R. USI DI BASE (vai QUI; altri usi)
Nel programma i comandi appaiono preceduti da >.
Le righe seguenti, scritte in nero (con eventuali parti in
rosso), possono man mano essere copiate da qui e incollate in R. Il
programma automaticamente le esegue. Le cose scritte in blu sono le uscite
od altri commenti. Le parti precedute da "#" sono commenti che
il programma non interpreta come comandi e riproduce tali e quali.
I grafici, qui riprodotti, in R appaiono in altre finestre.
Matematica di base —>
numeri variab. collez. precis. tree registr. sessioni help √ n! coeff.bin.
arrotond. frazioni calc.esatti input da tastiera for if == switch while
condiz. connettivi sottoins. elencare/rimuovere var. funzioni graf.1 graf.2
rette curve griglia colori sist. monom. origine ifelse graf. per punti
graf. tabelle da rete salvare immagini leggere coordinate
nuove finestre grafiche (e loro dimensioni) punti,segmenti,poligoni,cerchi
scritte trasf.geom. animaz. fasci di curve soluz.equaz. min/max uso di { e }
confrontare termini ricorsione tipo ogg. caricare oggetti già definiti
comandi su + righe concat.-sottostringhe-dim.car. visualizz.file graf./calc. vari
Statistica elementare —>
varie statistiche su collez. di dati (min,max,mean,sort,sum,…) sequenze di numeri
StemAndLeaf istogram. sintesi dei dati box-plot, percentili freq.rel. e cumulate
diagrammi a barre, a torta, per punti dati già classificati dati singoli da rete
dati con freq. da rete coord.polari generatore numeri casuali variab.indiciate
calcoli con dati approssimati grafico con dati appross. media geometrica
Indice alfabetico comandi - Indice alfabetico generale attività
# Si possono copiare le righe di comandi come le seguenti (fino alla prima
# riga in blu esclusa) e poi incollarle (azionando il comando col mouse o
# con Crtl+V) in R; le parti precedute da # vengono prese come commenti.
5/7
[1] 0.7142857
# il significato di [1] lo capiremo fra poco; si possono eseguire più
# comandi, separati da un "punto e virgola", ossia da un ;
5+7; 5-7; 5*7; 5/7; 5^7; 50+7; 50-7; 50*7; 50/7; 50^7
[1] 12
[1] -2
[1] 35
[1] 0.7142857
[1] 78125
[1] 57
[1] 43
[1] 350
[1] 7.142857
[1] 7.8125e+11
# l'ultimo numero è scritto in notazione esponenziale: sta per 7.8125*10^11;
# un altro esempio:
1/1000; 1/10000
[1] 0.001
[1] 1e-04
# Posso calcolare termini qualunque, rispettando le priorità tra le operazioni
2+3*5; (2+3)*5; 3*8/2^2; 3*(8/2)^2
[1] 17
[1] 25
[1] 6
[1] 48
# Posso mettere valori in variabili, ossia in espressioni inizianti con una
# lettera; per assegnare valori a variabili devo usare una freccia: <- o ->
a <- 7; 12 -> b; a+b; a*b; a/b; pippo <- a*b+a/b+100; pippo
[1] 19
[1] 84
[1] 0.5833333
[1] 184.5833
# Posso assegnare lo stesso valore contemporaneamente a più variabili:
c <- b <- a <- 13.15; a; b; c
[1] 13.15
[1] 13.15
[1] 13.15
# A differenza di altri programmi, per R nomi che differiscono per le
# dimensioni dei caratteri sono interpretati come differenti:
a+B
Error: object 'B' not found
# Una collezione di numeri può essere scritta così:
x <- c(55,67,71,49,58,72,65,58,67,52,60)
