e6; 0.000004 #9.50502e+11 4e-06
Vediamo come con R , dato un numero, posso calcolarne il più grande intero minore o eguale ad esso, il suo arrotondamento a tre cifre significative, il suo arrotondamento alla 3ª cifra a destra di quella delle unità e quello alla prima cifra a sinistra di quella delle unità:
175/6; floor(175/6); signif(175/6, 3); round(175/6, 3); round(175/6, -1) #29.16667 29 29.2 29.167 30
Ecco come calcolare la distribuzione percentuale. Metto i singoli dati in una collezione, c(...), che assegno ad una variabile che chiamo, ad esempio, dati. Faccio il rapporto tra i singoli dati e la loro somma, e lo moltiplico per 100. Nell'esempio seguente arrotondo le percentuali ai decimi.
dati = c(144291, 18461, 71352, 210285, 119857, 386256) dati/sum(dati) # 0.15180505 0.01942237 0.07506770 0.22123573 0.12609863 0.40637053 round( dati/sum(dati)*100, 1) # 15.2 1.9 7.5 22.1 12.6 40.6
| (1.3) |
| ||||||||||||||||||||||||
Se voglio estrarre un dato da una collezione devo metterne l'indice tra parentesi quadre. Un esempio, riferito ai dati precedenti:
dati[3]; dati[3]/sum(dati)*100 # 71352 7.50677
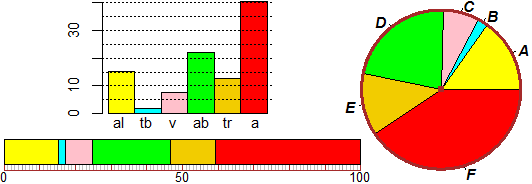
Ecco come rappresentare la distribuzione percentuale precedente con un istogramma a barre, con un areogramma circolare e con un diagramma a striscia. La prima rappresentazione ha il vantaggio di facilitare il confronto tra i singoli dati, le altre hanno il vantaggio facilitare quello tra i dati e il totale.
Se hai caricato col primo comando sotto riportato un'apposita libreria puoi fare queste rappresentazioni molto facilmente:
source("http://macosa.dima.unige.it/r.R")
Bar(dati); Strip(dati); PIE(dati)
# giallo,celeste,... % 15.1805 1.942237 7.50677 22.12357 12.60986 40.63705
Esistono molte varianti di questi comandi. Ad esempio l'areogramma a destra, con l'aggiunta delle lettere,
è stato realizzato, in realt�, col comando
settori = c("al","tb","v","ab","tr","a"); BarNames = settori
2. Rappresentazioni statistiche di dati numerici non classificati. Valori medi
Consideriamo i tempi, in secondi, tra una telefonata e l'altra in arrivo presso una organizzazione di vendite televisive, raccolti nel file difarr.htm allegato; se copio tale file in R vengono caricati nella variabile difarr i tempi. Ecco i primi dati raccolti nel file:
7.0, 6.0, 1.3, 2.1, 15.8, 5.3, 3.0, 28.0, 2.8, 10.4, 3.0, 2.8, 1.5, 10.3, ...
Con sort(difarr) posso ordinare i dati, con length(difarr) ottengo la quantit� dei dati (ovvero la "lunghezza" di length): 135.
Per rappresentare graficamente il file mediante un istogramma basta che azioni il comando istogramma(difarr): ottengo la rappresentazione sotto a destra:
# Supponiamo di aver già introdotto:
# source("http://macosa.dima.unige.it/r.R")
histogram(difarr)
# Frequenze e frequenze percentuali:
# 56, 33, 20, 12, 4, 3, 4, 2, 0, 1
# 41.48,24.44,14.81,8.89,2.96,2.22,2.96,1.48,0,0.74
# Per altre statistiche usa il comando altrestat()
morestat()
# Min. 1st Qu. Median Mean 3rd Qu. Max.
# 0.100 2.400 6.100 9.021 12.700 45.100
# I pallini marroni sono 5� e 95� percentile
# Il pallino rosso � la media |
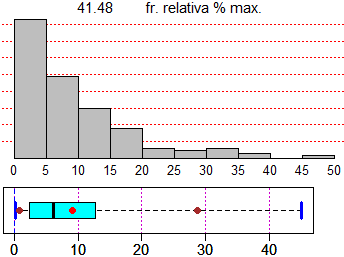 |
Gli intervalli in cui classificare i dati vengono scelti automaticamente e vengono stampate anche le frequenze assolute delle varie
classi (56 uscite in [0,5), 33 in [5,10), …) e le corrispondenti frequenze relative (41,48%, 24.44%; …). Le altre uscite e l'altra rappresentazione
grafica sono ottenute battendo altrestat().
