uno due tre quattro
cinque sei sette
Attività con R - 1
[righe da eseguire, tra un "#" e l'altro]
1/3
# 0.3333333
print(1/3, 15); print(1/3, 16); print(1/3, 17); print(1/3, 18)
# 0.333333333333333 0.3333333333333333 0.33333333333333331 0.333333333333333315
# come mai queste uscite?
x <- 5555.1251; y <- 5555; x-y
# 0.1251
print(x-y, 16)
# 0.1251000000002023
# come mai queste?
# Col cellulare 1/3*3 fa 0.9999999
13/124+4/80
# 0.1548387
library(MASS)
# che cos'è una "libreria"
fractions(13/124+4/80)
# 24/155
fractions(1255.255255255255255255)
# 418000/333
fractions( 2.59807621135332/sqrt(3) )
# 3/2
# Deduco che 2.59807621135332 = 3√3/2
3+sqrt(-0.25)
# In sqrt(-0.25) : Si č prodotto un NaN
# NAN: not a number
3+sqrt(-0.25+0i)
# 3+0.5i
# i numeri complessi
#
as.roman(178); as.roman(179); as.roman(999)
# Only numbers between 1 and 3899 have a representation as roman numbers
# CLXXVIII CLXXIX CMXCIX
#
factorial(21)
# 5.109094e+19
fractions(factorial(21)); fractions(factorial(22))
# 51090942171709440000 1.12400072777761e+21
# come effettuare il "calcolo esatto" (fino ad un certo ordine di grandezza)
#
# http://www.wolframalpha.com
# 2.59807621135332
# sqrt(3)/2
# 13/124+4/80
# 3+sqrt(-0.25)
# Is 5^(1/3) a rational number?
# Is pi^sqrt(2) a rational number?
# roman(999)
# 22!
#
c( choose(7,0), choose(7,1), choose(7,2), choose(7,3) )
choose(7,0:7)
# 1 7 21 35
> choose(7,0:7)
# 1 7 21 35 35 21 7 1
# il ":" ...
#
2 < 5; 5 >= 2; 5 == 2; 5 = 2
# TRUE TRUE FALSE Errore in 5 = 2
!(1 > 2 & (3/2 < 2 | 1 == 0))
# TRUE
1 > 2 & (3/2 < 2 | 1 == 0)
# FALSE
1 > 2
# FALSE
3/2 < 2 | 1 == 0
# TRUE
3/2 < 2
# TRUE
1 == 0
# FALSE
# gli operatori "logici" e l'"=" nelle condizioni
#
k <- 2; t <- 1
p <- function(x) (x^2+x+1)^2 + 1/(x^2+x+1) + x^2+x+1
q <- function(x) {t <- x^2+x+1; t^k + 1/t + t}
p(7); q(7)
# 3306.018 3306.018
t; k
# 1 2
# nella definizione di q ho usato la variabile t come variabile locale (il
# valore che assume non interferisce col valore che t ha assunto prima della
# definizione, in cui era globale, come globale è la varabile k); x è invece
# un parametro formale (è usato per definire q; anch'esso non interferisce
# coi valori assunti da eventuali usi di x al di fuori della definizione di q)
#
f <- function(x) ifelse( x>= 2, -4, 6)
plot(f,-5,5); abline(h=0,v=0,col="red")
#
plot(f,-5,5,type="p"); abline(h=0,v=0,col="red")
#
plot(f,-5,5,type="p",pch="."); abline(h=0,v=0,col="red")
#
plot(f,-5,5,type="p",pch=".",n=1e4); abline(h=0,v=0,col="red")
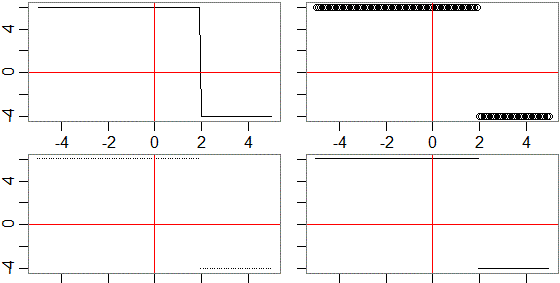 #
# http://www.wolframalpha.com
# y = Piecewise[ { {-4, x >= -2}, {6, x < -2} } ]
# Per avere il grafico in un particolare intervallo:
# plot Piecewise[ { {-4, x >= -2}, {6, x < -2} } ], -8 <= x <= 8
# ovvero:
# plot Piecewise[ { {-4, x >= -2}, {6, x < -2} } ], -8 <= x <= 8, -7 <= y <= 9
#
readLines("http://macosa.dima.unige.it/om/prg/stf/altomas.txt",n=3)
# vedo che cos'è un file, stampandone poche righe,
# "'record alto maschi dal 32 ogni 4 anni" "1932,203"
# "1936,207"
read.table("http://macosa.dima.unige.it/om/prg/stf/altomas.txt",sep=",",skip=1, nrows=2)
# V1 V2
# 1 1932 203
# 2 1936 207
# poi, se vedo che è una tabella, ne carico le righe indicando il separatore
hm <- read.table("http://macosa.dima.unige.it/om/prg/stf/altomas.txt",sep=",",skip=1)
str(hm)
# 'data.frame': 20 obs. of 2 variables:
# $ V1: int 1932 1936 1940 1944 1948 1952 1956 1960 1964 1968 ...
# $ V2: int 203 207 209 211 211 211 215 222 228 228 ...
#
# Sono pochi dati: posso visualizzarli
edit(hm)
#
hm
# V1 V2
# 1 1932 203
# ...
# 20 2008 245
write.csv(hm,"hm.csv")
# come scrivere una tabella in formato foglio di calcolo
# (cercare il file sul computer: potrebbe essere nella cartella
# Documenti, sul DeskTop, ...)
#
plot(hm)
hf <- read.table("http://macosa.dima.unige.it/om/prg/stf/altofem.txt",sep=",",skip=1)
windows() # apro una nuova finestra
plot(hf)
#
plot(hf,ylim=c(160,250),col="red") # potrei aggiungere: xlim=c(1920,2020)
abline(v=axTicks(1), h=axTicks(2), col="orange",lty=3)
points(hm,col="blue")
lines(hm,col="blue"); lines(hf,col="red")
#
# http://www.wolframalpha.com
# y = Piecewise[ { {-4, x >= -2}, {6, x < -2} } ]
# Per avere il grafico in un particolare intervallo:
# plot Piecewise[ { {-4, x >= -2}, {6, x < -2} } ], -8 <= x <= 8
# ovvero:
# plot Piecewise[ { {-4, x >= -2}, {6, x < -2} } ], -8 <= x <= 8, -7 <= y <= 9
#
readLines("http://macosa.dima.unige.it/om/prg/stf/altomas.txt",n=3)
# vedo che cos'è un file, stampandone poche righe,
# "'record alto maschi dal 32 ogni 4 anni" "1932,203"
# "1936,207"
read.table("http://macosa.dima.unige.it/om/prg/stf/altomas.txt",sep=",",skip=1, nrows=2)
# V1 V2
# 1 1932 203
# 2 1936 207
# poi, se vedo che è una tabella, ne carico le righe indicando il separatore
hm <- read.table("http://macosa.dima.unige.it/om/prg/stf/altomas.txt",sep=",",skip=1)
str(hm)
# 'data.frame': 20 obs. of 2 variables:
# $ V1: int 1932 1936 1940 1944 1948 1952 1956 1960 1964 1968 ...
# $ V2: int 203 207 209 211 211 211 215 222 228 228 ...
#
# Sono pochi dati: posso visualizzarli
edit(hm)
#
hm
# V1 V2
# 1 1932 203
# ...
# 20 2008 245
write.csv(hm,"hm.csv")
# come scrivere una tabella in formato foglio di calcolo
# (cercare il file sul computer: potrebbe essere nella cartella
# Documenti, sul DeskTop, ...)
#
plot(hm)
hf <- read.table("http://macosa.dima.unige.it/om/prg/stf/altofem.txt",sep=",",skip=1)
windows() # apro una nuova finestra
plot(hf)
#
plot(hf,ylim=c(160,250),col="red") # potrei aggiungere: xlim=c(1920,2020)
abline(v=axTicks(1), h=axTicks(2), col="orange",lty=3)
points(hm,col="blue")
lines(hm,col="blue"); lines(hf,col="red")
 #
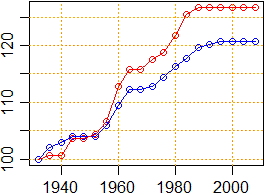
indm <- hm$V2/hm$V2[1]*100; indf <- hf$V2/hf$V2[1]*100
# estraggo righe/colonne da una tabella
plot(hf$V1,indf,col="red")
abline(v=axTicks(1), h=axTicks(2), col="orange",lty=3)
points(hm$V1,indm,col="blue")
lines(hm$V1,indm,col="blue")
lines(hf$V1,indf,col="red")
#
indm <- hm$V2/hm$V2[1]*100; indf <- hf$V2/hf$V2[1]*100
# estraggo righe/colonne da una tabella
plot(hf$V1,indf,col="red")
abline(v=axTicks(1), h=axTicks(2), col="orange",lty=3)
points(hm$V1,indm,col="blue")
lines(hm$V1,indm,col="blue")
lines(hf$V1,indf,col="red")
 #
ls()
# l'elenco di tutte le variabili in uso
rm(hm,t)
ls()
# l'elenco dopo avere rimosso hm e t
rm(list=ls())
ls()
# e dopo averle rimosse tutte
#
x <- c(10.4, 5.6, 3.1, 6.4, 21.7); x
# 10.4 5.6 3.1 6.4 21.7
length(x); min(x); max(x); range(x); sort(x); mean(x); median(x); sum(x); prod(x)
# 5 3.1 21.7 3.1 21.7 3.1 5.6 6.4 10.4 21.7 9.44 6.4 47.2 25073.95
#
seq(3,10,len=4); seq(6,10,0.5)
# 3.000000 5.333333 7.666667 10.000000
# 6.0 6.5 7.0 7.5 8.0 8.5 9.0 9.5 10.0
length(seq(6,10,0.5))
# 9
# un modo per costruire sequenze
#
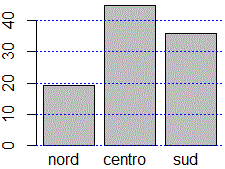
dati <- c(315.5, 732.3, 586.7); barplot(dati)
# un istogramma a barre
# come aggiungervi delle etichette:
windows()
names(dati) <- c("nord","centro","sud"); barplot(dati)
windows()
barplot(dati/sum(dati)*100)
abline(h=axTicks(2), col="blue",lty=3)
#
ls()
# l'elenco di tutte le variabili in uso
rm(hm,t)
ls()
# l'elenco dopo avere rimosso hm e t
rm(list=ls())
ls()
# e dopo averle rimosse tutte
#
x <- c(10.4, 5.6, 3.1, 6.4, 21.7); x
# 10.4 5.6 3.1 6.4 21.7
length(x); min(x); max(x); range(x); sort(x); mean(x); median(x); sum(x); prod(x)
# 5 3.1 21.7 3.1 21.7 3.1 5.6 6.4 10.4 21.7 9.44 6.4 47.2 25073.95
#
seq(3,10,len=4); seq(6,10,0.5)
# 3.000000 5.333333 7.666667 10.000000
# 6.0 6.5 7.0 7.5 8.0 8.5 9.0 9.5 10.0
length(seq(6,10,0.5))
# 9
# un modo per costruire sequenze
#
dati <- c(315.5, 732.3, 586.7); barplot(dati)
# un istogramma a barre
# come aggiungervi delle etichette:
windows()
names(dati) <- c("nord","centro","sud"); barplot(dati)
windows()
barplot(dati/sum(dati)*100)
abline(h=axTicks(2), col="blue",lty=3)
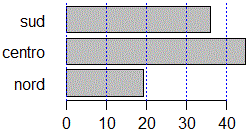
 windows()
barplot(dati/sum(dati)*100,horiz=TRUE)
abline(v=axTicks(1), col="blue",lty=3)
windows()
# come orientare le "etichette" sugli assi
barplot(dati/sum(dati)*100,horiz=TRUE,las=1)
abline(v=axTicks(1), col="blue",lty=3)
windows()
barplot(dati/sum(dati)*100,horiz=TRUE)
abline(v=axTicks(1), col="blue",lty=3)
windows()
# come orientare le "etichette" sugli assi
barplot(dati/sum(dati)*100,horiz=TRUE,las=1)
abline(v=axTicks(1), col="blue",lty=3)