x
[1] 55 67 71 49 58 72 65 58 67 52 60
# I calcoli su questi numeri posso eseguirli sulla variabile che ne indica
# la collezione; le 11 uscite appaino sulla stessa riga, ma sono conteggiate;
# nel caso del calcolo di x^6, in cui vengono messe su più righe, si vede che
# è il numero tra […] che le conteggia; se più uscite sono stampate sulla
# stessa riga solo il numero d'ordine della prima uscita viene visualizzato.
x^2; x^6
[1] 3025 4489 5041 2401 3364 5184 4225 3364 4489 2704 3600
[1] 27680640625 90458382169 128100283921 13841287201 38068692544
[6] 139314069504 75418890625 38068692544 90458382169 19770609664
[11] 46656000000
# Per estrarre un elemento da una collezione ne metto tra parentesi quadre
# il posto
x[11]; x^2[11]; (x^2)[11]; x[11]^2
[1] 60
[1] NA NA NA NA NA NA NA NA NA NA NA
[1] 3600
[1] 3600
# Ho stampato l'11° elemento della successione e il suo quadrato, calcolato
# come 11° elemento dei quadrati o come quadrato dell'11° elemento; il
# secondo comando (in cui non è racchiuso tra () x^2) non ha prodotto uscite
# ( NA sta per "Not Available": è una costante logica [come FALSE] che indica
# l'assenza di un valore)
#
# Il valore di 5/7 era espresso come 0.7142857, in forma approssimata; ma
# abbiamo appena visto che i calcoli vengono eseguiti su più di 7 cifre. Se
# batto library(codetools) "carico" altri comandi tra i quali showTree che mi
# consente di vedere più cifre (cosa fattibile anche con altri comandi: vedi)
library(codetools); showTree(5/7)
0.714285714285714
# [ potevo anche non usare library e scrivere codetools::showTree(5/7) ]
# showTree consente di fare altre cose. Ad esempio analizzare la struttura di
# un termine (le operazioni e i fattori in ordine di priorità):
showTree(quote( 2+a*x^5*3-x ))
(- (+ 2 (* (* a (^ x 5)) 3)) x)
# (1) -
# / \ tree: albero
# (2) + x (11) Si pu� usare anche walkCode
# / \ (vedi)
# (3) 2 * (4)
# / \
# (5) * 3 (10)
# / \
# (6) a ^ (7)
# / \
# (8) x 5 (9)
# Dunque il risultato di un calcolo (semplice come questo) viene memorizzato
# con circa 15 cifre buone; nel caso di calcoli tra interi i risultati interi
# di 15 cifre possono essere esatti; ecco un esempio (12345678*12345678 viene
# memorizzato correttamente anche se ne viene stampato un valore approssimato):
x <- 12345678*12345678; x; showTree(x)
[1] 1.524158e+14
152415765279684
# Anche in questo caso l'input può essere una collezione di numeri:
x <- c(10, 45, 5/1000000); showTree(x/3)
c(3.33333333333333, 15, 1.66666666666667e-06)
# Occorre tener presente che nel caso del risultato di un calcolo possono
# intervenire errori di arrotondamento ed aversi meno cifre "buone":
x <- 5555.1251; y <- 5555; x-y; showTree(x-y)
[1] 0.1251
0.125100000000202
# delle 15 cifre "0000.12510000000" del risulato i primi "0" non sono
# visualizzati, e vengono visualizzate altre cifre, le ultime delle quali
# non sono "buone" (se vuoi esplorare il perché, vedi).
# Vediamo cosa si ottiene per π = 3.14159265358979323846264... e per
# √12345 = 111.108055513540511245004...
showTree(pi); showTree(sqrt(12345))
3.14159265358979
111.108055513541
# Vedremo più avanti le possibilità che offre il comando fractions (vedi).
#
# Se si scrive sprintf('%o',z) o sprintf('%x',z) con z intero si ottiene la sua
# rappresentazione in base otto e in base sedici (NOTA: si possono usare anche
# sprintf("%o",z) o sprintf("%x",z): le virgolette " e ' in R si equivalgono):
sprintf('%o',c(30,31,32,33)); sprintf('%x',c(30,31,32,33))
[1] "36" "37" "40" "41"
[1] "1e" "1f" "20" "21"
# as.roman visulizza i numeri naturali in notazione "romana"
as.roman(1393)
[1] MCCCXCIII
# Un n. intero espresso come STRinga diventa un intero (TO Integer) con strtoi
strtoi("153")
[1] 153
# Per trasformare un numero in stringa si usa toString
toString(3); toString(pi)
[1] "3"
[1] "3.14159265358979"