Le uscite numeriche sono: il minimo e il massimo, la mediana (ossia il valore che sta al centro dei dati, messi in
ordine di grandezza), il 1º e il 3º quartile (ossia i valori che delimitano il primo quarto e il terzo quarto dei dati, messi
in ordine - il 2º quartile, ovviamente, è la mediana), e la media, che è pari a
Il diagramma a destra, chiamato boxplot, rappresenta graficamente le informazioni precedenti.
Il "box" centrale va dal primo quartile al terzo quartile e la barra che lo divide corrisponde alla mediana. I "baffi" partono
dal minimo e arrivano al massimo. Ci sono, poi, due pallini, a sinistra e a destra, che delimitano
il primo 5% dei dati e il primo 95% dei dati; il pallino al centro rappresenta la media.
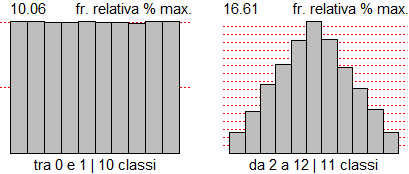
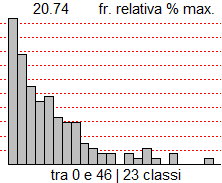
Posso scegliere altrimenti come classificare i dati usando il comando Istogramma (con la "I" in maiuscolo): metto gli estremi dell'intervallo che voglio considerare e l'ampiezza delle classi. Con noClassi=1 posso evitare la scritta delle coordinate di tutte le classi, brutta da vedere se queste sono molte.
noClass=1; Histogram(difarr, 0,46, 2) # Frequenze e frequenze percentuali: # 28, 21, 15, 12, 13, 9, 8, 8, 4, 3, 2 # 2, 0, 2, 1, 3, 1, 0, 2, 0, 0, 0, 1 # 20.74,15.56,11.11,8.89,9.63,6.67,5.93,5.93,2.96,2.22,1.48 # 1.48,0,1.48,0.74,2.22,0.74,0,1.48,0,0,0,0.74 |
 |
I dati precedenti erano arrotondati ai decimi di secondo e gli istogrammi realizzati avevano classi
ampie 5 secondi. Quindi possiamo interpretare i dati come se fossero "esatti". In altri situazioni occorre tener conto di come i dati
sono approssimati, se per arrotondamento o troncamento. Ad esempio se le età dei giocatori di una squadra di calcio fossero le
seguenti:
eta = c(31,28,23,29,25,33,24,21,27,33,20,31,24,20,25,23,20,26,24,28,28,26,27,32)
siccome si tratta di dati troncati (quando una persona dice di avere 23 anni intende dire che potrebbe anche avere 24 anni meno 1 giorno),
nel calcolare la media, arrotondata ai decimi di anno, devo aggiungere 1/2 e concludere che è 26.7. Sarebbe un grave errore (dal punto
di vista matematico) non farlo.
mean(eta); mean(eta+1/2)
#26.16667 26.66667
Anche l'istogramma dovrei tracciarlo di eta+1/2.
