2. Relazioni tra variabili casuali
3. Relazioni non lineari
4. Il test χ²
5. Esercizi
 Sintesi
SintesiApprofondimenti di Statistica e Probabilità
1. Richiami
2. Relazioni tra variabili casuali
3. Relazioni non lineari
4. Il test χ²
5. Esercizi
Sintesi
1. Richiami
Nel punto 3b del "ripasso trovi come rivedere, sia sintetizzati che svolti per esteso, i principali argomenti di statistica e calcolo della probabilità finora affrontati. In questa scheda riprenderemo nel primo paragrafo alcuni concetti utili per studiare la relazione tra due variabili aleatorie e, nei successivi, svolgeremo alcuni approfondimenti per alcuni tipi di scuole.
2. Relazioni tra variabili casuali
|
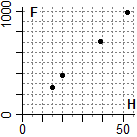
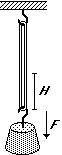
Rivediamo, rapidamente, su uno stesso esempio, alcuni concetti affrontati nella scheda Sistemi di variabili casuali. Per studiare le caratteristiche di un elastico lo tengo sospeso per un estremo e appendo all'altro diversi oggetti. Ogni volta misuro il peso dell'oggetto e il corrispondente allungamento dell'elastico. Il peso F degli oggetti lo misuro con una bilancia a molla con divisioni di |
|  |
 |
I valori sono stati rappresentati anche su un grafico, con dei pallini. Evidentemente H ed F sono correlate, ossia al variare dell'una anche l'altra tende a variare più o meno proporzionalmente. Per misurare quanto i punti che rappresentano le due variabili casuali tendono a disporsi lungo una retta obliqua (passante o no per l'origine) si usa il coefficiente di correlazione, che è vicino a 0 se le variabili sono poco correlate, si avvicina ad 1 se i punti sono quasi allineati lungo una retta con pendenza positiva, si avvicina a −1 se sono quasi allineati lungo una retta con pendenza negativa. Nel nostro caso:
H = c(15,20,39,52); F = c(260,380,710,990)
BF=3; HF=3
Plane(-1,55, -10,1020); abovex("H");abovey("F"); POINT(H,F,"black")
cor(H,F) # ottengo 0.9987686
cor(F,H) # ottengo 0.9987686
|
Ottengo, in questo caso particolare, un valore molto vicino ad 1. Non importa l'ordine con cui metto le due variabili: il valore è sempre lo stesso.
Ma studiare la relazione tra H ed F, in questa situazione, in cui evidentemente le due grandezze sono una dipendente dall'altra, non può limitarsi ad individuare il coefficiente di correlazione. Può essere utile cercare una funzione che esprima la relazione che c'è tra H ed F. Posso cercare di trovare la retta che approssima i punti rendendo minima la somma dei quadrati degli scarti tra i valori sperimentali di F e quelli che sarebbero stati associati ai corrispondenti valori di H dalla equazione della retta (questo metodo è chiamato dei minimi quadrati). Ecco come farlo con R (lr sta per "linear regression"; mettiamo i due coefficienti della retta in n; essi saranno n[1] e n[2]). Sotto a sinistra la rappresentazione della retta.
n = LR(H,F); n # -21.40182 19.25085 r1 = function(x) n[1]+n[2]*x; graph1(r1,-1,55, "brown") |
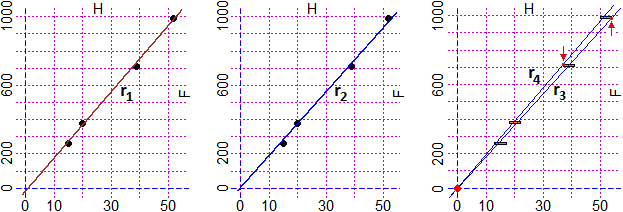
Ma in questo caso devo tener conto che ad H = 0 deve corrispondere F = 0, mentre il grafico precedente non passa per (0,0). Devo cercare di trovare la retta passante per (0,0) che rende minima la somma dei quadrati degli scarti. Ecco come farlo con R. Sopra al centro la rappresentazione della retta.