#
# Schiacciando il tasto freccia ^ [v] rivedo precedenti [segu.] comandi:
# cosa COMODA per rivedere, correggere o modificare precedenti comandi.
# Quanto fatto può essere memorizzato usando il comando Save History
# e dandogli un nome (con estensione ".Rhistory"). Il file può essere
# ricaricato con Load History e può essere esaminato o caricato con i
# tasti freccia, come detto sopra.
#
# Altre funzioni incorporate: per esamiare alcune funzioni si puo'
# guardare uno dei vari help; ad es. selezionare "R functions (text)" [o
# "Funzioni di R (testo)], mettere "sqrt" come parola da cercare; si apre
# "MathFun {base}" e da qui si seleziona "Math". sqrt è il nome usato
# per la radice quadrata ("square root" è il termine inglese per "radice
# quadrata"). Si può anche da "Html Help" ("Guida Html"), aprire "Packages"
# e, quindi, "Base" e "Graphics", oppure, sempre da "Html Help", aprire
# "Search Engine & Keywords". Si tratta, comunque, di help non facili per
# il principiante. Battendo il comando help(sqrt) si entra direttamente
# nell'help di sqrt (se non sei in rete potrebbe essere azionabile solo
# "Search Help" - "Cerca nella Guida").
# [ usando apropos("line") hai l'elenco delle voci che contengono "line";
# puoi poi esplorarle con help(...) ]
# Se vuoi aprire l'help con un particolare browser puoi battere:
help.start(browser="")
# copiare l'indirizzo http che compare e incollarlo nel browser che preferisci.
#
# Oltre che selezionando Exit dal menu File, si può uscire da R col comando
# quit(save="ask") (o solo quit()). Se per qualche motivo Exit non risponde
# (si è entrati in un loop, ad es.) questa strada di solito funziona.
#
3+sqrt(0.25)
[1] 3.5
# Per la radice cubica, quinta,..., n-ma per n dispari si può usare ^(1/n) che
# però (nel software) è definita solo per input positivi; altrimenti si usano
# le funzioni sign (segno) e abs (valore assoluto); es. (³√-8):
x <- -8; x^(1/3); sign(x)*abs(x)^(1/3)
[1] NaN
[1] -2
# NaN sta per "non è un numero" (Not A Number).
# Volendo posso definire:
RAD <- function(x,N) sign(x)*abs(x)^(1/N); RAD(-8,3); RAD(-8,5)
[1] -2
[1] -1.515717
#
# Una funzione a input naturali: il fattoriale n! (calcola fino a 170!)
5*4*3*2*1; factorial(5); factorial(170); showTree(factorial(170)); factorial(171)
[1] 120
[1] 120
[1] 7.257416e+306
7.25741561530888e+306
[1] Inf
Warning message:
In factorial(171) : value out of range in 'gammafn'
# ["warning" vuol dire "avviso"; per disattivare la comparsa di messaggi di questo
# tipo basta introdurre options(warn=-1), per riattivarla options(warn=0)]
#
# Se fossi interessato a valori più precisi potrei fare il prodotto (per ":" e
# "print" vedi qualche riga sotto; nota: 170!=7.257415615307998967…·10^306):
prod(1:170); print( prod(1:170), 16)
[1] 7.257416e+306
[1] 7.257415615307999e+306
# Il calcolo del coefficiente binomiale (indicato choose)
choose(10,3) # 10/3*9/2*8/1
[1] 120
#
# Vedi qui per round, ceiling, floor, trunc, signif, le funzioni di arrotond.
115/333; round(115/333*1E12)
[1] 0.3453453
[1] 345345345345
# Se a round o a signif aggiungo un numero intero (preceduto eventualmente
# da digits) ho altre approssimazioni:
round(175/6, digits=5); round(175/6,-1); signif(175/6, 5)
[1] 29.16667
[1] 30
[1] 29.167
Per avere più cifre potrei usare library(codetools) e showTree.