|
3. Il caso dei dati interi e di quelli già classificati
|  |
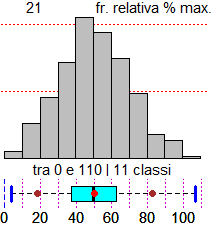
Se dispongo di dati già classificati per rappresentarli posso usare il comando istoclas. Vediamo come procedere riferendoci ai dati relativi alle età dei morti di sesso femminile nel 2006 classificate negli intervalli di anni [0,5), [5,10), …, [110,115):
intervalli = seq(0,115,5) # 0, 5, 10, ..., 115: gli estremi degli intervalli morti = c(39,4,5,9,10,12,16,25,40,64,102,155,236,355,593,1004,1666,2223,2077,1040,297,27,1) # i morti nelle varie classi di età (sono un dato in meno degli estremi degli intervalli) histoclas(intervalli,morti) morestat()
Ottengo le uscite numeriche e grafiche seguenti:
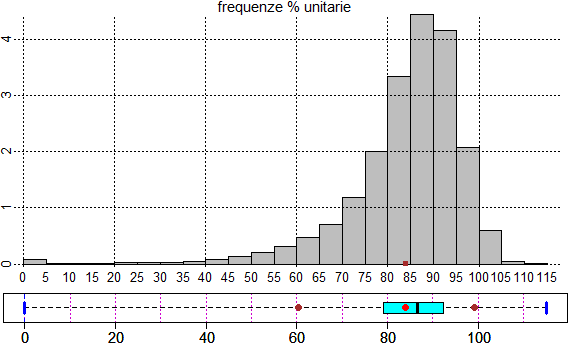 |
Min. 1st Qu. Median Mean 3rd Qu. Max. 0.00 79.15 86.49 83.98 92.27 115.00 |
|
In questo caso la media è più bassa della mediana in quanto vi è una coda a sinistra. Se i dati fossero stati troncati avrei dovuto procedere aggiungendo mezza unità dell'ordine di grandezza dell'ultima cifra, come visto alla fine del paragrafo precedente. 4. Il calcolo delle probabilità Consideriamo i dati sulle età delle femmine morte in Italia nel 2006 riportati alla fine del paragrafo precedente. Qual è la probabilità che, estratto del tutto a caso il nome di una di esse, la sua età di morte sia maggiore o eguale a 90 anni? Basta che calcoli la relativa percentuale; ottengo 34.42%: sum(c(2077,1040,297,27,1))/sum(morti)*100 # 34.42 Se indico con Età l'età di morte di una generica donna morta nel 2006, posso esprimere con la formula
Consideriamo un'altra situazione. Sta per disputarsi la partita Roma-Lazio. Gigi ritiene che la Roma 25 su 100 vincerà e 40 su 100 pareggerà.
Qual è la probabilità per Gigi che vinca la Lazio? La situazione,
indicato con R il risultato della partita ("1", "2" o "X"), può essere sintetizzata
così: In entrambi gli esempi ho associato ad alcuni eventi A un numero compreso tra 0 e 1 (=100%) come Pr(A) (probabilità di A). Ho poi dedotto le probabilità relative ad altri eventi applicando a Pr alcune delle proprietà che si erano già usate per le frequenze percentuali.
Naturalmente, a seconda di come si scelgono le valutazioni iniziali, per la stessa situazione si possono ottenere diverse misure di probabilità. Le valutazioni iniziali possono essere dedotte dall'esperienza o da considerazioni di tipo fisico o da propri convincimenti o …. Devono comunque essere tali da non condurre a contraddizioni: a partire da esse, applicando ripetutamente le proprietà sopra elencate, non posso ottenere valutazioni diverse per uno stesso evento, non posso ottenere probabilità negative o superiori al 100%, … (ad es. non posso valutare 60% la probabilità che nella prossima partita Roma-Lazio vinca la Roma e 50% che pareggino; verrebbe contraddetta la prima proprietà). Si osservi che il ruolo delle valutazioni iniziali mostra come anche in questo caso, come in altri discussi in altre voci, le conoscenze matematiche non sono di per sé sufficienti per modellizzare o risolvere "razionalmente" un problema. Facciamo un esempio in cui è facile fare valutazioni probabilistiche. Il lancio di un dado equo, ossia un dado che,
diversamente da quello costruito col cartoncino considerato nel paragrafo precedente, abbia tutte le facce "equiprobabili", ossia, indicata con U l'uscita, tale che
Pr(U=1) = Pr(U=2) = Pr(U=3) = Pr(U=4) = Pr(U=5) = Pr(U=6). Queste sono tutte le 6 possibili uscite. Sia P la probabilità di ciascuna di esse; per la
proprietà additiva P+P+P+P+P+P = 1, ossia P = 1/6.