Plane(-1,55, -10,1020); abovex("H"); abovey("F"); POINT(H,F, "black")
m = LR0(H,F,0,0); m # 0,0 č il punto per cui voglio passi la retta
# 0.00000 18.57143
r2 = function(x) m[2]*x; graph1(r2,-1,55, "blue")
|
Una retta ottenuta in questo modo (con o senza un punto fissato) viene chiamata retta di regressione e il suo coefficiente direttivo (18.7 nell'ultimo esempio) è chiamato coefficiente di regressione.
Dunque F = 18.7 H è una buona approssimazione della relazione che intercorre tra F ed H. Ma quanto è precisa questa approssimazione? La precisione, evidentemente, dipende dalla quantità dei dati: per una coppia qualunque di punti passa una retta, ma, evidentemente, non posso prendere questa come grafico della relazione tra le due variabili. Mi limito a usare il software per fare questa valutazione (non abbiamo gli strumenti per capire come essa viene effettuata):
confInt0(F,H, 0,0, 90/100) # 5 % 95 % # Conf 18.03658 19.35311 |
L'intervallo ottenuto, [18.04, 19.35], è un intervallo di confidenza al 90%.
In esso, con tale probabilità, cade il valore di k tale che
Anche il coefficiente di correlazione dipende dalla quantità dei dati e anche per esso si può determinare un intervallo di confidenza. Vediamo quello al 90% per H ed F:
cor.test(H,F, conf.level=90/100) # 90 percent confidence interval: # 0.9674734 0.9999541 |
Ma in questi ragionamenti non ho tenuto conto di tutte le informazioni di cui dispongo. In questo caso so che la relazione tra il peso e l'allungamento dell'elastico, nel range di misure che ho considerato, è lineare (per valori superiori del peso la relazione non è detto che sia più lineare: la deformazione dell'elastico potrebbe seguire una legge un po' diversa; una cosa analoga accade anche per le molle), e conosco la precisione delle misure, cioè, per ogni punto del grafico, conosco l'intervallo delle ascisse e quello delle ordinate in cui cade. Per i valori di H e di F rappresentati in tabella ho una precisione di 2 (mm) e di 5 (g). Nel grafico della figura precedente, a destra, ho rappresentato correttamente in punti sperimentali con dei rettangoli di base 4 e altezza 10. Cerco le rette passanti per l'origine e per i tutti i rettangolini di minima e di massima pendenza. Nella figura è evidenziato come trovare tali pendenze riferendosi al grafico. Ecco, qui sotto, come trovarle con R, col comando pointDif:
Plane(-1,55, -10,1020); abovex("H"); abovey("F")
eH = rep(2,4); eF = rep(5,4) # le precisioni dei valori di H e di F
# [sono tutte = per cui le ripeto con rep, o metto eH=c(2,2,2,2), …]
pointDif(0,0, H,F, eH,eF)
# 18.24074 * x
# 19.32432 * x
|
"Con certezza" l'intervallo è [18.24074, 19.32432], ovvero [18.2, 19.4], ovvero 18.8 ± 0.6.
Qui abbiamo visto solo come approssimare coppie di dati con funzioni lineari. Se i dati hanno andamento diverso occorre approssimarli con funzioni di tipo diverso, ma non disponiamo degli strumenti matematici per affrontare questo studio. Nel paragrafo successivo c'è qualche cenno al caso dei dati con andamento quadratico e cubico.
3. Relazioni non lineari
Nel paragrafo precedente abbiamo considerato solo il caso della approssimazione di dati mediante funzioni lineari. Nel caso di altri andamenti esistono varie tecniche, che dipendono dai modi in cui sono stati raccolti i dati di cui si dispone, dalle altre informazioni che abbiamo sulle funzioni che vogliamo li approssimino, …. Piuttosto che imparare alcune ricette è bene, quando si hanno una serie di dati da analizzare, rivolgersi a chi ha esperienze e conoscenze sull'argomento. L'obiettivo di questo paragrafo è solo quello di dare un'idea delle tecniche che si possono impiegare.
Consideriamo un
esempio semplice, che, comunque, si riferisce a situazioni abbastanza diffuse.
Un oggetto, pesante e di forma compatta, viene lasciato cadere e ne viene misurata,
mediante una successione di immagini fotografiche scattate
ogni decimo di secondo, l'altezza in cm da terra. Supponiamo che in corrispondenza
dei tempi di 1, 2, 3, 5 decimi di secondo (rilevati con errori trascurabili)
si registrino, in ordine, le altezze da terra di 131, 113, 89 e 7 cm,
arrotondate tutte con la stessa precisione, ad es. di 1 cm.