k <- signif(5/7,16); k; showTree(k)
[1] 0.7142857
[1] 0.7142857142857143
# Con print posso evitare d'usare showTree. La precisione (nel caso di calcoli
# "semplici") è di quasi 16 cifre decimali; 16 è il numero di cifre massimo
# che è opportuno usare (vedi); es.:
print(1000/3, 16); print(1000/3, 17)
[1] 333.3333333333333
[1] 333.33333333333331
# Il comando fractions consente di approssimare numeri decimali con frazioni
# (occore, però, prima, battere library(MASS) per caricare questo comando,
# oppure si può usare MASS::fractions al posto di fractions)
library(MASS)
fractions(0.345345345345345345)
[1] 115/333
fractions(4/80)
[1] 1/20
fractions(13/124+4/80)
[1] 24/155
# [fractions non opera correttamente su numeri troppo piccoli: fractions(1/1999)
# dà 1/1999 mentre fractions(1/2000) dà 0]
# Con fractions (oltre che con showTree) si possono fare anche calcoli esatti
# con interi di grandi dimensioni (precisi fino a 16 cifre); ad es.:
fractions(12345678*12345678); fractions(factorial(20)); showTree(factorial(20))
[1] 152415765279684
[1] 2432902008176640000
[1] 2432902008176640000
# Ecco come realizzare la divisione intera con resto:
divis <- function(m,n) c( trunc(m/n), m-trunc(m/n)*n )
divis(60,7)
[1] 8 4
# Per calcolare il resto di M diviso N posso anche usare la funzione M%%N
# (che in altri linguaggi è indicata mod(M,N) in quanto in matematica se
# M%%N = P%%N si dice che M e P sono congruenti modulo N; ad es. nel caso
# dell'orologio 15%%12 = 3%%12: 3 e 15 sono congruenti modulo 12).
# Analogamente, per il quoziente intero si usa M%/%N.
divis <- function(m,n) c( m%/%n, m%%n )
divis(60,7)
[1] 8 4
#
# Dati un po' di numeri posso calcolare la somma e la media così
d <- c(10, 25, 8); sum(d); mean(d)
[1] 43
[1] 14.33333
# Gli input possono essere introdotti da tastiera mediante il comando scan (che
# serve anche per leggere dati da altri documenti - vedi - e per leggere "parole" se
# si aggiunge ,what="character"); ecco come calcolare somma e media di un qualunque
# numero di dati introdotti da tastiera (con file="" si specifica che i dati non
# sono letti da alcun file, con n= si specifica quanti sono i dati da leggere):
nd <- scan(file="",n=1); d <- scan(file="",n=nd); print(c(sum(d),mean(d)))
# Introduco 3 (n. dei dati) e 10,25,8 (i dati) separati ciascuno da un "a capo":
1: 3
Read 1 item
1: 10
2: 25
3: 8
Read 3 items
[1] 43.00000 14.33333
# Usando write con l'opzione file="" (vedi più avanti) ottengo una stampa in cui
# anche se una sola delle uscite è intera essa viene visulizzata senza gli "0"
write(c(sum(d), mean(d)), file="")
43 14.33333
# Volendo potevo battere i dati su una sola riga specificando il "separatore":
d <- scan(file="",n=3,sep=";")
1: 10; 25; 8
Read 3 items
# Potevo avere lo stesso esito anche copiando le 3 righe seguenti:
nd <- scan(file="",n=1); d <- scan(file="",n=nd,sep=","); print(c(sum(d),mean(d)))
3
10, 25, 8
#
# Se come file metto "clipboard" posso leggere (o scrivere) dati dalla (nella)
# memoria volatile del computer. Se ad esempio scrivo il comando seguente e
# prima di premere Invio copio i dati presenti qui e li metto in "valori"
valori <- scan(file="clipboard")
Read 5 items
# poi posso ad es. comandare:
valori; mean(valori)
[1] 125.0 12.7 145.0 167.0 95.6
[1] 109.06
# Analogamente posso scrivere dei dati in memoria, ad es. con:
x <- c(1,2,3); write(x,file="clipboard")