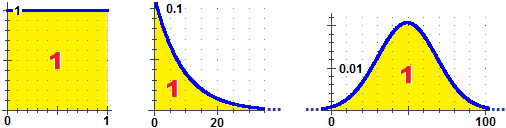
Potrei simulare il fenomeno anche con il generatore di numeri casuali, ossia usando il termine runif(n) che assume n valori reali che cadono in [0,1) ciascuno indipendentemente da dove cade il precedente e con distribuzione uniforme: presi comunque due sottointervalli di [0,1) ugualmente ampi, la probabilità che runif(1) cada nell'uno o nell'altro sono eguali. Vediamo come. # L'istogramma a sinistra, con distribuzione uniforme noClass=1; Histogram(runif(1e6), 0,1, 0.1) # Quello a destra, relativo al lancio di 2 dadi equi: # [ RUNIF(1, 1,6) è 1 intero a caso tra 1 e 6 ] n = 10000; U1 = RUNIF(n, 1,6); U2 = RUNIF(n, 1,6) noClass=1; Histogram(U1+U2, 1.5,12.5, 1) morestat() # Min. 1st Qu. Median Mean 3rd Qu. Max. # 2.000 5.000 7.000 6.973 9.000 12.000
Il comando hist contiene l'opzione probability=TRUE che fa rappresentare
verticalmente le densità, ossia le frequenze relative (preciseremo questo termine tra poco), right=FALSE impone che gli intervalli
di classificazione siano del tipo
Lo studiamo teoricamente: al 50% testa esce al primo lancio (N=1), nei casi rimanenti al 50% (ossia, complessivamente, al 25%) esce al secondo lancio (N=2), al 12.5% esce per N=3, al 6.25% esce per N=4, …. Il grafico sopra a destra rappresenta il fenomeno solo fino a N=9. Ecco come è stato realizzato:
La somma delle altezze di tutte le colonnine deve essere 100%, ossia 1. E infatti: 1/2 + 1/4 + 1/8 + … fa 1. Non deve stupire che la somma di infiniti numeri sia un numero: sin dai primi anni scolastici avete imparato che, ad esempio, 0.3 + 0.03 + 0.003 + … = 0.333… = 1/3. Qual è il numero medio di lanci da effettuare affinché esca testa? Devo fare la media pesata. Facciamo un esempio. Se il valore 3 esce 5 volte e il 9 esce 10 volte, la media è (3·5+9·10)/(5+10) = 7. Ma posso anche fare 3·5/(5+10) + 9·10/(5+10), ossia fare la somma dei valori moltiplicati per le frequenze relative. Nel nostro caso: # una prova per 4 valori 1*1/2 + 2*1/2^2 + 3*1/2^3 + 4*1/2^4 # 1.625 # generalizziamo: n = 1:4; sum(n*1/2^n); n = 1:10; sum(n*1/2^n); n = 1:50; sum(n*1/2^n) # 1.625 1.988281 2 La media, 1/2 + 2/2^2 + 3/2^3 + 4/2^4 + 5/2^5 + …, è 2. A questo punto dobbiamo mettere a punto degli strumenti per verificare quando una curva rappresenta
una funzione di densità, ossia una funzione sul cui grafico tende a stabilizzarsi l'istogramma della
frequenza relativa di una variabile casuale continua all'aumentare del numero delle prove.
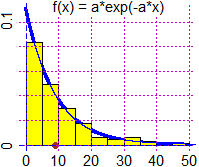
La distribuzione esponenziale negativa
Verifichiamo che l'area sottesa al grafico di f è 1. La funzione esponenziale ha la caratteristica di avere Dx exp(x) = exp(x), e, quindi,
Abbiamo già osservato che la media è il reciproco di a (m = 1/a). Verifichiamolo precisando il significato di "media" nel caso continuo. Nel caso discreto essa è la somma dei valori moltiplicati per le frequenze relative, ovvero
moltiplicati per le probabilità. [qui vediamo solo come ottenere questo valore con WolframAlpha:
integral x*a*exp(-a*x) dx from 0 to oo
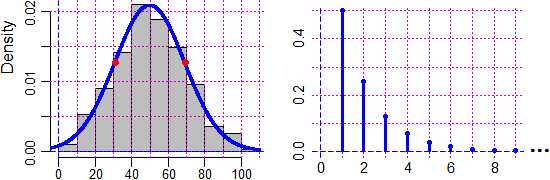
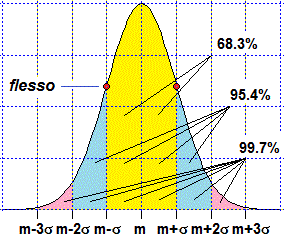
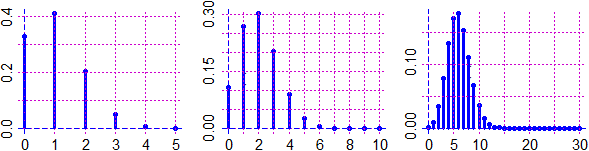