In situazioni di questo genere, in cui si conoscono le coordinate di N
punti sperimentali con ascisse xi note esattamente e con ordinate yi
della stessa indeterminazione, si può ricorrere ad un procedimento chiamato regressione polinomiale che generalizza
le tecniche considerate per trovare le rette di regressione al caso della determinazione dei coefficienti
della funzione polinomiale di grado 2 che "con maggiore probabilità" approssima i
punti noti. Senza entrare nei dettagli di esso, si ottiene che si tratta della
funzione
A·N + B·Σxi + C·Σxi2 = Σyi
A·Σxi + B·Σxi2 + C·Σxi3 = Σxiyi
A·Σxi2 + B·Σxi3 + C·Σxi4 = Σxi2yi.
Risolvendo il sistema si ottengono le soluzioni seguenti, a cui corrisponde la
rappresentazione grafica sottostante, a sinistra:
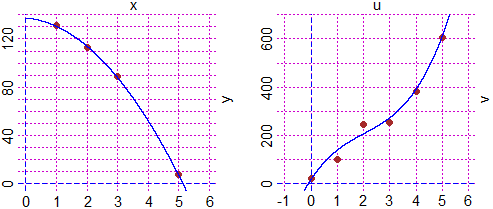
Con un procedimento simile, ma più complesso, si può trovare la funzione polinomiale di grado 3
che approssima i punti di ascisse 0, 1, 2, 3, 4, 5 e ordinate 21, 99, 246, 252, 381, 608, ottenendo la funzione
Nei seguenti link, uno e due, puoi trovare come sviluppare i calcoli precedenti con R e come calcolare un coefficiente di correlazione per la regressione polinomiale anche nel caso dei polinomi di 3º grado.
4. Il test χ²
In questa voce ci occuperemo di una delle varie tecniche per prendere delle decisioni
sulla base di dati statistici raccolti sperimentalmente.
Valutata la probabilità di un evento o individuata una legge di distribuzione o … solo sulla base di dati sperimentali,
non abbiamo la certezza di questa conclusione. Possiamo, comunque, porci il problema di quanto sia verosimile l'ipotesi che il valore o la
funzione o … individuata sia effettivamente una buona approssimazione, cioè valutare la probabilità che il suo scarto
dall'oggetto (valore, funzione, …) "vero" rientri nei margini di aleatorietà dovuta alla limitatezza del materiale statistico a disposizione.
In base a questa valutazione, a seconda della situazione (con considerazioni pratiche, legate al contesto, ai rischi sociali, …), potremo stabilire se tale ipotesi è accettabile o è da rifiutare.
Abbiamo affrontato attività di questo genere quando abbiamo introdotto il
teorema limite centrale:
all'intervallo frequenza
Se in base a qualche ragionamento ho ipotizzato che Pr(A) sia 3/7 e
trovo che 3/7 sta nell'intervallo frequenza
In questo paragrafo vedremo in particolare come valutare l'attendibilità di una legge di distribuzione o, meglio, di valutare la conformità tra una distribuzione sperimentale e una teorica.
Come valutare la discordanza tra gli esiti di n prove, classificati in nc classi, e una certa legge di distribuzione?
Supponiamo di voler confrontare con la distribuzione Pr(U=2) = 1/36, Pr(U=3) = 2/36, … gli esiti del lancio di una coppia di dadi ripetuto n volte. Indichiamo con FrOs1, …, FrOs11 le frequenze assolute osservate (FrOs1 + FrOs11= n) e con FrAt1, …, FrAt11 le frequenze assolute attese, cioè i valori FrAt1 = n·1/36, FrAt2 = n·2/36, …
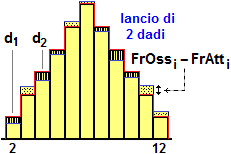 |
Una idea è prendere
|
Lo stesso valore viene preso nel caso di un'altra variabile casuale. Cambia il modo in cui sono calcolate le frequenze attese nelle nc classi (intervallini o altri insiemi) I i in cui ho classificato gli n dati; se la variabile casuale è continua sono calcolate integrando su I i la funzione densità.