#
# Un esempio di ciclo for:
# "per k che va da 0 ad n scrivi Cbin(n,k)"
n <- 6; for(k in 0:n) print(choose(n,k))
[1] 1
[1] 6
[1] 15
[1] 20
[1] 15
[1] 6
[1] 1
# ma (in questo caso) si può fare a meno del for, così:
print(choose(n,0:n))
[1] 1 6 15 20 15 6 1
# in for posso far variare l'indice su insiemi qualunque
n <- 6; for(k in c(1,3,5)) print(choose(n,k))
# o: n <- 6; k <- c(1,3,5); print(choose(n,k))
[1] 6
[1] 20
[1] 6
# Volendo stampare anche n e k possiamo procedere così, dove l'opzione
# quote=FALSE evita la stampa delle "virgolette":
n <- 6; for(k in 0:n) print(c('n,k = ',n,k,choose(n,k)), quote=FALSE)
[1] n,k = 6 0 1
[1] n,k = 6 1 6
[1] n,k = 6 2 15
[1] n,k = 6 3 20
[1] n,k = 6 4 15
[1] n,k = 6 5 6
[1] n,k = 6 6 1
# Potevo anche usare print(noquote(c('n,k = ',n,k,choose(n,k))))
# Se invece di for(…) usassi k <- 0:n non avrei le uscite in righe diverse
#
# Un modo più comodo è usare il comando cat, che concatena le uscite
# (\n serve per mandare a capo, su una nuova riga, le uscite):
n <- 6; for(k in 0:n) cat('n,k = ',n,k,choose(n,k),'\n')
n,k = 6 0 1
n,k = 6 1 6
n,k = 6 2 15
n,k = 6 3 20
n,k = 6 4 15
n,k = 6 5 6
n,k = 6 6 1
#
# Stampa dei divisori di n (fino a n pari a circa 250 mila è veloce)
# "per k che va da 1 ad n se n/k = parte intera di n/k scrivi k"
# i test "se ... allora ..." si scrivono "if (...) ..." usando == invece di =
n <- 68; for(k in 1:n) if (n/k==floor(n/k)) print(k)
[1] 1
[1] 2
[1] 4
[1] 17
[1] 34
[1] 68
# switch(n, a,b,c,…) assume il valore n-esimo tra a,b,…; esempio:
switch(4, 1/1, 1/2, 1/3, 1/4, 1/5, 1/6)
[1] 0.25
# switch(parola, p1=X, p2=Y, …) assume il valore X o Y o … se parola è p1 o p2 o …
chi <- function(colo) switch(colo, bionda="Bea", rossa="Lia", mora="Rosa")
chi("rossa")
[1] "Lia"
anni <- function(nome) switch(nome,Bea=19,Lia=21,Rosa=22)
anni("Lia")
[1] 21
# La scomposizione di un numero naturale in numeri primi con un ciclo while
# ({ e } consentono di raggruppare più comandi)
n<-68; k<-2; while (k<=n) if (n/k==floor(n/k)) {print(k); n<-n/k} else k<-k+1
[1] 2
[1] 2
[1] 17
# Per avere le uscite su una stessa riga posso fare (usando NULL
# per avviare l'uso di una variabile senza assegnarle valori):
n <- 1234567890
m <- NULL; k<-2; while(k<=n) if (n/k==floor(n/k)) {m <- c(m,k); n<-n/k} else k<-k+1; m
[1] 2 3 3 5 3607 3803
# Per uscire anzitempo da un ciclo for o while puoi usare break:
for(n in 80:100) {k<-2; while (k<n) if (n/k==floor(n/k)) break else k <- k+1; if (k==n) print(n)}
# ottieni: 83 89 97 (numeri primi tra 80 e 100)
#
# In tutte le condizioni occorre usare == invece di =
2=5
Error in 2 = 5 : invalid (do_set) left-hand side to assignment
2==5; 2<5; 5>=2
[1] FALSE
[1] TRUE
[1] TRUE
# Un altro esempio di uso di while (per il calcolo del fattoriale):
fat <- function(N) {A <- 1; B <- 0; while(B < N)
{B <- B+1; A <- A*B}; A}
fat(5); fat(170)
[1] 120
[1] 7.257416e+306
# Con while e scan puoi ripetere gli input; batti il tasto ESC quando
# hai finito; esempio (calcolo del rapporto percentuale tra un totale
# e dati via via introdotti):
tot <- 1500; perc <- 100/tot
while(TRUE) {d <- scan(file="",n=1); print(d*perc)}
1: 150
Read 1 item
[1] 10
1: 250
Read 1 item
[1] 16.66667
#
# Posso estrarre dei "sottoinsiemi" da una collezione di oggetti con subset
# specificando la condizione che li caratterizza.
a <- c(1,2,3,4,5,6,7,8); subset(a, a^3 >= 125)