Vediamo come è stato fatto il grafico della gaussiana sovrapposto all'istogramma riportato all'inizio del paragrafo, con qualche aggiustamento (prova ad eseguire il listato). In R la gaussiana (o distribuzione normale) può essere introdotta usando semplicemente il nome dnorm. 6. Il teorema limite centrale. Altre leggi di distribuzione Consideriamo un ulteriore esempio di legge di distribuzione. Supponiamo che una fabbrica di biscotti disponga di un forno che bruciacchi i biscotti con la frequenza p (ossia questa è la probabilità che un biscotto sia bruciacchiato) e che venda i biscotti in confezioni da n pezzi. Qual è la probabilità che in una confezione il numero N dei biscotti bruciacchiati sia k? Se n = 6 e p = 1/8 la probabilit� che esattamente i primi 4 biscotti siano bruciacchiati è (1/8)·(1/8)·(1/8)·(1/8)·(7/8)·(7/8) = (1/8)4·(7/8)2. Questo valore dobbiamo moltiplicarlo per i possibili sottoinsiemi di 4 elementi che possono essere formati da un insieme di 6 elementi. Questo numero viene in genere indicato C(6,4) e chiamato numero delle combinazioni di 6 elementi 4 a 4, ed è pari al numero dei quartetti ordinati (6·5·4·3: 6 modi di prendere il primo elemento, 5 di prenderne il secondo; …) diviso per i modi in cui posso ordinare 4 elementi (4·3·2·1). C(6,4) = (6·5·4·3)/(4·3·2·1) = 6/4·5/3·4/2·3/1 = 6·5/2/1 = 3·5 = 15 Nel software in genere C(n,k) è indicato choose(n,k). Ecco i sottoinsiemi di 0, 1, …, 6 elementi di un insieme di 6 elementi: k = 0:6; choose(6, k) #1 6 15 20 15 6 1 Dunque, nel nostro caso particolare, la probabilità che vi siano 4 biscotti bruciacchiati è C(6,4)·(1/8)4·(7/8)2 = 15·(1/8)4·(7/8)2 = 0.0028038 = 0.28% (arrotondando). In generale: Pr(N = k) = C(n, k) · pk · (1 – p)n–k Questa legge di distribuzione viene chiamata legge di distribuzione binomiale (o di Bernoulli). Si applica a tutte le situazioni in cui si ripete n volte la prova su una variabile casuale che può assumere solo due valori, in cui p è la probabilità di uno di questi due valori e N è il numero delle volte in cui questo valore esce. Ecco qualche grafico, definita g = function(x) dbinom(x, n,p).
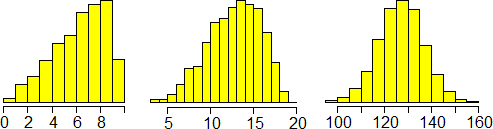
Si noti come all'aumentare di n l'istogramma di distribuzione tende ad assumere una forma simile alla
gaussiana. Come mai? La binomiale di ordine n è ottenibile come somma di n termini uguali ad una variabile casuale ad uscite in 0 ed 1
(ad esempio, nel caso dei 6 biscotti, è la somma di 6 variabili ad uscite in 0 od 1). Consideriamo un'altra variabile casuale che rappresenta
la ripetizione di esperimenti, ad esempio la somma di n termini pari a 9·√RND+RND², dove con RND abbiamo indicato
le uscite del generatore di numeri casuali. Ecco i grafici, per n pari ad 1, 2 e 20, ottenuti con:
Si può dimostrare che se Ui (i intero positivo) sono n variabili casuali (numeriche)
indipendenti con la stessa legge di distribuzione, allora
al crescere di n la variabile casuale
Tale proprietà, nota come teorema limite centrale, oltre ad essere utile per approssimare la binomiale nel caso in cui n sia molto grande, è fondamentale nelle applicazioni. Vediamo un esempio. Voglio determinare il valor medio M(P) dove P è il "peso di un abitante adulto maschio" (di un certo paese). Indico con σ lo sqm di P. Rilevo i pesi P1, P2, …, Pn di n persone.