 #
# Come cercare queste cose nell'indice per voci
# Esempi d'uso di WolframAlpha: apri "software" qui
# (poi apri "clicca").
# Per come vengono approssimati i numeri, vedi qui.
# Domande, problemi, ... ?
#
# (vedremo una prossima volta come salvare/caricare sessioni di lavoro)
#
#
# Come cercare queste cose nell'indice per voci
# Esempi d'uso di WolframAlpha: apri "software" qui
# (poi apri "clicca").
# Per come vengono approssimati i numeri, vedi qui.
# Domande, problemi, ... ?
#
# (vedremo una prossima volta come salvare/caricare sessioni di lavoro)
#
Attività con R - 2
# Schiacciando il tasto freccia ^ [v] si rivedono preced. [segu.] comandi.
# Quanto fatto può essere memorizzato usando il comando Save History
# e dandogli un nome (con estensione ".Rhistory"). Il file può essere
# ricaricato con Load History e può essere esaminato o caricato con i
# tasti freccia, come detto sopra.
#
# Per esamiare alcune funzioni incorporate si puo' guardare uno dei vari
# help; ad es. selezionare "R functions (text)" [o "Funzioni di R (testo)],
# mettere "sqrt" come parola da cercare; si apre "MathFun {base}" e da qui
# si seleziona "Math". Si può usare anche "Search Engine & Keywords"
# attivabile da "Html Help" ("Guida Html"), e, soprattutto, sempre da
# "Html Help", aprire "Packages" e, quindi, "Base" e "Graphics".
# Si tratta, comunque, di help non "facili". Battendo il comando
# help(sqrt) si entra direttamente nell'help di sqrt (se non sei in rete
# potrebbe essere azionabile solo "Search Help" - "Cerca nella Guida").
#
# I grafici di tre funzioni a 1 input e 1 output con curve (con cui non è
# necessario - ma è possibile - specificare il dominio) e l'opzione add (ci
# sono anche altri modi per ottenerli) e plot (qui solo) per scegliere la scala:
# la 2ª riga riserva lo spazio per il rettangolo con ascissa da -5 a 5 e
# ordinata da -5 ad 8 e non lo traccia (type="n"), e non mette etichette agli
# assi (xlab="", ylab=""); con fg="white" non traccio il box, con xaxt="n",
# yaxt="n" ascisse/ordinate. I comandi sono copiabili facilmente e modificabili.
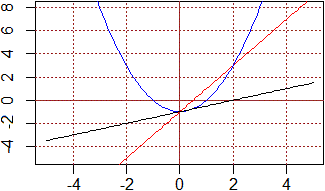
f <- function(x) x*2-1; g <- function(x) x^2-1; h <- function(x) x/2-1
plot(c(-5,5),c(-5,8),type="n",xlab="", ylab="")
abline(h=0,v=0,col="brown"); abline(v=axTicks(1), h=axTicks(2), col="brown",lty=3)
curve(f, add=TRUE,col="red"); curve(g, add=TRUE,col="blue"); curve(h,add=TRUE)
 #
plot(c(-5,5),c(-5,8),type="n",xlab="", ylab="",fg="white")
abline(h=0,v=0,col="brown"); abline(v=axTicks(1), h=axTicks(2), col="brown",lty=3)
#
plot(c(-5,5),c(-5,8),type="n",xlab="", ylab="",fg="white",xaxt="n",yaxt="n")
abline(h=0,v=0,col="brown"); abline(v=axTicks(1), h=axTicks(2), col="brown",lty=3)
#
plot(c(-5,5),c(-5,8),type="n",xlab="", ylab="",fg="white")
abline(h=0,v=0,col="brown"); abline(v=axTicks(1), h=axTicks(2), col="brown",lty=3)
#
plot(c(-5,5),c(-5,8),type="n",xlab="", ylab="",fg="white",xaxt="n",yaxt="n")
abline(h=0,v=0,col="brown"); abline(v=axTicks(1), h=axTicks(2), col="brown",lty=3)
 #
# Una definizione per ricorsione:
A <- 90000
F <- function(n) if (n==0) 1 else (Recall(n-1)+A/Recall(n-1))/2
# ovvero: F <- function(n) if (n==1) 1 else (Recall(n-1)+A/Recall(n-1))/2
F(1); F(2); F(10); F(11); F(12)
# 45000.5 22501.25 300.6514 300.0007 300
A <- 1024; F(9); F(10)
# 32 32
# Che cosa calcola F?
# x(0)=1, x(n+1) = ( x(n) + A/x(n) ) / 2 (che converge a ...)
#
# Se un comando e' lungo si puo' scriverlo tutto su una stessa riga fino
# a qualche migliaio di caratteri o si puo' andare a capo: la riga seguente
# è interpretata come continuazione (sullo schermo è aggiunto automaticamente
# un "+" all'inizio della nuova riga). Un esempio:
dati <- c(1, 2, 3, 4, 5, 6, 7, 8, 9,10,11,12,13,14,15,16,17,18,19,20,
21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40)
mean(dati)
# 20.5
#
# generazione di alcune sequenze di numeri interi:
s <- 5:11; s; 5:11-1; 5:(11-1); 11:5; s/2
# 5 6 7 8 9 10 11
# 4 5 6 7 8 9 10
# 5 6 7 8 9 10
# 11 10 9 8 7 6 5
# 2.5 3.0 3.5 4.0 4.5 5.0 5.5
# più in generale:
seq(6); seq(3,9); seq(3,10,0.8); seq(3,10,len=4); seq(3,by=0.8,len=6)
# 1 2 3 4 5 6 3 4 5 6 7 8 9 3.0 3.8 4.6 5.4 6.2 7.0 7.8 8.6 9.4
# 3.000000 5.333333 7.666667 10.000000 3.0 3.8 4.6 5.4 6.2 7.0
# modi per ripetere più volte dei dati:
x <- c(3.1, 6.4, 21.7); c(7,rep(x, 4)); c(7,rep(x, each=4))
# 7.0 3.1 6.4 21.7 3.1 6.4 21.7 3.1 6.4 21.7 3.1 6.4 21.7
# 7.0 3.1 3.1 3.1 3.1 6.4 6.4 6.4 6.4 21.7 21.7 21.7 21.7
#
# analisi dei dati relativi ad un gruppo di alunne quindicenni (altezze in cm)
alu <- c(156,168,162,150,167,157,170,157,159,164,157,165,163,165,166,160,163,162,155)
length(alu); sort(alu); mean(alu); median(alu)
# 19
# 150 155 156 157 157 157 159 160 162 162 163 163 164 165 165 166 167 168 170
# 161.3684
# 162
# Stem-and-leaf plot (o, in breve, stem plot). La cifra indicata nella
# prima colonna č il "gambo" (stem) del singolo dato, la cifra rimanente
# è la "foglia" (leaf); per ogni gambo ci possono essere più foglie
# (dati classificati nella stessa classe).
stem(alu)
# 15 | 0
# 15 | 567779
# 16 | 022334
# 16 | 55678
# 17 | 0
# un modo per contare le lunghezze delle colonne, anche parziali
stem(alu, width = 0); stem(alu, width = 2)
# 15 | +1
# 15 | +6
# 16 | +6
# 16 | +5
# 17 | +1
#
# 15 |
# 15 | +4
# 16 | +4
# 16 | +3
# 17 |
# come scegliere intervalli diversi (lo standard equivale a scale=1)
stem(alu,scale=0.5); stem(alu,scale=3)
# 15 | 0567779
# 16 | 02233455678
# 17 | 0
#
# 150 | 0
# 152 |
# 154 | 0
# 156 | 0000
# 158 | 0
# 160 | 0
# 162 | 0000
# 164 | 000
# 166 | 00
# 168 | 0
# 170 | 0
#
#
# Una definizione per ricorsione:
A <- 90000
F <- function(n) if (n==0) 1 else (Recall(n-1)+A/Recall(n-1))/2
# ovvero: F <- function(n) if (n==1) 1 else (Recall(n-1)+A/Recall(n-1))/2
F(1); F(2); F(10); F(11); F(12)
# 45000.5 22501.25 300.6514 300.0007 300
A <- 1024; F(9); F(10)
# 32 32
# Che cosa calcola F?
# x(0)=1, x(n+1) = ( x(n) + A/x(n) ) / 2 (che converge a ...)
#
# Se un comando e' lungo si puo' scriverlo tutto su una stessa riga fino
# a qualche migliaio di caratteri o si puo' andare a capo: la riga seguente
# è interpretata come continuazione (sullo schermo è aggiunto automaticamente
# un "+" all'inizio della nuova riga). Un esempio:
dati <- c(1, 2, 3, 4, 5, 6, 7, 8, 9,10,11,12,13,14,15,16,17,18,19,20,
21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40)
mean(dati)
# 20.5
#
# generazione di alcune sequenze di numeri interi:
s <- 5:11; s; 5:11-1; 5:(11-1); 11:5; s/2
# 5 6 7 8 9 10 11
# 4 5 6 7 8 9 10
# 5 6 7 8 9 10
# 11 10 9 8 7 6 5
# 2.5 3.0 3.5 4.0 4.5 5.0 5.5
# più in generale:
seq(6); seq(3,9); seq(3,10,0.8); seq(3,10,len=4); seq(3,by=0.8,len=6)
# 1 2 3 4 5 6 3 4 5 6 7 8 9 3.0 3.8 4.6 5.4 6.2 7.0 7.8 8.6 9.4
# 3.000000 5.333333 7.666667 10.000000 3.0 3.8 4.6 5.4 6.2 7.0
# modi per ripetere più volte dei dati:
x <- c(3.1, 6.4, 21.7); c(7,rep(x, 4)); c(7,rep(x, each=4))
# 7.0 3.1 6.4 21.7 3.1 6.4 21.7 3.1 6.4 21.7 3.1 6.4 21.7
# 7.0 3.1 3.1 3.1 3.1 6.4 6.4 6.4 6.4 21.7 21.7 21.7 21.7
#
# analisi dei dati relativi ad un gruppo di alunne quindicenni (altezze in cm)
alu <- c(156,168,162,150,167,157,170,157,159,164,157,165,163,165,166,160,163,162,155)
length(alu); sort(alu); mean(alu); median(alu)
# 19
# 150 155 156 157 157 157 159 160 162 162 163 163 164 165 165 166 167 168 170
# 161.3684
# 162
# Stem-and-leaf plot (o, in breve, stem plot). La cifra indicata nella
# prima colonna č il "gambo" (stem) del singolo dato, la cifra rimanente
# è la "foglia" (leaf); per ogni gambo ci possono essere più foglie
# (dati classificati nella stessa classe).
stem(alu)
# 15 | 0
# 15 | 567779
# 16 | 022334
# 16 | 55678
# 17 | 0
# un modo per contare le lunghezze delle colonne, anche parziali
stem(alu, width = 0); stem(alu, width = 2)
# 15 | +1
# 15 | +6
# 16 | +6
# 16 | +5
# 17 | +1
#
# 15 |
# 15 | +4
# 16 | +4
# 16 | +3
# 17 |
# come scegliere intervalli diversi (lo standard equivale a scale=1)
stem(alu,scale=0.5); stem(alu,scale=3)
# 15 | 0567779
# 16 | 02233455678
# 17 | 0
#
# 150 | 0
# 152 |
# 154 | 0
# 156 | 0000
# 158 | 0
# 160 | 0
# 162 | 0000
# 164 | 000
# 166 | 00
# 168 | 0
# 170 | 0
#
Si può dimostrare che la successione A(0)=1, A(n+1) = (A(n) + k/A(n)) / 2, con k > 0,
convege a √k. Questo è un efficientissimo algoritmo per calcolare
la radice quadrata di un numero che risale agli antichi babilonesi. Ha
come idea originale la seguente osservazione: se A è una approssimazione per eccesso
[difetto] di √k allora k/A ne è una approssimazione per difetto [eccesso]
(da A > √k segue che k/A < √k), e quindi come migliore approssimazione
si può prendere la media artitmetica, (A+k/A)/2, di tali approssimazioni.