[1] 5 6 7 8
# Come connettivi per AND, OR e NOT si usano &, | e ! (!= sta per ≠)
# Al posto di P XOR Q (aut) si usa xor(P,Q).
1>2 & 3/2<2; 1>2 | 3/2<2; !(1>2 & 3/2<2); 3!=3; 3!=1
[1] FALSE
[1] TRUE
[1] TRUE
[1] FALSE
[1] TRUE
3>2 | 5>2; xor(3>2, 5>2); xor(3>2, 2>5)
[1] TRUE
[1] FALSE
[1] TRUE
# NOTA: invece di TRUE e FALSE si possono usare 1 e 0
!1; xor(1,0)
[1] FALSE
[1] TRUE
#
# ls() fa la lista delle variabili definite, rm(elenco) rimuove
# una o più variabili; rm(list=ls()) le rimuove tutte; si può,
# in alternativa, azionare Remove all objects dal menu Misc
# [dallo stesso menu puoi azionare un comando analogo a ls()]
# ls.str() specifica anche gli eventuali parametri delle definizioni
ls()
[1] "a" "b" "k" "n" "pippo" "x" "y"
rm(n); ls()
[1] "a" "b" "k" "pippo" "x" "y"
rm(a,y); ls()
[1] "b" "k" "pippo" "x"
rm(list=ls()); ls()
character(0)
#
# come definire delle funzioni, a 1, a 2 e a 3 input
# (è bene non usare c come nome di funz. perché usato per le collez. di oggetti)
f <- function(x) x/5+1; g <- function(x,y) x/y+3; h <- function(x,y,z) x/y+z
f(3); g(5,-1); h(10,5,6)
[1] 1.6
[1] -2
[1] 8
perc <- function(dato,totale) dato/totale*100; perc(140,1357); perc(17,17)
[1] 10.31688
[1] 100
p <- function(x) (x^2+x+1)^2 + 1/(x^2+x+1) + x^2+x+1
q <- function(x) {t <- x^2+x+1; t^2 + 1/t + t}
p(7); q(7)
[1] 3306.018
[1] 3306.018
# Le funzioni possono essere anche a 0 input. Esempio (senza preoccuparci
# per adesso dell'istruzione "format(...)" che dà l'ora):
ora <- function() format(Sys.time(),"%H:%M:%S")
ora()
[1] "16:42:06"
ora()
[1] "16:42:13"
# Non metto l'input ed ogni volta che batto ora() ho la visualizzazione dell'ora
#
# Ricordiamo che una funzione in matematica e informatica è una associazione ad input
# di eventuali output in modo univoco (in alcuni linguaggi di programmazione le fun-
# zioni che non hanno output sono chiamate procedure); in matematica, quando non si
# considerano gli aspetti algoritmici, due descrizioni diverse di modi di associare
# input ad output che mettano in corrispondenza gli stessi oggetti sono considerati
# rappresentare la stessa funzione. Vedi qui per alcuni esempi. Come spesso si fa in
# logica, le costanti possono essere considerate delle funzioni a 0 input; esempio:
F <- function() 3; F()
[1] 3
# Per un esempio più significativo, vedi qui, in fondo.
#
# NOTA: nella definizione della function q ho usato la variabile t come variabile
# locale: essa non crea alcun conflitto con l'eventuale uso di variabili con lo
# stesso nome impiegate all'esterno della definizione, prima o dopo di essa. Se
# invece usassi t <<- x^2+x+1 l'assegnazione sarebbe alla variabile "globale" t.
# [osserviamo che nelle assegnazioni al posto di w <- 7 o 7 -> w si potrebbe
# usare w = 7; non si potrebbe però usare 7 = w. Inoltre, in alcuni casi le
# assegnazioni con "=" al posto di "->" e "<-" non funzionano. Non c'è modo,
# poi, con "=", di realizzare assegnazioni globali. È bene abituarsi a non
# usare questa modalità di effettuare le assegnazioni]
#
# Con body posso ottenere il termine usato per definire una funzione:
body(p)