Quanto qui detto per P vale per ogni variabile casuale.
Questi due termini sono spesso chiamati rispettivamente deviazione standard teorica e deviazione standard corretta o non distorta o statistica. Spesso sono entrambi chiamati semplicemente deviazione standard: sta al lettore capire quale uso si sta facendo. Il software R, ad es., indica con sd la deviazione standard corretta. Comunque quando n è abbastanza grande i due numeri hanno una piccola differenza relativa.
Ricordiamo (facendo riferimento all'esempio precedente) che è la media dei pesi
che si misurano ad avere andamento gaussiano, non i pesi stessi. Vediamo un altro uso del teorema limite centrale
per valutare la media di una variabile casuale, comunque sia distribuita. Un'altra legge di distribuzione che ha andamento abbastanza simile a quello della binomiale e che trova applicazione soprattutto in fisica e in biologia, in situazioni in cui gli eventi accadono abbastanza "raramente", è la legge di Poisson. Rimandiamo agli Oggetti Matematici chi voglia prenderne conoscenza. 7. Dipendenza e indipendenza stocastica
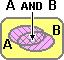
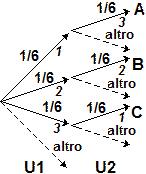
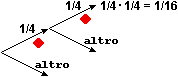
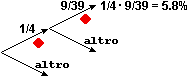
(a) Qual è la probabilità che alzando 2 volte un mazzo (nuovo) di carte da scopa ottenga sempre
una carta di denari?
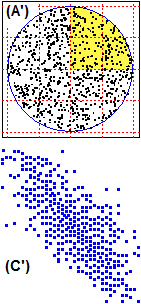
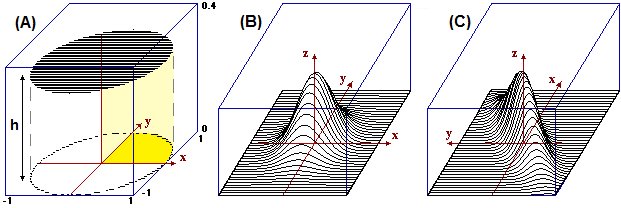
Indichiamo con le variabili casuali S1 e S2 il seme della prima uscita e quello della seconda. Nel caso della alzata S1 e S2 sono indipendenti: qualunque seme abbia la 1ª carta, la probabilità che la 2ª abbia un certo seme è sempre la stessa. Ciò corrisponde al fatto che il grafo relativo all'alzata si riproduce allo stesso modo passando da una diramazione alla successiva. Per calcolare Pr(S1=♦ and S2=♦) posso fare direttamente Pr(S1=♦)·Pr(S2=♦) = 1/4·1/4 = 1/16. Nel caso della estrazione S1 e S2 non sono indipendenti: ad es. Pr(S2=♦) (la probabilit� che la 2ª carta sia di ♦) dipende dal valore assunto da S1 (cioè dal seme della 1ª carta). Ciò corrisponde al fatto che il grafo relativo alla estrazione non si riproduce allo stesso modo passando da una diramazione alla successiva: al primo arco "♦" è associata la probabilità 1/4, al secondo arco "♦" è associata la probabilità 9/39. Due variabili casuali X e Y sono probabilisticamente indipendenti se sono indipendenti gli eventi A e B comunque prenda A evento relativo a X (condizione in cui compare solo la variabile X) e B evento relativo a Y (condizione in cui compare solo variabile Y): conoscere qualcosa su come si manifesta X non modifica le mie aspettative sui modi in cui può manifestarsi Y, e viceversa. Altrimenti sono probabilisticamente dipendenti. Esempio: − sapere qualcosa a proposito del seme della 1ª carta estratta cambia le mie valutazioni sul seme che potrebbe avere la 2ª carta estratta: il seme della 1ª estrazione e quello della 2ª sono variabili casuali dipendenti. Ricordiamo che il concetto di dipendenza ora introdotto è diverso da quello impiegato per esprimere il legame tra due grandezze quando una varia in funzione dell'altra. L'avverbio "probabilisticamente" (o l'equivalente avverbio "stocasticamente") evidenzia questa differenza. Se non ci sono ambiguità, questo avverbio viene omesso.