Attività con R - 3
# Riprendiamo la
# analisi dei dati relativi ad un gruppo di alunne quindicenni (altezze in cm)
alu <- c(156,168,162,150,167,157,170,157,159,164,157,165,163,165,166,160,163,162,155)
length(alu); min(alu); max(alu); mean(alu); median(alu)
# abbiamo visto come, col comando scale (con un numero maggiore o minore di 1)
# si possono ottenere diversi "stem-and-leaf" plot
stem(alu,scale=3); stem(alu)
#
# Vediamo, ora, come ottenere istogrammi piů articolati.
# Con seq (scelto un certo intervallo (da 140 a 180) e l'ampiezza (5) delle
# classi in cui suddividerlo) decido se classificare i dati in intervalli del
# tipo [.,.) - right=FALSE - come fa automaticamente lo stem, o del tipo
# (.,.] - right=TRUE (noi sceglieremo sempre il 1º tipo):
hist(alu, seq(140,180,5), right=FALSE)
windows(); hist(alu, seq(140,180,5), right=TRUE)
 # Ho fatto gli istogrammi in due finestre diverse, che posso spostare o
# ridimensionare. Chiudiamole entrambe cliccando [x].
#
# Ecco l'istogramma in intervalli di altra ampiezza, colorato, senza scritte
# (con main posso inserire un titolo alternativo, anche 'vuoto'):
hist(alu,seq(150,171,3),right=FALSE,col="yellow",xlab="",ylab="",main="")
# Ho fatto gli istogrammi in due finestre diverse, che posso spostare o
# ridimensionare. Chiudiamole entrambe cliccando [x].
#
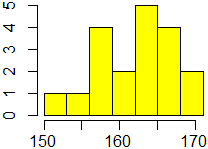
# Ecco l'istogramma in intervalli di altra ampiezza, colorato, senza scritte
# (con main posso inserire un titolo alternativo, anche 'vuoto'):
hist(alu,seq(150,171,3),right=FALSE,col="yellow",xlab="",ylab="",main="")
 #
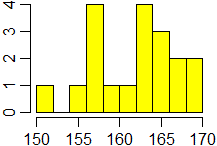
# Posso ridurre il margine dei grafici usando il comando par (PARametri grafici)
# con l'opzione mai (MArgini Interni, in pollici). Posso far gestire al software
# l'istogramma specificando con nclass più o meno in quanti intervalli
# classificare i dati [viene scelto un n. di classi tale che esse siano ampie 1,
# 2 o 5 volte una potenza di 10]:
par( mai = c(0.5,0.5,0.1,0.1) )
hist(alu,nclass=8,right=FALSE,col="yellow",xlab="",main="")
#
# Posso ridurre il margine dei grafici usando il comando par (PARametri grafici)
# con l'opzione mai (MArgini Interni, in pollici). Posso far gestire al software
# l'istogramma specificando con nclass più o meno in quanti intervalli
# classificare i dati [viene scelto un n. di classi tale che esse siano ampie 1,
# 2 o 5 volte una potenza di 10]:
par( mai = c(0.5,0.5,0.1,0.1) )
hist(alu,nclass=8,right=FALSE,col="yellow",xlab="",main="")
 #
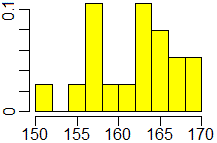
# Aggiungendo l'opzione probability=TRUE (o freq=FALSE) posso rappresentare le
# densità, ossia il rapporto tra le frequenze e le ampiezze delle classi:
hist(alu,nclass=8,right=FALSE,col="yellow",xlab="",main="",probability=TRUE)
#
# Aggiungendo l'opzione probability=TRUE (o freq=FALSE) posso rappresentare le
# densità, ossia il rapporto tra le frequenze e le ampiezze delle classi:
hist(alu,nclass=8,right=FALSE,col="yellow",xlab="",main="",probability=TRUE)
 #
# Posso far tracciare anche l'istogramma in classi di diverse ampiezze (sulla
# scala verticale appare la densitŕ; perché?); devo scegliere in ogni caso
# l'ultimo estremo maggiore strettamente del massimo (170 nel nostro caso)
# per avere un istogramma "corretto".
hist(alu,c(150,156,159,162,168,171),right=FALSE,xlab="",main="")
#
# Posso far tracciare anche l'istogramma in classi di diverse ampiezze (sulla
# scala verticale appare la densitŕ; perché?); devo scegliere in ogni caso
# l'ultimo estremo maggiore strettamente del massimo (170 nel nostro caso)
# per avere un istogramma "corretto".
hist(alu,c(150,156,159,162,168,171),right=FALSE,xlab="",main="")
 #
# Ritorneremo, la prossima volta, su quali strumenti utlilizzare per analizzare
# dati come questi. Ora vediamo l'uso di runif, il generatore di numeri
# (pseudo)casuali
runif(1); runif(1); runif(1)
# 0.6115563 0.4677434 0.9898502
#
# vengono generati numeri con valori "casuali" tra 0 ed 1 (che sono
# uniformemente distribuiti, ossia che tendono ad avere la stessa frequenza
# in sottointervalli di eguale ampiezza; tra 0 e 1/3 e tra 2/3 ed 1 abbiamo
# percentuali di uscite che tendono ad eguagliarsi).
# Con runif posso ottenere altri valori casuali, ad es. relativi al lancio
# di un dado (floor è la parte intera):
floor(runif(1)*6)+1; floor(runif(1)*6)+1; floor(runif(1)*6)+1
# 4 2 6
#
# Opzioni: runif(7) o runif(3,min=1,max=7) generano 7 "numeri casuali" tra
# 0 ed 1 o 3 tra 1 e 7. Ecco come ottenere 25 lanci di un dado equo:
floor(runif(25,min=1,max=7))
# 4 3 5 5 5 1 3 2 3 6 3 1 2 3 2 5 5 1 6 6 6 2 5 2 6
#
# Come faccio a controllare che runif generi uscite uniformemente distribuite?
# Con il seguente comando posso vedere, graficamente, come di distribuiscono
# 1000 uscite di runif
hist(runif(1000))
#
# Se voglio avere le frequenze relative uso il seguente comando, eventualmente
# con probability=TRUE al posto di freq=FALSE
hist(runif(1000),freq=FALSE)
# posso specificare il numero di intervalli:
hist(runif(1000),probability=TRUE,nclass=2)
#
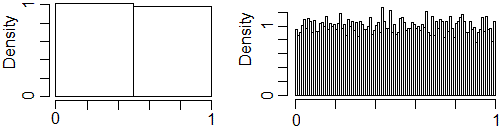
# All'aumentare il numero delle prove l'istogramma tende ad appiattirsi
hist(runif(1e4),probability=TRUE,nclass=2)
#
# ma se aumento il numero delle classi ...
hist(runif(1e4),probability=TRUE,nclass=100)
#
# Ritorneremo, la prossima volta, su quali strumenti utlilizzare per analizzare
# dati come questi. Ora vediamo l'uso di runif, il generatore di numeri
# (pseudo)casuali
runif(1); runif(1); runif(1)
# 0.6115563 0.4677434 0.9898502
#
# vengono generati numeri con valori "casuali" tra 0 ed 1 (che sono
# uniformemente distribuiti, ossia che tendono ad avere la stessa frequenza
# in sottointervalli di eguale ampiezza; tra 0 e 1/3 e tra 2/3 ed 1 abbiamo
# percentuali di uscite che tendono ad eguagliarsi).
# Con runif posso ottenere altri valori casuali, ad es. relativi al lancio
# di un dado (floor è la parte intera):
floor(runif(1)*6)+1; floor(runif(1)*6)+1; floor(runif(1)*6)+1
# 4 2 6
#
# Opzioni: runif(7) o runif(3,min=1,max=7) generano 7 "numeri casuali" tra
# 0 ed 1 o 3 tra 1 e 7. Ecco come ottenere 25 lanci di un dado equo:
floor(runif(25,min=1,max=7))
# 4 3 5 5 5 1 3 2 3 6 3 1 2 3 2 5 5 1 6 6 6 2 5 2 6
#
# Come faccio a controllare che runif generi uscite uniformemente distribuite?
# Con il seguente comando posso vedere, graficamente, come di distribuiscono
# 1000 uscite di runif
hist(runif(1000))
#
# Se voglio avere le frequenze relative uso il seguente comando, eventualmente
# con probability=TRUE al posto di freq=FALSE
hist(runif(1000),freq=FALSE)
# posso specificare il numero di intervalli:
hist(runif(1000),probability=TRUE,nclass=2)
#
# All'aumentare il numero delle prove l'istogramma tende ad appiattirsi
hist(runif(1e4),probability=TRUE,nclass=2)
#
# ma se aumento il numero delle classi ...
hist(runif(1e4),probability=TRUE,nclass=100)
 #
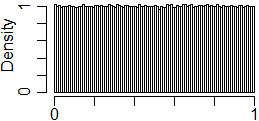
# devo aumnetare il numero delle uscite
hist(runif(1e6),probability=TRUE,nclass=100)
#
# devo aumnetare il numero delle uscite
hist(runif(1e6),probability=TRUE,nclass=100)
 # Approfondiremo più avanti la riflessione su come "tende" ad appiattirsi
#
# Non basta vedere che le uscite di runif tendono ad essere distribuite
# uniformemente. Basti osservare le seguenti uscite:
n <- 8; x <- runif(n); x
# 0.6390126 0.9449126 0.4555639 0.8969478 0.2775830 0.1250314 0.9396591 0.3673091
i <- seq(4,n,4); x[i] <- x[i-2]; x
# 0.6390126 0.9449126 0.4555639 0.9449126 0.2775830 0.1250314 0.9396591 0.1250314
# Si susseguono, via via, coppie di elementi uguali. Ma se li analizzo con
# un istogramma non mi accorgo di questo fatto:
n <- 1e5; x <- runif(n); i <- seq(4,n,4); x[i] <- x[i-2]
hist(x)
# Approfondiremo più avanti la riflessione su come "tende" ad appiattirsi
#
# Non basta vedere che le uscite di runif tendono ad essere distribuite
# uniformemente. Basti osservare le seguenti uscite:
n <- 8; x <- runif(n); x
# 0.6390126 0.9449126 0.4555639 0.8969478 0.2775830 0.1250314 0.9396591 0.3673091
i <- seq(4,n,4); x[i] <- x[i-2]; x
# 0.6390126 0.9449126 0.4555639 0.9449126 0.2775830 0.1250314 0.9396591 0.1250314
# Si susseguono, via via, coppie di elementi uguali. Ma se li analizzo con
# un istogramma non mi accorgo di questo fatto:
n <- 1e5; x <- runif(n); i <- seq(4,n,4); x[i] <- x[i-2]
hist(x)
 # È evidente come la simulazione di un fenomeno con un generatore di
# numeri casuali di questo tipo potrebbe creare grossi problemi.
# Non abbiamo, per ora gli strumenti per mettere a punto come "testare" un
# generatore di numeri casuali. Ci rifletteremo eventualmente più avanti.
#
# Per renderci conto della bontà di runif vediamo solo come di distribuiscono
# coppie di punti con coordinate generate esso. Che cosa ci aspettiamo?
plot(c(0,1),c(0,1),type="n",xlab="", ylab="")
points(runif(1000),runif(1000))
#
# Se voglio aumentare il numero dei punti mi conviene tracciarli puntiformi
plot(c(0,1),c(0,1),type="n",xlab="", ylab="")
points(runif(1000),runif(1000),pch=".")
#
# A questo punto posso aumentare il numero dei punti tracciati:
plot(c(0,1),c(0,1),type="n",xlab="", ylab="")
n <- 1e4; points(runif(n),runif(n),pch=".")
# È evidente come la simulazione di un fenomeno con un generatore di
# numeri casuali di questo tipo potrebbe creare grossi problemi.
# Non abbiamo, per ora gli strumenti per mettere a punto come "testare" un
# generatore di numeri casuali. Ci rifletteremo eventualmente più avanti.
#
# Per renderci conto della bontà di runif vediamo solo come di distribuiscono
# coppie di punti con coordinate generate esso. Che cosa ci aspettiamo?
plot(c(0,1),c(0,1),type="n",xlab="", ylab="")
points(runif(1000),runif(1000))
#
# Se voglio aumentare il numero dei punti mi conviene tracciarli puntiformi
plot(c(0,1),c(0,1),type="n",xlab="", ylab="")
points(runif(1000),runif(1000),pch=".")
#
# A questo punto posso aumentare il numero dei punti tracciati:
plot(c(0,1),c(0,1),type="n",xlab="", ylab="")
n <- 1e4; points(runif(n),runif(n),pch=".")