χ² è una variabile aleatoria (assume un valore diverso ogni volta che effettuo n prove) che, oltre che dal fenomeno studiato, dipende dal numero delle prove n, dalle classi I1, …, I nc scelte e dalla legge di distribuzione teorica L di cui si vuole valutare la verosimiglianza, da cui dipendono le frequenze attese.
Consideriamo ad esempio un dado di cui si sono effettuati 50 lanci ottenendo 9 uno, 11 due, 5 tre, 8 quattro, 10 cinque e 7 sei. Per valutare la discordanza dalla distribuzione uniforme (distribuzione corrispondente ai dadi equi), calcoliamo il relativo χ². Poniamoci, poi, il problema di individuare la distribuzione χ² teorica nel caso in cui il dado sia realmente equo, in modo da poter confrontare con essa il χ² trovato e valutare la verosimiglianza dell'equità del nostro dado.
Potremmo svolgere il calcolo "a mano". Effettuiamolo mediante il programma R. Otteniamo 2.8.
FrOs = c(9,11,5,8,10,7)
Prob = c(1/6,1/6,1/6,1/6,1/6,1/6); n = sum(FrOs)
FrAt = Prob*n; sum( (FrOs-FrAt)^2/FrAt )
# 2.8
Effettuato questo calcolo, che cosa possiamo concludere sulla equità del dado?
Studiamo la distribuzione teorica χ², cioè come si distribuirebbe il valore di
χ² se il dado fosse equo. Realizziamo questo studio sperimentalmente, con una simulazione dei 50 lanci.
Ecco l'esito della generazione di 10000 valori, analizzato con R:
Prob = rep(1/6,6); FrAt = 50*Prob
x = NULL; y = NULL; for (n in 1:1e4) {
for(i in 1:6) y[i]=0
for (k in 1:50) {u=RUNIF(1, 1,6); y[u]=y[u]+1}
x[n] = sum((y-FrAt)^2/FrAt) }
summary(x)
# Min. 1st Qu. Median Mean 3rd Qu. Max.
# 0.160 2.800 4.240 4.972 6.640 29.200
# Scelgo la scala (tenendo conto delle uscite)
h = max(hist(x,probability=TRUE,right=FALSE,
col="grey",n=30,plot=FALSE)$density )
Plane(0,max(x)*1.05, 0,h*1.05)
hist(x,probability=TRUE,right=FALSE,col="grey",
n=30,add=TRUE)
|
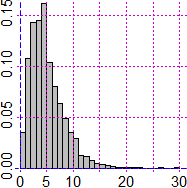 |
Posso osservare dall'istogramma che 2.8 è un valore abbastanza centrale. Calcolando anche i percentili trovo che 2.8 è il 25° percentile (o primo quartile o quantile di ordine 0.25), cioè il limite sinistro del 50% centrale dei dati. Quindi posso ritenere plausibile (cioè non rifiutare) l' ipotesi che il dado sia equo. Se avessi ottenuto un valore verso la coda sinistra o quella destra avrei invece dovuto avere dubbi su tale ipotesi: se è verso la coda destra si tratta di un valore molto alto, che fa supporre che il dado non sia equo; se è verso la coda sinistra si tratta di un valore molto basso, ma un po' troppo "perfetto", che può far supporre che ci sia stato qualche errore (o qualche "imbroglio") nel riportare le frequenze. In tali casi, prima di scartare l'ipotesi, sarebbe stato opportuno, se possibile, ripetere i lanci, ricalcolare χ² e valutare la posizione del nuovo valore rispetto all'istogramma sopra riprodotto (o rispetto ai quantili).
Nel caso di un'altra legge di distribuzione L, altre classi o un altro numero n di prove , ad esempio nel caso dell'esempio iniziale, potrei procedere analogamente. In genere, tuttavia, si preferisce utilizzare un procedimento standard di tipo generale, che ha come retroterra il fatto che si può dimostrare che, se il numero n delle prove è sufficientemente grande, la legge di distribuzione teorica di χ² è praticamente indipendente dalla legge di distribuzione L:
per n tendente all'infinito tende a una legge χ²(r) che dipende solo dal numero r dei gradi di libertà, cioè dalla quantità delle frequenze sperimentali che devo conoscere direttamente.