(x^2+x+1)^2 + 1/(x^2+x+1) + x^2+x+1
# battendo il nome della funzione potrei comunque richiamarne la definizione:
p
function(x) (x^2+x+1)^2 + 1/(x^2+x+1) + x^2+x+1
#
# Ecco come ottenere in modo semplice il grafico di una funzione con plot;
# la scala è scelta automaticamente. Le immagini grafiche possono essere
# ridimensionate azionando i margini della rispettiva finestra.
# La finestra dei grafici appare affiancata. Coi comandi del menu Windows,
# oltre che operando col mouse, si possono cambiare le modalità di
# visualizzazione e le dimensioni delle finestre via via aperte.
f <- function(x) x^2-5; f(-5); f(0); f(10); plot(f,-5,5)
[1] 20
[1] -5
[1] 95
# In realtà il grafico seguente è stato scritto col comando che segue, in cui
# è aggiunta l'opzione las=1 (labels=etichette) per avere le scritte sull'asse
# y orizzontali; in quello al centro si è aggiunto las=2 (opzioni comode se i
# numeri sono lunghi) e si è messo lwd=2 (line width) per raddoppiare lo spessore
# della curva; con ad es. cex.axis=0.7 posso rimpicciolire le scritte sugli assi
# e con cex.lab=0.7 (o 0.8, …) posso rimpicciolire le etichette (x, f(x), …)
plot(f,-5,10,las=1)
plot(f,-5,10,las=2, lwd=2)
 # Il grafico a destra è ottenuto con (vedi e vedi):
plot(f,-5,10,ylim=c(-20,100),las=1)
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
# Potevo anche battere direttamente plot(x <- function(x) x^2-5,-5,5)
# Volendo si può cambiare il font delle "scritte"; prova con
# plot(f,-5,10,font=10) o con font=11 o font=5.
#
# Posso ridurre il margine dei grafici usando il comando par (PARametri grafici)
# con l'opzione mai (MArgini Interni, in pollici): a sinistra il grafico ottenuto
# normalmente con l'aggiunta di un titolo col comando title("grafico di f") [posso
# aggiungere ,cex.main=1 per ridurne le dimensioni], a destra quello ottenuto con:
par( mai = c(0.5,0.5,0.1,0.1) ); plot(f, -5,10)
# Il grafico a destra è ottenuto con (vedi e vedi):
plot(f,-5,10,ylim=c(-20,100),las=1)
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
# Potevo anche battere direttamente plot(x <- function(x) x^2-5,-5,5)
# Volendo si può cambiare il font delle "scritte"; prova con
# plot(f,-5,10,font=10) o con font=11 o font=5.
#
# Posso ridurre il margine dei grafici usando il comando par (PARametri grafici)
# con l'opzione mai (MArgini Interni, in pollici): a sinistra il grafico ottenuto
# normalmente con l'aggiunta di un titolo col comando title("grafico di f") [posso
# aggiungere ,cex.main=1 per ridurne le dimensioni], a destra quello ottenuto con:
par( mai = c(0.5,0.5,0.1,0.1) ); plot(f, -5,10)