 #
plot(c(0,1),c(0,1),type="n",xlab="", ylab="")
n <- 1e5; points(runif(n),runif(n),pch=".")
#
# Ma, come fanno ad essere casuali le uscite generate da un computer?
# Ci rifletteremo su la prossima volta.
#
#
plot(c(0,1),c(0,1),type="n",xlab="", ylab="")
n <- 1e5; points(runif(n),runif(n),pch=".")
#
# Ma, come fanno ad essere casuali le uscite generate da un computer?
# Ci rifletteremo su la prossima volta.
#
Attività con R - 4
# PARENTESI - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
# Che cos'è una successione casuale? Una possibile definizione (Chaitin, 1962).
# (spiegazione e definizione a livello "adulto")
#
# Idea intuitiva: una sequenza finita di caratteri è più "casuale" di un'altra di
# uguale lunghezza se può essere descritta in un modo più breve di questa.
# Fissato un linguaggio di programmazione, data una stringa finita di caratteri w
# chiamo complessità di w, e indico con C(w), la lunghezza minima di un programma
# che generi w.
# Esempio, in R ('noquote' toglie le virgolette):
w <- "abcdeabcde"
noquote("abcdeabcde")
# stringa lunga len(w) = 10, complessità 11+10 = 21 (devo solo togliere le virgolette)
# Sicuramente ogni stringa finita w ha C(w) <= len(w)+11.
# Vediamo cosa accade per:
w <- "abcdeabcdeabcdeabcdeabcdeabcdeabcdeabcdeabcdeabcdeabcdeabcdeabcdeabcdeabcdeabcde"
# 123456789A123456789B123456789C123456789D123456789E123456789F123456789G123456789H
# len(w) = 80; C(w) è strettamenete inferiore di len(w)+11, cioè di 91
# Posso infatti generare la stringa in forma "compressa" con i comandi seguenti, dove
# "paste" incolla due stringhe con un certo separatore (qui senza alcun separatore):
w<-""; for(n in 1:16) w<-paste(w,"abcde",sep=""); noquote(w)
#23456789A123456789B123456789C123456789D123456789E123456789F
# C(w) al più è 60 (< len(w)).
#
# Posso pensare che una stringa infinita sia casuale se non è comprimibile. Precisiamo
# che cosa possiamo intendere per "comprimibile" nel caso infinito.
# Idea: una stringa infinita S è comprimibile se le sue sottostringhe w abbastanza
# grandi hanno C(w) che tende ad essere via via più piccola di len(w). Dunque:
# una stringa infinita S è casuale se l'insieme {len(w)-C(w) / w sottostringa di S}
# è limitato superiormente.
#
# Questa è l'idea della definizione, che può essere estesa a considerare
# successioni di altri oggetti matematici.
#
# La successione delle cifre di un numero irrazionale è casuale? Se è generabile
# con un algoritmo, no! Tuttavia i numeri reali generabili con un algoritmo (ovvero
# di cui posso conoscere, potenzialmente, tutte le cifre che voglio) sono una infinità
# numerabile, essendo tale la quantità dei programmi che si posso descrivere con un
# linguaggio formale: la conoscenza delle cifre della stragrande maggioranza dei
# numeri reali non è alla nostra portata.
#
# Si può dimostrare (teorema di incompletezza di Chaitin-Gödel) che non è possibile
# dimostrare che una successione infinita di caratteri è casuale.
#
# Questo risultato è una versione "generale" del Teorema di Incompletezza a cui
# accennerete nel corso di Logica; esso esprime in modo molto generale i limiti
# intrinseci dei sistemi formali.
# FINE PARENTESI - - - - - - - - - - - - - - - - - - - - - - - - - -
#
# Pur essendo giunti alla conclusione che non è possibile dimostrare la casualità di
# una successione, nella realtà interessa costruire degli algoritmi per generare
# successioni che, ai fini pratici, si comportino come se fossero "casuali". Questo
# servirà, in particolare, per simulare e studiare statisticamente fenomeni casuali.
#
# Dopo vari insuccessi, sono stati messi a punto vari generatori di successioni
# (pseudo)casuali di numeri. Attualmente i più usati sono basati sullo schema noto
# come metodo congruenziale lineare: X(n+1) = (a*X(n)+c) mod M (a,X(0),c,M numeri
# naturali; a,X(0),c < M) o su schemi simili: X(n) = (a*X(n-h)−b*X(n-k)) mod M
# (dove tutte le costanti sono numeri naturali fissati).
# Si genera in tal modo una sequenza di numeri interi compresi tra 0 e M, da cui si
# può ottenere una sequenza di numeri in [0,1) dividendo ciascuno di essi per M.
#
# Scegliendo opportunamente le costanti si può verificare, attraverso test statistici,
# che tale successione si comporta, apparentemente (non realmente: è generata con un
# algoritmo!), in modo "massimamente" casuale. I test riguardano l'uniformità della
# distribuzione, l'indipendenza di ogni uscita dalle precedenti (o, meglio, da alcune
# centinaia delle precedenti - 623 nel caso di quello standard di R: da tutte non può
# esserlo!) e molti altri aspetti.
# Vediamo quale generatore usa R: cerchiamo nella "guida Html" del programma la voce
# Random Number Generation; il generatore usato normalmente da R è quello chiamato
# Mersenne-Twister, ideato nel 1998, che ha un periodo lungo 2^19937 - 1. Non ci
# preoccupiamo di esaminare nel dettaglio come esso opera (chi vuole può recuperare
# dal sito come accedere a tali informazioni).
#
# Vediamo solo qualche esempio di generatori di numeri casuali. L'obiettivo è dare
# un'idea di come sia complesso il fenomeno, e pensare come, volendo, si possa far
# percepire questa complessità ai ragazzi.
# In alcuni di questi generatori compare il simbolo funzionale %% che rappresenta
# (in R e in molti linguaggi di programmazione) la funzione mod:(M,N) -> "resto
# intero della divisione di M per N"
#
## LungRnd0
# Consideriamo il "generatore" seguente (parto da x0 e ottengo via via gli altri
# numeri applicando Rand):
a <- 7; M <- 100; c <- 70; x0 <- 60
Rand <- function(x) (a*x+c) %% M
# Vediamo qualche esempio d'uso:
Rand(60)
# ottengo 90
Rand(90)
# 0
Rand(0)
# 70
Rand(70)
# 60
# Ho riottenuto 60, dopo solo 4 uscite, con 4 molto più piccolo di M (100).
# Vediamo come avrei potuto procedere senza fare uno ad uno i tentativi: conto con n
# le prove e le ripeto fino a che riottengo x0:
alt <- 0; n <- 1; x <- x0
while(alt == 0) if(Rand(x)==x0) {print(n); alt <- 1} else {x <- Rand(x); n <- n+1}
# riottengo ottengo 4.
# Questo era un brutto generatore. Dà un'idea di come non si possa procedere a caso.
# Proviamo con un'altro.
#
## LungRnd1
# Generatore che era stato proposto in: "Le scienze con il calcolatore tascabile"
# (R.Green, J.Lewis - Muzzio Editore - 1980)
a <- 259; M <- 65536; x0 <- 725
Rand <- function(x) (a*x) %% M
# Proviamo direttamente a trovare il periodo:
alt <- 0; n <- 1; x <- x0
while(alt == 0) if(Rand(x)==x0) {print(n); alt <- 1} else {x <- Rand(x); n <- n+1}
# ottengo 16384.
# È un valor molto grande (=65536/4). Potrei usarlo questo generatore per simulare
# qualche semplice fenomento. Dovrò verificare che la distribuzione sia accettabile
# come uniforme. Come abbiamo detto la cosa non è facile. Proviamo, solo, a vederlo
# graficamente, nel modo seguente (prima "normalizziamo" le uscite, ossia le
# trasformiamo in numeri tra 0 ed 1 dividendole per M).
# Idea: genere a caso una x, memorizzarne il valore come u, proseguire generando
# un'altra x e rapresentare il punto u/m ed x/M.
#
a <- 259; M <- 65536; x0 <- 725
Rand <- function(x) (a*x) %% M
plot(c(0,1),c(0,1),type="n",xlab="", ylab="")
x <- x0
for(i in 1:500) {x <- Rand(x); u <- x; x <- Rand(x); points(u/M,x/M,pch=".",cex=2)}
for(i in 1:500) {x <- Rand(x); u <- x; x <- Rand(x); points(u/M,x/M,pch=".",cex=2)}
for(i in 1:500) {x <- Rand(x); u <- x; x <- Rand(x); points(u/M,x/M,pch=".",cex=2)}
...
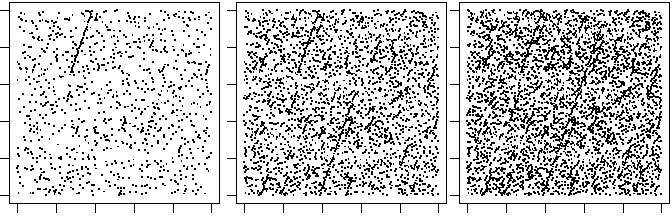 # Hanno un comportamento simile i generatori casuali impiegati nei personal computer
# nella prima metà degli anni '80. Bastano queste uscite grafiche per rendersi
# conto dei limiti di questi generatori.
#
# Per mettere in luce l'opportunità di altri metodi esaminiamo un altro generatore
# che fu molto impiegato.
#
## LungRnd2
# Generatore proposto nel manuale del pocket computer HP-25 (più o meno
# contemporaneo al precedente).
# Genera direttamente numeri tra 0 ed 1 (genera numeri x e ne prende la parte
# frazionaria con x-"parte intera di x")
R0 <- 1/2
Rand <- function(R) {R <- (R+pi)^5; R-floor(R)}
# Proviamo ad usarlo:
R <- 1/2
R <- Rand(R); R
# 0.4081073
R <- Rand(R); R
# 0.5834226
#
# Proviamo a trovarne il periodo:
R0 <- 1/2
alt <- 0; n <- 1; R <- R0
Rand <- function(R) {R <- (R+pi)^5; R-floor(R)}
while(alt == 0) if(Rand(R)==R0) {print(n); alt <- 1} else {R <- Rand(R); n <- n+1}
# non si ferma: lo fermo io (con ESC) e stampo n ed R. Ottengo per esempio:
n; R
# 116734 0.5740558
#
# Le uscite sono numeri decimali di parecchie cifre; non abbiamo più
# valori interi come prima, che ciclavano, Questo è un generatore di tipo
# diverso.
# Esaminiamo le ucite graficamente:
R0 <- 1/2
alt <- 0; n <- 1; R <- R0
Rand <- function(R) {R <- (R+pi)^5; R-floor(R)}
plot(c(0,1),c(0,1),type="n",xlab="", ylab="")
for(i in 1:500) {x <- Rand(x); u <- x; x <- Rand(x); points(u,x,pch=".",cex=2)}
for(i in 1:500) {x <- Rand(x); u <- x; x <- Rand(x); points(u,x,pch=".",cex=2)}
...
# Hanno un comportamento simile i generatori casuali impiegati nei personal computer
# nella prima metà degli anni '80. Bastano queste uscite grafiche per rendersi
# conto dei limiti di questi generatori.
#
# Per mettere in luce l'opportunità di altri metodi esaminiamo un altro generatore
# che fu molto impiegato.
#
## LungRnd2
# Generatore proposto nel manuale del pocket computer HP-25 (più o meno
# contemporaneo al precedente).
# Genera direttamente numeri tra 0 ed 1 (genera numeri x e ne prende la parte
# frazionaria con x-"parte intera di x")
R0 <- 1/2
Rand <- function(R) {R <- (R+pi)^5; R-floor(R)}
# Proviamo ad usarlo:
R <- 1/2
R <- Rand(R); R
# 0.4081073
R <- Rand(R); R
# 0.5834226
#
# Proviamo a trovarne il periodo:
R0 <- 1/2
alt <- 0; n <- 1; R <- R0
Rand <- function(R) {R <- (R+pi)^5; R-floor(R)}
while(alt == 0) if(Rand(R)==R0) {print(n); alt <- 1} else {R <- Rand(R); n <- n+1}
# non si ferma: lo fermo io (con ESC) e stampo n ed R. Ottengo per esempio:
n; R
# 116734 0.5740558
#
# Le uscite sono numeri decimali di parecchie cifre; non abbiamo più
# valori interi come prima, che ciclavano, Questo è un generatore di tipo
# diverso.
# Esaminiamo le ucite graficamente:
R0 <- 1/2
alt <- 0; n <- 1; R <- R0
Rand <- function(R) {R <- (R+pi)^5; R-floor(R)}
plot(c(0,1),c(0,1),type="n",xlab="", ylab="")
for(i in 1:500) {x <- Rand(x); u <- x; x <- Rand(x); points(u,x,pch=".",cex=2)}
for(i in 1:500) {x <- Rand(x); u <- x; x <- Rand(x); points(u,x,pch=".",cex=2)}
...