Spieghiamo meglio il concetto di "grado di libertà" con alcuni esempi.
Nel caso del dado sopra considerato, sappiamo che le frequenze FrOs1, FrOs2, …, FrOs6 devono avere come somma n. Questa connessione fa sì che note 5 frequenze la rimanente sia determinata automaticamente. Questa connessione è presente in tutti i casi. Quindi i gradi di libertà sono in ogni caso al più nc−1 (nc = numero delle classi).
Nel caso di una variabile casuale a valori reali positivi,
se FrOs1,…, FrOs16 sono le frequenze osservate nei 16 intervalli [0,5), [5,10), …
e voglio operare il confronto con la densità esponenziale
Se, invece, come w avessi scelto un valore stabilito a priori, non dipendente dai dati sperimentali, non avrei avuto la connessione Σ xi FrOsi / n = M, e i gradi di libertà sarebbero stati 15.
L'espressione di χ²(r) non è facile da descrivere né da comprendere (non è una delle cosiddette
funzioni "elementari": vedi Complementi di analisi matematica). Comunque nel software matematico in genere è definita
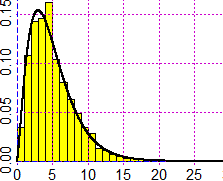
e richiamabile con degli opportuni comandi. In R la funzione densità della legge χ²(r) è calcolabile
con la funzione che ad x associa dchisq(x, r) ("sq" sta per "square"). f = function(x) dchisq(x, 5); graph2(f, 0,30, "black") |
 |
Se mi interessano i quantili (o percentili) della legge χ² uso, invece, qchisq(x, r). Vediamo qual è il quantile di ordine 0.25 (o 25º percentile) nel caso del dado equo: con qchisq(0.25,df=5) ottengo 2.674603. Ritrovo che 2.8 è circa il quantile di ordine 0.25 (ossia il 25º percentile).
Se, viceversa, mi interessa la funzione di distribuzione (o ripartizione), che ad x associa la probabilità che χ² sia minore di x (ovvero che ad x associa l'ordine del quantile che vale x), uso pchisq(x, r). Vediamo qual è l'ordine del quantile che nel caso del dado equo vale 2.8 con pchisq(2.8,df=5) ottengo 0.2692135. Trovo che 2.8 è il quantile di ordine 0.27 (ossia il 27º percentile): la probabilità che il χ² si minore di 2.8 è 0.27.
Confrontiamo i valori ottenuti sopra con summary(x) con quelli ottenibili con qchisq e con dchisq:
qchisq(c(0.25, 0.50, 0.75), df=5) # 2.674603 4.351460 6.625680 25°,50°,75° percentile f = function(x) dchisq(x, 5)*x integral(f, 0,Inf) # 5 il valor medio
Ecco, arrotondati a due cifre; i valori per diversi gradi di libertà (ottenuti coi comandi riportati qui):
gl 5 10 25 50 75 90 95 1 0.0039 0.016 0.1 0.45 1.3 2.7 3.8 2 0.1 0.21 0.58 1.4 2.8 4.6 6 3 0.35 0.58 1.2 2.4 4.1 6.3 7.8 4 0.71 1.1 1.9 3.4 5.4 7.8 9.5 5 1.1 1.6 2.7 4.4 6.6 9.2 11 10 3.9 4.9 6.7 9.3 13 16 18 20 11 12 15 19 24 28 31 50 35 38 43 49 56 63 68 100 78 82 90 99 110 120 120 |
Tornando al nostro dado, se come χ² invece di 2.8 (che è intorno al 25° percentile e quindi è abbastanza "normale") avessimo ottenuto 13 avremmo dovuto manifestare qualche dubbio sul fatto che il dado sia equo: c'è una discordanza molto alta rispetto alla legge uniforme: il 95° percentile è 11.1.
Ma anche se avessimo ottenuto una discordanza molto bassa, ad esempio χ²<1, avremmo dovuto avere dei dubbi sulla equità del dado o sulla attendibilità dei dati fornitici: è improbabile che si ottenga un valore inferiore a 1 (la probabilità è inferiore al 4%, infatti pchisq(1, 5) = 0.037).