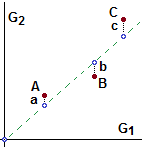
Nel caso (A) i valori che può assumere una delle due variabili
è condizionato da quello che assume l'altra: se X è vicino ad 1 Y per forza deve essere vicino a 0.
Si può dimostrare che se X
e Y sono dipendenti deterministicamente e legate da una relazione lineare Y = aX + b il coefficiente di
correlazione assuma il valore assoluto massimo. Vale 1 se l'andamento è crescente e −1
se è decrescente. Quindi, in generale,
In R il coefficiente di correlazione tra X ed Y è indicato cor(X,Y). Ecco, ad esempio, la parte iniziale del file battito.txt:
che potrei leggere col comando: Se raccolti su una usuale tabella i dati assumerebbero questo aspetto:
Vedo che si sono righe di commento inizianti con # e 1 riga di "intestazioni", e che
dati sono separati da ",". Il software R salta automaticamente le righe inizianti
con #. Metto, dunque, i dati in una "table" con: 'data.frame': 92 obs. of 9 variables: $ Num : int 1 2 3 4 5 6 7 8 9 10 ... $ BatPrima: int 64 58 62 66 64 74 84 68 62 76 ... $ BatDopo : int 88 70 76 78 80 84 84 72 75 118 ... $ Corsa : int 1 1 1 1 1 1 1 1 1 1 ... $ Fumo : int 0 0 1 1 0 0 0 0 0 0 ... $ Sesso : int 1 1 1 1 1 1 1 1 1 1 ... $ Alt : int 168 183 186 184 176 184 184 188 184 181 ... $ Peso : int 64 66 73 86 70 75 68 86 88 63 ... $ Fis : int 2 2 3 1 2 1 3 2 2 2 ... Col comando summary posso avere una informazione sintetica di tutte le variabili; ma la prima colonna contiene solo il numero d'ordine, quindi invece di usare summary(dati) esamino solo le colonne dalla 2 alla 9 con: summary(dati[2:9])
BatPrima BatDopo Corsa Fumo
Min. : 48.00 Min. : 50 Min. :0.0000 Min. :0.0000
1st Qu.: 64.00 1st Qu.: 68 1st Qu.:0.0000 1st Qu.:0.0000
Median : 71.00 Median : 76 Median :0.0000 Median :0.0000
Mean : 72.87 Mean : 80 Mean :0.3804 Mean :0.3043
3rd Qu.: 80.00 3rd Qu.: 85 3rd Qu.:1.0000 3rd Qu.:1.0000
Max. :100.00 Max. :140 Max. :1.0000 Max. :1.0000
Sesso Alt Peso Fis Min. :1.00 Min. :154.0 Min. :43.00 Min. :0.000 1st Qu.:1.00 1st Qu.:167.8 1st Qu.:57.00 1st Qu.:2.000 Median :1.00 Median :175.0 Median :66.00 Median :2.000 Mean :1.38 Mean :174.4 Mean :65.84 Mean :2.109 3rd Qu.:2.00 3rd Qu.:183.0 3rd Qu.:70.25 3rd Qu.:2.000 Max. :2.00 Max. :190.0 Max. :97.00 Max. :3.000
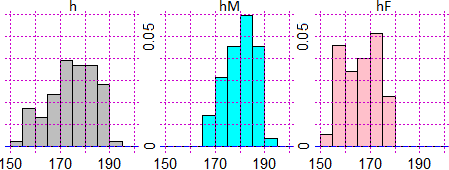
Come analizzare un singolo campo (le altezze) e suoi sottocampi (quelle femminili e quelle maschili):
Ecco la matrice di correlazione, che sintetizza le correlazioni tra tutte le diverse variabili di "battito" [avrei potuto battere solo cor(dat[2:9]) ottenendo valori di 8 cifre; con print(…,2) posso "accorciare" i valori; posso usare, con esiti diversi, round(…,3)]: round(cor(dat[2:9]),3)
BatPrima BatDopo Corsa Fumo Sesso Alt Peso Fis
BatPrima 1.000 0.616 0.052 0.129 0.285 -0.211 -0.203 -0.063
BatDopo 0.616 1.000 0.577 0.046 0.309 -0.153 -0.166 -0.141
Corsa 0.052 0.577 1.000 0.066 -0.107 0.224 0.224 0.007
Fumo 0.129 0.046 0.066 1.000 -0.129 0.043 0.201 -0.120
Sesso 0.285 0.309 -0.107 -0.129 1.000 -0.709 -0.710 -0.105
Alt -0.211 -0.153 0.224 0.043 -0.709 1.000 0.783 0.089
Peso -0.203 -0.166 0.224 0.201 -0.710 0.783 1.000 -0.004