 ...
# Le uscite sembrano disporsi uniformente. Ma questa è solo un'impressione.
# Proviamo a verifcarlo anche con un istogramma:
R <- 1/2; u <- NULL; for(i in 1:1e4) {u <- c(u,R); R <- Rand(R)}
hist(u,freq=FALSE)
...
# Le uscite sembrano disporsi uniformente. Ma questa è solo un'impressione.
# Proviamo a verifcarlo anche con un istogramma:
R <- 1/2; u <- NULL; for(i in 1:1e4) {u <- c(u,R); R <- Rand(R)}
hist(u,freq=FALSE)
 # L'istogramma sembra confermarci la cosa.
# Questa verifica non è tuttavia sufficiente.
#
# Ad esempio anche per il generatore di numeri casuali visto alla fine della
# volta scorsa, evidentemente "non del tutto casuale" (si ripetono coppie di
# uscite uguali), di cui abbiamo già visto la forma "piatta" dell'istogramma:
n <- 1e4; x <- runif(n); i <- seq(4,n,4); x[i] <- x[i-2]; hist(x,freq=FALSE)
# L'istogramma sembra confermarci la cosa.
# Questa verifica non è tuttavia sufficiente.
#
# Ad esempio anche per il generatore di numeri casuali visto alla fine della
# volta scorsa, evidentemente "non del tutto casuale" (si ripetono coppie di
# uscite uguali), di cui abbiamo già visto la forma "piatta" dell'istogramma:
n <- 1e4; x <- runif(n); i <- seq(4,n,4); x[i] <- x[i-2]; hist(x,freq=FALSE)
 # basandosi su queste prove non si hanno indizi della sua "non bontà":
n <- 1e4; x <- runif(n); i <- seq(4,n,4); x[i] <- x[i-2]
x1 <- x
n <- 1e4; x <- runif(n); i <- seq(4,n,4); x[i] <- x[i-2]
x2 <- x
plot(c(0,1),c(0,1),type="n",xlab="", ylab="")
points(x1,x2,pch=".")
# basandosi su queste prove non si hanno indizi della sua "non bontà":
n <- 1e4; x <- runif(n); i <- seq(4,n,4); x[i] <- x[i-2]
x1 <- x
n <- 1e4; x <- runif(n); i <- seq(4,n,4); x[i] <- x[i-2]
x2 <- x
plot(c(0,1),c(0,1),type="n",xlab="", ylab="")
points(x1,x2,pch=".")
 # In questo caso, sapendo come è costruito questo "generatore", possiamo
# costruire una verifica che ne mette in luce i limiti.
# Ecco che cosa si ottiene studiando statisticamente (1) i valori ottenuti
# facendo le differenze tra il valore ottenuto col generatore standard e
# quello ottenuto due uscite prima (mi aspettio una distribuzione triangolare:
# il valore più frequente è 0, e poi via via, andando verso -1 ed 1, le
# frequenze diminuiscono) e (2) quelli ottenuti analogamente con questo
# generatore (uno ogni due valori viene 0: la differenza tra due numeri
# uguali):
n <- 1e4; y <- runif(n)
i <- 1:(n-2); w <- NULL; w[i] <- y[i+2]-y[i]
hist(w,freq=FALSE,seq(-1,1,2/15))
#
x <- runif(n); i <- seq(4,n,4); x[i] <- x[i-2]
i <- 1:(n-2); z <- NULL; z[i] <- x[i+2]-x[i]
hist(z,freq=FALSE,seq(-1,1,2/15))
# In questo caso, sapendo come è costruito questo "generatore", possiamo
# costruire una verifica che ne mette in luce i limiti.
# Ecco che cosa si ottiene studiando statisticamente (1) i valori ottenuti
# facendo le differenze tra il valore ottenuto col generatore standard e
# quello ottenuto due uscite prima (mi aspettio una distribuzione triangolare:
# il valore più frequente è 0, e poi via via, andando verso -1 ed 1, le
# frequenze diminuiscono) e (2) quelli ottenuti analogamente con questo
# generatore (uno ogni due valori viene 0: la differenza tra due numeri
# uguali):
n <- 1e4; y <- runif(n)
i <- 1:(n-2); w <- NULL; w[i] <- y[i+2]-y[i]
hist(w,freq=FALSE,seq(-1,1,2/15))
#
x <- runif(n); i <- seq(4,n,4); x[i] <- x[i-2]
i <- 1:(n-2); z <- NULL; z[i] <- x[i+2]-x[i]
hist(z,freq=FALSE,seq(-1,1,2/15))
 #
# Ci siamo resi conto della complessità dell'argomento. Averlo un po'
# maneggiato ci ha dato un'idea di quanta "matematica" ci sia dietro alla
# messa a punto di uno strumento apparentemente semplice come questo.
#
# Un'ultima osservazione: queste successioni (LungRnd1, LungRnd2) possono
# partire prendendo come valore inziale invece del valore x0 indicato un
# altro valore tra quelli generati. Lo stesso accade per runif.
# Il comando set.seed(n) ("stabilire il seme"), con n numero naturale, fa
# partire la successione "casuale" da un dato valore (con lo stesso n ho
# la stessa sequenza)
set.seed(7); runif(3); runif(3)
# 0.9889093 0.3977455 0.1156978
# 0.06974868 0.24374939 0.79201043
set.seed(7); runif(3)
# 0.9889093 0.3977455 0.1156978; ho riottenuto gli stessi valori:
# il "seme" 7 dà luogo, come primo valore casuale, a 0.9889093.
# Generare la stessa successione di numeri "casuali" può essere comodo
# in molte situazioni (testare un algoritmo sulla stessa successione di valori,
# controllare simulazioni di fenomeni, memorizzare codifiche segrete, ...).
#
# Accanto a questi "pseudo generatori di numeri casuali" (PRNG) vi sono anche
# degli "hardware random number generator" generati da un processo fisico,
# basati su fenomeni termici, fotoelettrici, quantistici, utilizzati per
# particolari applicazioni, non in ambito statistico.
#
#
# Ci siamo resi conto della complessità dell'argomento. Averlo un po'
# maneggiato ci ha dato un'idea di quanta "matematica" ci sia dietro alla
# messa a punto di uno strumento apparentemente semplice come questo.
#
# Un'ultima osservazione: queste successioni (LungRnd1, LungRnd2) possono
# partire prendendo come valore inziale invece del valore x0 indicato un
# altro valore tra quelli generati. Lo stesso accade per runif.
# Il comando set.seed(n) ("stabilire il seme"), con n numero naturale, fa
# partire la successione "casuale" da un dato valore (con lo stesso n ho
# la stessa sequenza)
set.seed(7); runif(3); runif(3)
# 0.9889093 0.3977455 0.1156978
# 0.06974868 0.24374939 0.79201043
set.seed(7); runif(3)
# 0.9889093 0.3977455 0.1156978; ho riottenuto gli stessi valori:
# il "seme" 7 dà luogo, come primo valore casuale, a 0.9889093.
# Generare la stessa successione di numeri "casuali" può essere comodo
# in molte situazioni (testare un algoritmo sulla stessa successione di valori,
# controllare simulazioni di fenomeni, memorizzare codifiche segrete, ...).
#
# Accanto a questi "pseudo generatori di numeri casuali" (PRNG) vi sono anche
# degli "hardware random number generator" generati da un processo fisico,
# basati su fenomeni termici, fotoelettrici, quantistici, utilizzati per
# particolari applicazioni, non in ambito statistico.
#
Attività con R - 5
# Dopo questa digressione, vediamo alcuni modi in cui si possono realizzare
# rappresentazioni grafiche piane. Abbiamo visto (ad es. qui, qui e qui) come fare il
# grafico di una funzione facendo scegliere automaticamente la scala o scegliendo
# (con xlim e ylim) dove far variare ascisse e ordinate o aggiungendo il grafico
# ad una griglia già scelta. Abbiamo anche visto (ad es. qui) come il parametro
# "col" consente di scegliere il colore con cui realizzare i grafici. I colori
# usabili sono centinaia; i nomi sono elencati dal comando colors(); non mettere
# il colore è come scegliere black. Eccone alcuni: white yellow yellow3 yellow4
# green green4 violet purple pink coral red magenta magenta4 orange brown
# cyan cyan4 blue blue4 grey grey50 black (i colori sono chiamabili anche usando
# le coordinate RossoVerdeBlu: vedi)
#
# Ecco come aggiungere (al grafico di g <- function(x) x^2-1) la curva
# y^2/10+1 = x tracciata mediante 2000 segmentini: lines(p,q,...) traccia
# l'insieme dei segmenti con vertici i punti (p,q) dove p e q sono i valori
# descritti in funzione di t, con t che varia tra t1 e t2.
plot(c(-5,5),c(-5,8),type="n",xlab="",ylab="")
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
abline(v=0, h=0, col="blue",lty=2)
g <- function(x) x^2-1; curve(g,col="brown",add=TRUE)
t1 <- -5; t2 <- 8; punti <- 2001; t <- seq(t1,t2,(t2-t1)/punti)
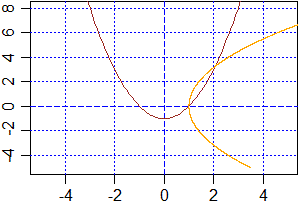 #
# Ecco come visualizzare delle figure ottenibili congiungendo punti di cui sono
# note le coordinate. Conosco nome e collocazione dei file. Vediamo cosa c'è:
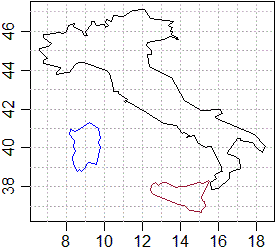
readLines("http://macosa.dima.unige.it/om/prg/R/rmacosa/penisola.txt",n=3)
# "8,46" "7.87,45.9" "7.6,45.95"
# Sono punti rappresentati mediante coppie di coordinate (dal nome capisco che
# si tratta della penisola italiana), separato da "," e senza commenti iniziali.
# Dunque li carico con:
dati1 <- read.table("http://macosa.dima.unige.it/om/prg/R/rmacosa/penisola.txt",header=FALSE,sep =",")
# Posso vedere come sono strutturati di dati:
str(dati1)
# 'data.frame': 124 obs. of 2 variables:
# $ V1: num 8 7.87 7.6 7 6.81 6.81 7.2 7.08 6.6 6.6 ...
# $ V2: num 46 45.9 46 45.9 45.8 ...
# carico analogamente altri due file e cerco minima e massima x, minima e massima y:
dati2 <- read.table("http://macosa.dima.unige.it/om/prg/R/rmacosa/sicilia.txt",header=FALSE,sep =",")
dati3 <- read.table("http://macosa.dima.unige.it/om/prg/R/rmacosa/sardegna.txt",header=FALSE,sep =",")
mo <- min(dati1$V1,dati2$V1,dati3$V1);Mo <- max(dati1$V1,dati2$V1,dati3$V1)
mv <- min(dati1$V2,dati2$V2,dati3$V2);Mv <- max(dati1$V2,dati2$V2,dati3$V2)
# Scelgo un rettangolo cartesiano che contenga tutti i punti:
plot(c(mo,Mo),c(mv,Mv),type="n",xlab="", ylab="")
abline(h=seq(37,47,1),v=seq(7,18,1),lty=3,col="grey")
lines(dati1,col="black")
lines(dati2,col="brown")
lines(dati3,col="blue")
#
# Ecco come visualizzare delle figure ottenibili congiungendo punti di cui sono
# note le coordinate. Conosco nome e collocazione dei file. Vediamo cosa c'è:
readLines("http://macosa.dima.unige.it/om/prg/R/rmacosa/penisola.txt",n=3)