Nell'usare la distribuzione del χ² limite occorre prestare qualche attenzione: occorre che le prove siano numerose (diciamo, almeno un centinaio); occorre, inoltre, che in ogni classe cadano abbastanza valori (diciamo, almeno 5); se in qualche classe cadono poche osservazioni è opportuno unire questa classe ad un'altra.
Accanto a questi usi del test χ² esitono altri impieghi dei test statistici. Qui puoi vederne qualche esempio.
|
5. Esercizi
| 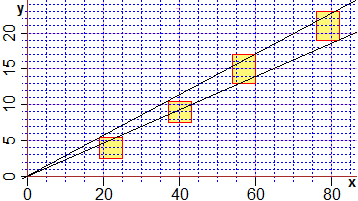 |
| I comandi seguenti tracciano gli esiti dello studio sperimentale del legame tra due grandezze x e y che sappiamo essere legate da una relazione lineare. Delle misure effettuate non disponiamo della precisione (possiamo dunque assumere che esse siano ad alta sensibilità). Quali ipotesi faccio se le approssimo con la retta R1, quali se le approssimo con la retta R2? (esplicita l'espressione di R1 ed R2 e rappresentale graficamente, assieme ai punti) |
|
X = c(22,40,57,79); Y = c(4,9,15,21) Plane(0,80, 0,22); POINT(X,Y,"brown") LR0(X,Y,0,0) f = function(x) LR0(X,Y,0,0)[1] + LR0(X,Y,0,0)[2]*x; graph1(f,0,80,"seagreen") LR(X,Y) g = function(x) LR(X,Y)[1] + LR(X,Y)[2]*x; graph1(g, 0,80,"blue")) |
| Considera i dati x e y dell'esercizio precedente, che sono anche i valori centrali degli intervalli che rappresentano le approssimazioni dell'esercizio 1. Determina l'intervallo di confidenza al 90% di H tale che y = H·x e quello al 95%, e confronta i valori ottenuti con quelli dell'esercizio 1, in cui disponevamo delle precisioni di x ed y. |
|
Considera i dati x e y degli esercizi precedenti. Determina il coefficiente di regressione tra x ed y e un suo intervallo
di confidenza al 90%. |
|
In un esperimento sulla crescita del grano durante l'inverno si registrano la temperatura media
(in °C) del suolo ad una profondità di 8 cm e i giorni necessari per la germogliazione.
Qual è la correlazione tra temperatura del suolo e tempo necessario per la germogliazione? Determinane un intervallo di
confidenza al 95%. T = c(5,5.5,6,6.5,7,7.5,8,8.5); g = c(40,36,32,27,23,19,19,20) | |||||
| x = c(0.1,0.9,1.6,2.0,2.9) e y = c(-29.9,-11.4,-7.1,-3.8,10.2) sono sono i dati relativi ad una grandezza (y) in funzione di un'altra (x). Determina, mediante regressioni polinomiali, una funzione polinomiale di 2º grado ed una di 3º grado che approssimino i dati. |
|
Un amico mi dice: Questa moneta è equa. Infatti su 1000 lanci ho ottenuto 499 "testa" e 501 "croce".
Che cosa posso concludere sulla verosimiglianza di quanto raccontato dall'amico? Suggerimento: completa FrOs <– c(..., ...); Prob <– c(..., ...); n <– sum(FrOs); FrAt <– Prob*n; sum( (FrOs-FrAt)^2/FrAt ) e confronta con i valori che ottieni con qchisq( ..., df=1) |
| Un amico mi dice: Questa moneta è equa. Infatti su 1000 lanci ho ottenuto 470 "testa" e 530 "croce". Come valuti la conclusione di questo amico? |
|  |
|
1) Segna con l'evidenziatore, nelle parti della scheda indicate, frasi e/o formule che descrivono il significato dei seguenti termini: coeffciente di correlazione (§2) minimi quadrati (§2) retta di regressione (§2) intervallo di confidenza (§2) regressione polinomiale (§3) χ² (§4) gradi di libertà (§4) 2) Su un foglio da "quadernone", nella prima facciata, esemplifica l'uso di ciascuno dei concetti sopra elencati mediante una frase in cui esso venga impiegato. 3) Nella seconda facciata riassumi in modo discorsivo (senza formule, come in una descrizione "al telefono") il contenuto della scheda (non fare un elenco di argomenti, ma cerca di far capire il "filo del discorso"). |