Fis -0.063 -0.141 0.007 -0.120 -0.105 0.089 -0.004 1.000
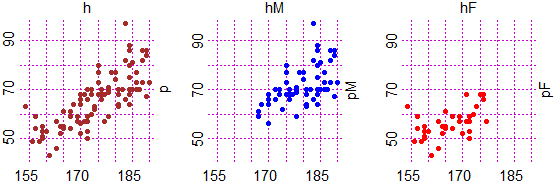
Tra altezza e peso vi è un alto coefficiente di correlazione: 0.78. Se ci restringiamo a una sottopopolazione più omogenea (quella femminile o quella maschile, che hanno pesi e altezze con medie abbastanza diverse), ci potremmo aspettare di ottenere un coefficiente maggiore. Ma se estraiamo la popolazione femminile otteniamo 0.52. Perché? round(cor(dat[7],dat[8]),3)
Peso
Alt 0.783
round(cor(subset(dat[7],dat$Sesso==1),subset(dat[8],dat$Sesso==1)),3)
Peso
Alt 0.590
round(cor(subset(dat[7],dat$Sesso==2),subset(dat[8],dat$Sesso==2)),3)
Peso
Alt 0.519
Se traccio in rettangoli cartesiani uguali, i grafici di dispersione Plane(min(dat$Alt),max(dat$Alt),min(dat$Peso),max(dat$Peso))
abovex("h"); abovey("p"); Point(dat$Alt,dat$Peso,"brown")
Plane(min(dat$Alt),max(dat$Alt),min(dat$Peso),max(dat$Peso))
abovex("hM"); abovey("pM")
Point(subset(dat$Alt,dat$Sesso==1),subset(dat$Peso,dat$Sesso==1),"blue")
Plane(min(dat$Alt),max(dat$Alt),min(dat$Peso),max(dat$Peso))
abovex("hF"); abovey("pF")
Point(subset(dat$Alt,dat$Sesso==2),subset(dat$Peso,dat$Sesso==2),"red")
Questo esempio mette in luce come le statistiche che si ottengono sono spesso ingannevoli. In casi come questo, abbastanza frequenti, il problema è dovuto alla presenza di due sottopopolazioni con caratteristiche differenti. Poi occorre tener conto che quelle individuate sono solo relazioni statistiche, non di
causa-effetto. Ad esempio nel caso della correlazione
tra le colonne "battito dopo" e "corsa" di "battito"
c'è effettivamente una relazione causale (l'aver fatto la corsa influenza il battito cardiaco).
Ma quando nel caso di uno studio statistico sulle condizioni delle famiglie è emersa una forte correlazione
negativa fra il loro consumo di patate e la superficie dell'abitazione in cui vivono, essa non è
da interpretare come conseguenza di una relazione di causa-effetto: è semplicemente dovuta al fatto che le
famiglie benestanti abitano in genere in case di maggiori dimensioni e, nello stesso tempo, consumano meno patate
delle altre famiglie privilegiando cibi più costosi, come la carne e il pesce.
Purtroppo, specie nei campi medico e socio-psicologico, spesso si fanno collegamenti di questo genere. Di fronte a dati sperimentali relativi a un sistema (X,Y) per cui si ritiene che Y vari in funzione di X, si può cercare di trovare una funzione F tale che il suo grafico approssimi i punti sperimentali. Vediamo come procedere nel caso in cui X ed Y siano casuali. Si cerca di individuare il tipo di funzione (lineare, polinomiale, esponenziale, …) che si vuole utilizzare. Se si ipotizza che ci sia una relazione lineare che esprima Y in funzione di X, e non si hanno altre informazioni, la tecnica in genere usata è quella dei minimi quadrati, che consiste nel trovare la retta, generica o passante per un punto fissato, a seconda dei casi, che rende minima la somma dei quadrati degli scarti tra i valori sperimentali di Y e quelli che sarebbero stati associati ai valori di X dalla equazione della retta.
9. Esercizi Vai qui. |