# "8,46" "7.87,45.9" "7.6,45.95"
# Sono punti rappresentati mediante coppie di coordinate (dal nome capisco che
# si tratta della penisola italiana), separato da "," e senza commenti iniziali.
# Dunque li carico con:
dati1 <- read.table("http://macosa.dima.unige.it/om/prg/R/rmacosa/penisola.txt",header=FALSE,sep =",")
# Posso vedere come sono strutturati di dati:
str(dati1)
# 'data.frame': 124 obs. of 2 variables:
# $ V1: num 8 7.87 7.6 7 6.81 6.81 7.2 7.08 6.6 6.6 ...
# $ V2: num 46 45.9 46 45.9 45.8 ...
# carico analogamente altri due file e cerco minima e massima x, minima e massima y:
dati2 <- read.table("http://macosa.dima.unige.it/om/prg/R/rmacosa/sicilia.txt",header=FALSE,sep =",")
dati3 <- read.table("http://macosa.dima.unige.it/om/prg/R/rmacosa/sardegna.txt",header=FALSE,sep =",")
mo <- min(dati1$V1,dati2$V1,dati3$V1);Mo <- max(dati1$V1,dati2$V1,dati3$V1)
mv <- min(dati1$V2,dati2$V2,dati3$V2);Mv <- max(dati1$V2,dati2$V2,dati3$V2)
# Scelgo un rettangolo cartesiano che contenga tutti i punti:
plot(c(mo,Mo),c(mv,Mv),type="n",xlab="", ylab="")
abline(h=seq(37,47,1),v=seq(7,18,1),lty=3,col="grey")
lines(dati1,col="black")
lines(dati2,col="brown")
lines(dati3,col="blue")
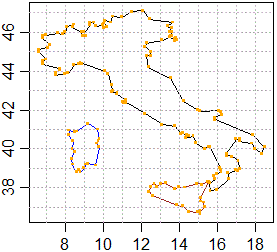
 # se vuoi evidenziare i punti puoi aggiungere:
points(dati1,col="orange",pch=".", cex=3)
points(dati2,col="orange",pch=".", cex=3)
points(dati3,col="orange",pch=".", cex=3)
# se vuoi evidenziare i punti puoi aggiungere:
points(dati1,col="orange",pch=".", cex=3)
points(dati2,col="orange",pch=".", cex=3)
points(dati3,col="orange",pch=".", cex=3)
 #
# Come detto (vedi) i comandi dati possono essere memorizzati usando il comando
# Save History. I grafici possono essere man mano rieseguiti usando i comandi;
# volendo, ecco come conviene salvare un'immagine. Si clicca su di essa e, dal
# menu che si apre cliccando, la si salva come BitMap e la si incolla su Paint
# (o un altro programma di grafica), si aggiunge quello che si vuole e la si
# ridimensiona. A questo punto o la si copia e salva nel documento in cui si
# sta operando o, da Paint, la si salva in formato GIF, che occupa poco spazio
# e consente di operare successive modifiche, anche dettagliate, con Paint
# (nelle ultime versioni di Windows, conviene, prima di salvarlo, farsi una
# copia del file, quindi memorizzarlo come GIF, attendere un messaggio che
# dice che l'immagine non è salvata perfettamente, quindi incollare l'immagine
# memorizzata e fare Save: l'immagine a questo punto è perfetta; se essa viene
# incollata su una figura già salvata come gif e poi salvata, eventualmente
# cambiando il nome, il salvataggio "perfetto" viene fatto automaticamente).
#
# Vedi QUI per l'uso di locator per evidenziare coordinate di punti o
# tracciare punti (e segmenti) col mouse.
#
# Vedi QUI per aprire/dimensionare nuove finestre (windows)
#
# Vedi QUI per aggiungere scritte nei grafici (text)
#
# Vedi QUI per realizzare trasformazioni geometriche
#
# Vedi QUI per realizzare movimenti col mouse
#
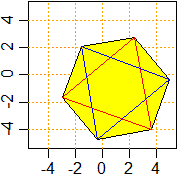
# Una funzione per tracciare un poligono regolare di centro C, raggio R, con
# AngIniz che indica la posizione del primo vertice, cob e coi che indicano
# il colore del bordo e il colore interno. Se non voglio colorare internamente
# il poligono basta che come colore dia NULL
pol <- function(C, R, AngIniz, N, cob, coi) {
gr <- function(x) x/180*pi;
ang <- function(i) gr((360/N)*i+AngIniz);
polygon( cos(ang(0:N))*R+C[1], sin(ang(0:N))*R+C[2],border=cob,col=coi) }
plot(c(-5,5),c(-5,5),type="n",xlab="", ylab="", asp=1)
abline(v=axTicks(1), h=axTicks(2), col="orange",lty=3)
pol(c(1,-1),4,70,6,"black","yellow")
pol(c(1,-1),4,70,3,"red",NULL); pol(c(1,-1),4,70+60,3, "blue",NULL)
#
# Come detto (vedi) i comandi dati possono essere memorizzati usando il comando
# Save History. I grafici possono essere man mano rieseguiti usando i comandi;
# volendo, ecco come conviene salvare un'immagine. Si clicca su di essa e, dal
# menu che si apre cliccando, la si salva come BitMap e la si incolla su Paint
# (o un altro programma di grafica), si aggiunge quello che si vuole e la si
# ridimensiona. A questo punto o la si copia e salva nel documento in cui si
# sta operando o, da Paint, la si salva in formato GIF, che occupa poco spazio
# e consente di operare successive modifiche, anche dettagliate, con Paint
# (nelle ultime versioni di Windows, conviene, prima di salvarlo, farsi una
# copia del file, quindi memorizzarlo come GIF, attendere un messaggio che
# dice che l'immagine non è salvata perfettamente, quindi incollare l'immagine
# memorizzata e fare Save: l'immagine a questo punto è perfetta; se essa viene
# incollata su una figura già salvata come gif e poi salvata, eventualmente
# cambiando il nome, il salvataggio "perfetto" viene fatto automaticamente).
#
# Vedi QUI per l'uso di locator per evidenziare coordinate di punti o
# tracciare punti (e segmenti) col mouse.
#
# Vedi QUI per aprire/dimensionare nuove finestre (windows)
#
# Vedi QUI per aggiungere scritte nei grafici (text)
#
# Vedi QUI per realizzare trasformazioni geometriche
#
# Vedi QUI per realizzare movimenti col mouse
#
# Una funzione per tracciare un poligono regolare di centro C, raggio R, con
# AngIniz che indica la posizione del primo vertice, cob e coi che indicano
# il colore del bordo e il colore interno. Se non voglio colorare internamente
# il poligono basta che come colore dia NULL
pol <- function(C, R, AngIniz, N, cob, coi) {
gr <- function(x) x/180*pi;
ang <- function(i) gr((360/N)*i+AngIniz);
polygon( cos(ang(0:N))*R+C[1], sin(ang(0:N))*R+C[2],border=cob,col=coi) }
plot(c(-5,5),c(-5,5),type="n",xlab="", ylab="", asp=1)
abline(v=axTicks(1), h=axTicks(2), col="orange",lty=3)
pol(c(1,-1),4,70,6,"black","yellow")
pol(c(1,-1),4,70,3,"red",NULL); pol(c(1,-1),4,70+60,3, "blue",NULL)
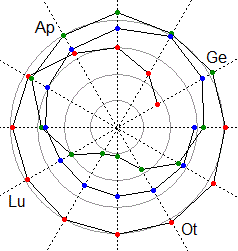
Attività con R - 6
# Appendice della volta scorsa.
# Il grafico in coordinate polari dei millimetri di pioggia mensili
# nel corso di tre anni in una data località.
# Provate a capire/spiegare come č stato costruito questo diagramma:
# ossia, quali commenti inserire per renderlo facilmente comprensibile?
#
mm <- c(44, 59, 75, 80,96,98,97,99,100,102,104,101,
103,102,108,100,92,71,49,28, 27, 45,66, 81,
92,99, 93, 85, 75,67,61,62, 64, 68,71, 72)
ang <- seq(30,30*12*3,30)
plot(c(-110,110),c(-110,110),type="n",xlab="",ylab="",axes=FALSE,asp=1)
for (i in 1:4) symbols(0,0,circles=i*25, inches=FALSE, add=TRUE, fg="grey60")
rad <- function(x) x*pi/180
for(i in 1:6) abline(0,tan(rad(30*i)),lty=3)
A <- ang*pi/180
lines(cos(A)*mm,sin(A)*mm)
A1 <- A[1:12]; A2 <- A[13:24]; A3 <- A[25:36]
mm1 <- mm[1:12]; mm2 <- mm[13:24]; mm3 <- mm[25:36]
points(cos(A1)*mm1,sin(A1)*mm1,col="red",pch=20)
points(cos(A2)*mm2,sin(A2)*mm2,col="green4",pch=20)
points(cos(A3)*mm3,sin(A3)*mm3,col="blue",pch=20)
text(cos(A[1]+0.1)*115,sin(A[1]+0.1)*115,"Ge")
text(cos(A[4]+0.1)*115,sin(A[4]+0.1)*115,"Ap")
text(cos(A[7]+0.1)*115,sin(A[7]+0.1)*115,"Lu")
text(cos(A[10]+0.1)*115,sin(A[10]+0.1)*115,"Ot")
 # (soluzione)
#
# Come calcolare varianza e scarto quadratico medio dei
# dati 13, 15, 18, 22, 25
dati <- c(13,15,18,22,25)
V <- function(dati) sum((dati-mean(dati))^2)/length(dati)
sqm <- function(dati) sqrt(V(dati))
mean(dati); sqm(dati)
# 18.6 4.409082
#
# N dei lanci di una moneta equa da effettuare fino ad ottenere l'uscita "testa"
# Al 50% esce dopo 1 lancio, al 25% dopo 2, al 12.5% dopo 3, ...
# Studio della serie 1/2 + 1/2^2 + 1/2^3 +...
n <- 1; s <- 0; for(i in 1:n) s <- s + 1/2^i; s
# 0.5
n <- 2; s <- 0; for(i in 1:n) s <- s + 1/2^i; s
# 0.75
n <- 10; s <- 0; for(i in 1:n) s <- s + 1/2^i; s
# 0.9990234
n <- 100; s <- 0; for(i in 1:n) s <- s + 1/2^i; s
# 1
# Potrei studiarla anche così:
a <- function(n) 1/2^n # a(n) elemento n-esimo della sommatoria
N <- function(n) seq(1,n,1) # N = 1 2 ... n
S <- function(n) sum(a(N(n))) # somma a(1)+...a(n)
S(1); S(10); S(20); S(40)
# 0.5 0.9990234 0.999999 1
# Posso farne il grafico anche usando barplot con l'opzione space:
a <- function(n) 1/2^n
barplot(a(1:10), space=0)
abline(v=(1:10), h=axTicks(2), col="brown",lty=3)
# (soluzione)
#
# Come calcolare varianza e scarto quadratico medio dei
# dati 13, 15, 18, 22, 25
dati <- c(13,15,18,22,25)
V <- function(dati) sum((dati-mean(dati))^2)/length(dati)
sqm <- function(dati) sqrt(V(dati))
mean(dati); sqm(dati)
# 18.6 4.409082
#
# N dei lanci di una moneta equa da effettuare fino ad ottenere l'uscita "testa"
# Al 50% esce dopo 1 lancio, al 25% dopo 2, al 12.5% dopo 3, ...
# Studio della serie 1/2 + 1/2^2 + 1/2^3 +...
n <- 1; s <- 0; for(i in 1:n) s <- s + 1/2^i; s
# 0.5
n <- 2; s <- 0; for(i in 1:n) s <- s + 1/2^i; s
# 0.75
n <- 10; s <- 0; for(i in 1:n) s <- s + 1/2^i; s
# 0.9990234
n <- 100; s <- 0; for(i in 1:n) s <- s + 1/2^i; s
# 1
# Potrei studiarla anche così:
a <- function(n) 1/2^n # a(n) elemento n-esimo della sommatoria
N <- function(n) seq(1,n,1) # N = 1 2 ... n
S <- function(n) sum(a(N(n))) # somma a(1)+...a(n)
S(1); S(10); S(20); S(40)
# 0.5 0.9990234 0.999999 1
# Posso farne il grafico anche usando barplot con l'opzione space:
a <- function(n) 1/2^n
barplot(a(1:10), space=0)
abline(v=(1:10), h=axTicks(2), col="brown",lty=3)
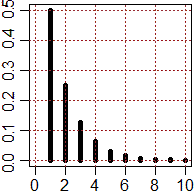
 # Ovvero posso usare i comandi seguenti (type="h" sta per "tipo istogramma"):
a <- function(n) 1/2^n
plot(a,1,10, n=10, type="h", lwd=5, xlab="", ylab="",xlim=c(0,10))
# ovvero: plot(1:10,a(1:10), type="h", lwd=5, xlab="", ylab="",xlim=c(0,10))
abline(v=axTicks(1), h=axTicks(2), col="brown",lty=3)
# Ovvero posso usare i comandi seguenti (type="h" sta per "tipo istogramma"):
a <- function(n) 1/2^n
plot(a,1,10, n=10, type="h", lwd=5, xlab="", ylab="",xlim=c(0,10))
# ovvero: plot(1:10,a(1:10), type="h", lwd=5, xlab="", ylab="",xlim=c(0,10))
abline(v=axTicks(1), h=axTicks(2), col="brown",lty=3)
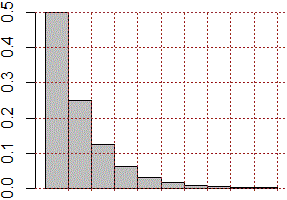
 # La serie 1/2 + 2*1/2^2 + 3*1/2^3 + ...
# (la media del numero N dei lanci di una moneta per avere testa)
n <- 1; s <- 0; for(i in 1:n) s <- s + i*1/2^i; s
n <- 10; s <- 0; for(i in 1:n) s <- s + i*1/2^i; s
n <- 100; s <- 0; for(i in 1:n) s <- s + i*1/2^i; s
# 0.5 1.988281 2
# Alternativa:
a <- function(n) n*1/2^n; S(1); S(10); S(100)
# 0.5 1.988281 2
#
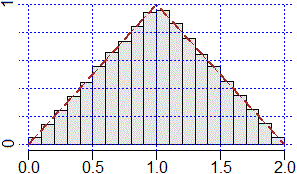
# La somma di due uscite del generatore di numeri casuali:
n <- 1e5; U1 <- runif(n); U2 <- runif(n); mean(U1+U2)
# 1.002107
hist(U1+U2, probability=TRUE, col="grey90")
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
# la "curva limite":
lines( c(0,1,2), c(0,1,0) ,lty=2, col="brown", lwd=2)
# La serie 1/2 + 2*1/2^2 + 3*1/2^3 + ...
# (la media del numero N dei lanci di una moneta per avere testa)
n <- 1; s <- 0; for(i in 1:n) s <- s + i*1/2^i; s
n <- 10; s <- 0; for(i in 1:n) s <- s + i*1/2^i; s
n <- 100; s <- 0; for(i in 1:n) s <- s + i*1/2^i; s
# 0.5 1.988281 2
# Alternativa:
a <- function(n) n*1/2^n; S(1); S(10); S(100)
# 0.5 1.988281 2
#
# La somma di due uscite del generatore di numeri casuali:
n <- 1e5; U1 <- runif(n); U2 <- runif(n); mean(U1+U2)
# 1.002107
hist(U1+U2, probability=TRUE, col="grey90")
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
# la "curva limite":
lines( c(0,1,2), c(0,1,0) ,lty=2, col="brown", lwd=2)
 #
# con WolframAlpha
# plot 1-abs(x-1) from x=0 to 2
# integrate 1-abs(x-1) from x=0 to 2
#
# con WolframAlpha l'integrale di una funzione continua a tratti:
# plot floor(x) from x=2 to 4
# integrate floor(x) from x=2 to 4
#
# Gli integrali definiti
# (lo sqm della distribuzione uniforme)
g <- function(x) (x-1/2)^2
integrate(g,0,1)
# 0.08333333 with absolute error < 9.3e-16
# Se specifichiamo di vole aver solo il valore:
integrate(g,0,1)$value
# 0.08333333
# Per avere il risultato sotto forma di frazione:
library(MASS); fractions( integrate(g,0,1)$value )
# 1/12
#
# con WolframAlpha:
# integrate (x-1/2)^2 from x=0 to 1
#
# Esempio di Var(X+Y) = Var(X)+Var(Y) con X ed Y indipendenti (lancio
# di due dadi equi):
n <- 1e7
U1 <- floor(runif(n)*6)+1; U2 <- floor(runif(n)*6)+1
V1 <- sum( (U1-mean(U1))^2/n); V2 <- sum( (U2-mean(U2))^2/n)
V <- sum( ((U1+U2)-mean(U1+U2))^2/n)
V; V1; V2; V1+V2
# 5.834054 2.917164 2.916623 5.833788
#
# Esempio di M(X·Y) = M(X)·M(Y) con X ed Y indipendenti (esiti del lancio
# di due dadi equi e del prodotto delle uscite):
n <- 1e7
U1 <- floor(runif(n)*6)+1; U2 <- floor(runif(n)*6)+1
m1 <- mean(U1); m2 <- mean(U2)
m <- mean(U1*U2)
m; m1; m2; m1*m2
# 12.25129 3.500237 3.500425 12.25232
#
#
# con WolframAlpha
# plot 1-abs(x-1) from x=0 to 2
# integrate 1-abs(x-1) from x=0 to 2
#
# con WolframAlpha l'integrale di una funzione continua a tratti:
# plot floor(x) from x=2 to 4
# integrate floor(x) from x=2 to 4
#
# Gli integrali definiti
# (lo sqm della distribuzione uniforme)
g <- function(x) (x-1/2)^2
integrate(g,0,1)
# 0.08333333 with absolute error < 9.3e-16
# Se specifichiamo di vole aver solo il valore:
integrate(g,0,1)$value
# 0.08333333
# Per avere il risultato sotto forma di frazione:
library(MASS); fractions( integrate(g,0,1)$value )
# 1/12
#
# con WolframAlpha:
# integrate (x-1/2)^2 from x=0 to 1
#
# Esempio di Var(X+Y) = Var(X)+Var(Y) con X ed Y indipendenti (lancio
# di due dadi equi):
n <- 1e7
U1 <- floor(runif(n)*6)+1; U2 <- floor(runif(n)*6)+1
V1 <- sum( (U1-mean(U1))^2/n); V2 <- sum( (U2-mean(U2))^2/n)
V <- sum( ((U1+U2)-mean(U1+U2))^2/n)
V; V1; V2; V1+V2
# 5.834054 2.917164 2.916623 5.833788
#
# Esempio di M(X·Y) = M(X)·M(Y) con X ed Y indipendenti (esiti del lancio
# di due dadi equi e del prodotto delle uscite):
n <- 1e7
U1 <- floor(runif(n)*6)+1; U2 <- floor(runif(n)*6)+1
m1 <- mean(U1); m2 <- mean(U2)
m <- mean(U1*U2)
m; m1; m2; m1*m2
# 12.25129 3.500237 3.500425 12.25232
#
Attività con R - 7
# Esempi, veloci di cose che si possono fare, alcune anche a livello
# universitario.
# Fate tutto da soli e chiedetemi tutte le cose che non capite ...
#
# Copia e incolla tra un # e l'altro.
#
# Integrali.
# Che cosa fanno le seguenti istruzioni?
#
integr <- function(f,a,b,x0,n,c) {for(i in 0:n) {x <- a+(b-a)/n*i;
points(x,integrate(f,x0,x)$value,pch=".",col=c)}}
h <- function(x) x^2*(1+cos(x))-1
plot(h,-3,4)
abline(h=axTicks(2),v=axTicks(1),lty=3,col="blue")
abline(h=0,v=0,lty=2,col="blue")
integr(h,-3,4,-2,2000,"red")
points(-2,0)
 #
# Verifica con WolframAlpha:
# integrate x^2*(1+cos(x))-1 dx
# e poi:
k <- function(x) 1/3*x*(x^2-3)+(x^2-2)*sin(x)+2*x*cos(x)
curve(k,col="brown",add=TRUE)
#
# Verifica con WolframAlpha:
# integrate x^2*(1+cos(x))-1 dx
# e poi:
k <- function(x) 1/3*x*(x^2-3)+(x^2-2)*sin(x)+2*x*cos(x)
curve(k,col="brown",add=TRUE)
 #
# Controllo calcolistico con R (per la derivazione, nel comando "D",
# occorre mettere l'espressione da derivare, con "body", e la
# variabile rispetto a cui si deriva). Si ottiene l'espressione
# della derivata, che se si vuole di puo' copiare e incollare per
# definire la funzione derivata.
D(body(k),"x")
# 1/3 * (x^2 - 3) + 1/3 * x * (2 * x) + (2 * x * sin(x) +
# (x^2 - 2) * cos(x)) + (2 * cos(x) - 2 * x * sin(x))
# semplfico, "a mano":
# 1/3*(x^2-3)+1/3*x*(2*x)+(2*x*sin(x)+(x^2-2)*cos(x))+(2*cos(x)-2*x*sin(x))
# 1/3*(x^2-3)+1/3*x*(2*x)+(x^2-2)*cos(x))+2*cos(x)
# x^/3-1+2/3*x^2+x^2*cos(x)
# x^2*(1+cos(x))-1 OK
#
# Prova anche con queste istruzioni:
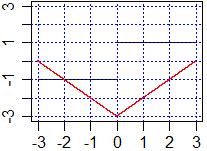
f <- function(x) sign(x)
plot(f,-3,-1e-10, xlim=c(-3,3), ylim=c(-3,3))
plot(f,3,1e-10,add=TRUE)
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
integr(f,-3,3,-3, 5000, "red")
#
# Controllo calcolistico con R (per la derivazione, nel comando "D",
# occorre mettere l'espressione da derivare, con "body", e la
# variabile rispetto a cui si deriva). Si ottiene l'espressione
# della derivata, che se si vuole di puo' copiare e incollare per
# definire la funzione derivata.
D(body(k),"x")
# 1/3 * (x^2 - 3) + 1/3 * x * (2 * x) + (2 * x * sin(x) +
# (x^2 - 2) * cos(x)) + (2 * cos(x) - 2 * x * sin(x))
# semplfico, "a mano":
# 1/3*(x^2-3)+1/3*x*(2*x)+(2*x*sin(x)+(x^2-2)*cos(x))+(2*cos(x)-2*x*sin(x))
# 1/3*(x^2-3)+1/3*x*(2*x)+(x^2-2)*cos(x))+2*cos(x)
# x^/3-1+2/3*x^2+x^2*cos(x)
# x^2*(1+cos(x))-1 OK
#
# Prova anche con queste istruzioni:
f <- function(x) sign(x)
plot(f,-3,-1e-10, xlim=c(-3,3), ylim=c(-3,3))
plot(f,3,1e-10,add=TRUE)
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
integr(f,-3,3,-3, 5000, "red")
 #
# --------------------------------------------
#
# Eq. differenziali.
# Uso a scatola nera di una procedura per tracciare il campo direzionale.
#
# Tracciamento in (x1,x2)*(y1,y2) del campo direzionale di y' = f(x,y)
# con f messo in Dy; prova con m=25, n=25
# (m e n indicano quanto sono i trattini in orizz. e in vert.)
soledif <- function(x1,x2,y1,y2,m,n) {
plot(c(x1,x2), c(y1,y2), type="n",xlab="",ylab="")
abline(h=0,v=0,col="blue")
dx <- (x2-x1)/m; dy <- (y2-y1)/n
a <- 0; b <- 0; f <- function(x) Dy(a,b)*(x-a)+b
for(i in 0:m) for(j in 0:n) {a <- x1+dx*i; b <- y1+dy*j
Dx <- dx; for(k in 1:100)
{if(abs(f(a+Dx/2.5)-f(a-Dx/2.5)) > dy) Dx <- Dx*0.9 else k <- 100}
plot(f,a-Dx/2.5,a+Dx/2.5,ylim=c(b-dy/2.5,b+dy/2.5),add=TRUE,col="grey55")}}
#
# Esempio: y'(x) = x-y(x)
Dy <- function(x,y) x-y
x1 <- -3; x2 <- 4
soledif(x1,x2,-3,3, 25,25)
#
# Alcune soluzioni (risolvendo, in questo caso, l'eq. differenziale;
# e' facile verificare che le seguenti sono soluzioni)
f <- function(x) x-1+(C+1)*exp(-x)
C <- -2; points(0,C,pch=20); plot(f,x1,x2,col="red",add=TRUE)
C <- -1; points(0,C,pch=20); plot(f,x1,x2,col="red",add=TRUE)
C <- 0; points(0,C,pch=20); plot(f,x1,x2,col="red",add=TRUE)
C <- 1; points(0,C,pch=20); plot(f,x1,x2,col="red",add=TRUE)
#
# --------------------------------------------
#
# Eq. differenziali.
# Uso a scatola nera di una procedura per tracciare il campo direzionale.
#
# Tracciamento in (x1,x2)*(y1,y2) del campo direzionale di y' = f(x,y)
# con f messo in Dy; prova con m=25, n=25
# (m e n indicano quanto sono i trattini in orizz. e in vert.)
soledif <- function(x1,x2,y1,y2,m,n) {
plot(c(x1,x2), c(y1,y2), type="n",xlab="",ylab="")
abline(h=0,v=0,col="blue")
dx <- (x2-x1)/m; dy <- (y2-y1)/n
a <- 0; b <- 0; f <- function(x) Dy(a,b)*(x-a)+b
for(i in 0:m) for(j in 0:n) {a <- x1+dx*i; b <- y1+dy*j
Dx <- dx; for(k in 1:100)
{if(abs(f(a+Dx/2.5)-f(a-Dx/2.5)) > dy) Dx <- Dx*0.9 else k <- 100}
plot(f,a-Dx/2.5,a+Dx/2.5,ylim=c(b-dy/2.5,b+dy/2.5),add=TRUE,col="grey55")}}
#
# Esempio: y'(x) = x-y(x)
Dy <- function(x,y) x-y
x1 <- -3; x2 <- 4
soledif(x1,x2,-3,3, 25,25)
#
# Alcune soluzioni (risolvendo, in questo caso, l'eq. differenziale;
# e' facile verificare che le seguenti sono soluzioni)
f <- function(x) x-1+(C+1)*exp(-x)
C <- -2; points(0,C,pch=20); plot(f,x1,x2,col="red",add=TRUE)
C <- -1; points(0,C,pch=20); plot(f,x1,x2,col="red",add=TRUE)
C <- 0; points(0,C,pch=20); plot(f,x1,x2,col="red",add=TRUE)
C <- 1; points(0,C,pch=20); plot(f,x1,x2,col="red",add=TRUE)
 # Con WolframAlpha: d/dx y = x-y
#
# --------------------------------------------
#
# Grafici di funzioni di 2 variabili.
# Un esempio:
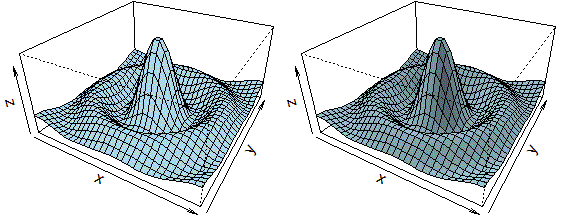
x <- y <- seq(-10, 10, len = 30)
f <- function(x,y) { r <- sqrt(x^2+y^2); 10 * sin(r)/r }
z <- outer(x, y, f)
persp(x, y, z, theta = 30, phi = 30, expand = 0.5, col = "lightblue")
#
# mettendo le "ombre":
persp(x,y,z, theta=30, phi=30, expand=0.5, col="lightblue", shade=0.2)
# Con WolframAlpha: d/dx y = x-y
#
# --------------------------------------------
#
# Grafici di funzioni di 2 variabili.
# Un esempio:
x <- y <- seq(-10, 10, len = 30)
f <- function(x,y) { r <- sqrt(x^2+y^2); 10 * sin(r)/r }
z <- outer(x, y, f)
persp(x, y, z, theta = 30, phi = 30, expand = 0.5, col = "lightblue")
#
# mettendo le "ombre":
persp(x,y,z, theta=30, phi=30, expand=0.5, col="lightblue", shade=0.2)
 # Vedi qui, se ti interessano i dettagli
#
# --------------------------------------------
#
# Lo spazio 3D
#
# Una curva nello spazio (5 giri di un'elica)
t <- seq(0,10*pi,len=1000)
z0 <- c(0,10*pi); u <- rep(z0[1],4) # metto in u la base del box
z <- array(u,dim=c(2,2)); x <- c(-2,2); y <- c(-2,2)
F <- persp(x,y,z,theta=30,phi=20,scale=TRUE,zlim=z0,xlim=x,ylim=y,d=1)
# ho tracciato il box
lines(trans3d(cos(t),sin(t),t,pmat=F),col="red")
# usando trans3d() aggiungo dei pezzi (in questo caso la curva)
#
# per averla senza box avrei aggiunto in persp: border="white",box=FALSE
# Vedi qui, se ti interessano i dettagli
#
# --------------------------------------------
#
# Lo spazio 3D
#
# Una curva nello spazio (5 giri di un'elica)
t <- seq(0,10*pi,len=1000)
z0 <- c(0,10*pi); u <- rep(z0[1],4) # metto in u la base del box
z <- array(u,dim=c(2,2)); x <- c(-2,2); y <- c(-2,2)
F <- persp(x,y,z,theta=30,phi=20,scale=TRUE,zlim=z0,xlim=x,ylim=y,d=1)
# ho tracciato il box
lines(trans3d(cos(t),sin(t),t,pmat=F),col="red")
# usando trans3d() aggiungo dei pezzi (in questo caso la curva)
#
# per averla senza box avrei aggiunto in persp: border="white",box=FALSE
 #
# --------------------------------------------
#
# Un esercizio "animato", da un sito in cui sono caricati alcuni file,
# con un help che è richiamabile col comando aiuto
#
source("http://macosa.dima.unige.it/R/pend.txt")
aiuto
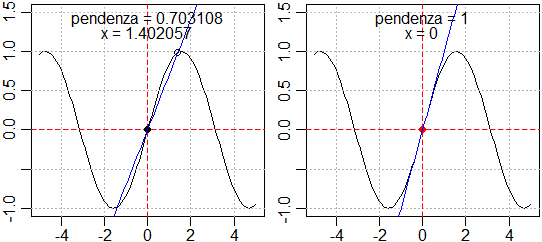
#[1] "Definisci una funz. f (o g, h1, ...). Se dai il comando seguente hai "
#[2] "il grafico di f per input tra a e b, output tra c e d, con evidenziato"
#[3] "il punto (x0,f(x0)). Se clicchi in un punto hai il grafico della retta"
#[4] "che passa per i punti del grafico di ascissa x0 e di quella cliccata. "
#[5] "Se clicchi l'ascissa x0 hai la retta tangente. Premi ESC per finire. "
#[6] "Comando: pend(f, a,b, c,d, x0) "
#[7] "Prova con: h <- function(x) x^2; pend(h, -1,1.5, 0,3, 1) "
#
#
# --------------------------------------------
#
# Un esercizio "animato", da un sito in cui sono caricati alcuni file,
# con un help che è richiamabile col comando aiuto
#
source("http://macosa.dima.unige.it/R/pend.txt")
aiuto
#[1] "Definisci una funz. f (o g, h1, ...). Se dai il comando seguente hai "
#[2] "il grafico di f per input tra a e b, output tra c e d, con evidenziato"
#[3] "il punto (x0,f(x0)). Se clicchi in un punto hai il grafico della retta"
#[4] "che passa per i punti del grafico di ascissa x0 e di quella cliccata. "
#[5] "Se clicchi l'ascissa x0 hai la retta tangente. Premi ESC per finire. "
#[6] "Comando: pend(f, a,b, c,d, x0) "
#[7] "Prova con: h <- function(x) x^2; pend(h, -1,1.5, 0,3, 1) "
#
 # Prova con l'es. suggerito nell'help, e con:
g <- function(x) 3*x^3-x^2+5*x-2
pend(g, 0,2.5, 0,50, 2)
#
h <- function(x) sin(x)
pend(h, -5,5, -1,1.5, pi/2)
#
pend(h, -5,5, -1,1.5, 0)
# Prova con l'es. suggerito nell'help, e con:
g <- function(x) 3*x^3-x^2+5*x-2
pend(g, 0,2.5, 0,50, 2)
#
h <- function(x) sin(x)
pend(h, -5,5, -1,1.5, pi/2)
#
pend(h, -5,5, -1,1.5, 0)
 #
# --------------------------------------------
#
# Come caricare un altro file (grafici di equazioni in x,y).
#
# NOTA: il file è stato modificato in quanto ho trovato un modo
# più semplice per tracciare curve descritte in forma implicita.
#
source("http://macosa.dima.unige.it/R/curva_impl.txt")
#
# --------------------------------------------
#
# Come caricare un altro file (grafici di equazioni in x,y).
#
# NOTA: il file è stato modificato in quanto ho trovato un modo
# più semplice per tracciare curve descritte in forma implicita.
#
source("http://macosa.dima.unige.it/R/curva_impl.txt")
aiuto
# [1] "Tracciamento di grafici di eq. di 2 variabili. Definita una funz. "
# [2] "di 2 variabili F, scelta la scala con un comando del tipo seguente"
# [3] "(non mettere asp=1 se non vuoi la scala monometrica): "
# [4] " plot(c(x1,x2),c(y1,y2),type='n',xlab='',ylab='',asp=1) "
# [5] "con questa riga tracci N punti di F(x,y)=0 per x tra a,b, y tra "
# [6] "c,d nel colore C (come eps prendi un n. via via piů vicino a 0): "
# [7] " curva_impl(F, a,b, c,d, N, eps, C) Prova con: "
# [8] " h <- function(x,y) x^3-y^2+1 "
# [9] " plot(c(-2,2), c(-2,2),type='n',xlab='',ylab='') "
#[10] " curva_impl(h,-1,2,-2,2,500,0.1,'orange') "
#[11] " curva_impl(h,-1,2,-2,2,500,0.01,'blue') "
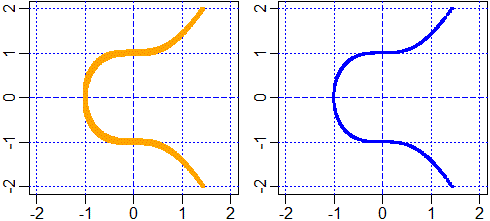
# Prova con l'es. suggerito nell'help, e con:
curv <- function(x,y) x^2-2*x*y+2*y^2-y-3
plot(c(-5,5), c(-5,5),type='n',xlab='',ylab='',asp=1)
curva_impl(curv,-5,5, -5,5, 300, 1,'green')
#
plot(c(-4,4), c(-3,5),type='n',xlab='',ylab='',asp=1)
curva_impl(curv,-4,4, -3,5, 300, 0.05,'red')
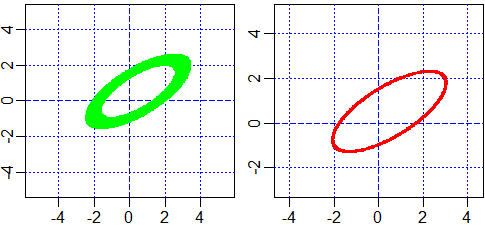 #
# --------------------------------------------
#
# Un esempio di serie (per dare un'idea di quel che si
# può fare - è una serie di Fourier)
p <- function(x) {f <- 0;
for(i in 0:n) f <- f+sin((2*i+1)*x)/(2*i+1); f <- f*4/pi}
n <- 1; plot(p,-5,10, col="blue",n=1000)
abline(h=0,v=0,lty=2,col="blue")
abline(v=axTicks(1), h=axTicks(2), col="grey",lty=3)
n <- 2; plot(p,-5,10,add=TRUE,col="red",n=1000)
n <- 3; plot(p,-5,10,add=TRUE,col="green",n=1000)
#
# A che cosa tende il grafico, al tendere di n all'infinito?
n <- 1000; plot(p,-5,10,add=TRUE,col="brown",n=5000)
# Ho messo un alto numero di punti a causa delle oscillazioni
#
# --------------------------------------------
#
# Un esempio di serie (per dare un'idea di quel che si
# può fare - è una serie di Fourier)
p <- function(x) {f <- 0;
for(i in 0:n) f <- f+sin((2*i+1)*x)/(2*i+1); f <- f*4/pi}
n <- 1; plot(p,-5,10, col="blue",n=1000)
abline(h=0,v=0,lty=2,col="blue")
abline(v=axTicks(1), h=axTicks(2), col="grey",lty=3)
n <- 2; plot(p,-5,10,add=TRUE,col="red",n=1000)
n <- 3; plot(p,-5,10,add=TRUE,col="green",n=1000)
#
# A che cosa tende il grafico, al tendere di n all'infinito?
n <- 1000; plot(p,-5,10,add=TRUE,col="brown",n=5000)
# Ho messo un alto numero di punti a causa delle oscillazioni
 #
#
HELP