 #
# I grafici di tre funzioni a 1 input e 1 output con curve (con cui non
# è necessario - ma è possibile - specificare il dominio) e l'opzione add
# (ci sono anche altri modi per ottenerli) e plot per scegliere la scala:
# la 3ª riga riserva lo spazio per il rettangolo con ascissa da -5 a 5 e
# ordinata da -5 ad 8 (questi valori sono memorizzati nelle variabili x1,x2,…
# ma potrebbero essere messi direttamente in c(.,.), ovviamente) e non lo
# traccia (type="n"), e non mette etichette agli assi (xlab="", ylab="");
# con fg="white" non traccio il box, con xaxt="n",yaxt="n" ascisse/ordinate.
# La 4ª traccia gli assi y=0 e x=0 in marrone , che vengono ritracciati
# parzialmente con le tacche mediante i comandi della 5ª riga (label=FALSE
# evita che siano scritte le coordinate anche a vicino agli assi); poi
# vengono tracciati, uno dopo l'altro, i grafici di tre funzioni. I comandi
# sono copiabili facilmente da qui e, poi, modificabili.
f <- function(x) x*2-1; g <- function(x) x^2-1; h <- function(x) x/2-1
x1 <- -5; x2 <- 5; y1 <- -5; y2 <- 8
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
# al centro il grafico con ,fg="white" a destra con anche ,xaxt="n",yaxt="n"
abline(h=0,v=0,col="brown")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
curve(f, add=TRUE,col="red"); curve(g, add=TRUE,col="blue")
curve(h, add=TRUE)
#
# I grafici di tre funzioni a 1 input e 1 output con curve (con cui non
# è necessario - ma è possibile - specificare il dominio) e l'opzione add
# (ci sono anche altri modi per ottenerli) e plot per scegliere la scala:
# la 3ª riga riserva lo spazio per il rettangolo con ascissa da -5 a 5 e
# ordinata da -5 ad 8 (questi valori sono memorizzati nelle variabili x1,x2,…
# ma potrebbero essere messi direttamente in c(.,.), ovviamente) e non lo
# traccia (type="n"), e non mette etichette agli assi (xlab="", ylab="");
# con fg="white" non traccio il box, con xaxt="n",yaxt="n" ascisse/ordinate.
# La 4ª traccia gli assi y=0 e x=0 in marrone , che vengono ritracciati
# parzialmente con le tacche mediante i comandi della 5ª riga (label=FALSE
# evita che siano scritte le coordinate anche a vicino agli assi); poi
# vengono tracciati, uno dopo l'altro, i grafici di tre funzioni. I comandi
# sono copiabili facilmente da qui e, poi, modificabili.
f <- function(x) x*2-1; g <- function(x) x^2-1; h <- function(x) x/2-1
x1 <- -5; x2 <- 5; y1 <- -5; y2 <- 8
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
# al centro il grafico con ,fg="white" a destra con anche ,xaxt="n",yaxt="n"
abline(h=0,v=0,col="brown")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
curve(f, add=TRUE,col="red"); curve(g, add=TRUE,col="blue")
curve(h, add=TRUE)
 # con l'opzione at posso specificare dove tracciare le tacche
axis(1,pos=0,label=FALSE,col="brown",at=c(-3,-1,1,3))
# con l'opzione at posso specificare dove tracciare le tacche
axis(1,pos=0,label=FALSE,col="brown",at=c(-3,-1,1,3))
 # abline(h=...) o abline(v=...) traccia rette orizzontali o verticali;
# nella forma abline(a, b, ...) traccia la retta y = a + bx
x1 <- -4; x2 <- 4; y1 <- -4; y2 <- 4
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
abline(h=0,v=0,col="brown")
abline(-1, 1/2 ,col="black"); abline(h = -1,col="grey")
# abline(h=...) o abline(v=...) traccia rette orizzontali o verticali;
# nella forma abline(a, b, ...) traccia la retta y = a + bx
x1 <- -4; x2 <- 4; y1 <- -4; y2 <- 4
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
abline(h=0,v=0,col="brown")
abline(-1, 1/2 ,col="black"); abline(h = -1,col="grey")
 # un modo diverso di memorizzare e introdurre la scala e la
# possibilità di rappresentare il grafico su un sottointervallo
# (vediamo, anche, come ottenere una griglia)
# con from ... to ... in curve
coor <- c(-4,4,-4,4); orig <- c(0,0)
xx <- c(-4,-3,-2,-1,1,2,3,4); yy <- xx
plot(c(coor[1],coor[2]),c(coor[3],coor[4]),type="n",xlab="",ylab="")
abline(h = xx,col="grey"); abline(v = yy, col="grey")
axis(1,pos=orig[2],label=FALSE,col="brown"); axis(2,pos=orig[1],label=FALSE,col="brown")
h <- function(x) x/2-1
curve(h, add=TRUE,col="blue", from=-3, to=3)
# un modo diverso di memorizzare e introdurre la scala e la
# possibilità di rappresentare il grafico su un sottointervallo
# (vediamo, anche, come ottenere una griglia)
# con from ... to ... in curve
coor <- c(-4,4,-4,4); orig <- c(0,0)
xx <- c(-4,-3,-2,-1,1,2,3,4); yy <- xx
plot(c(coor[1],coor[2]),c(coor[3],coor[4]),type="n",xlab="",ylab="")
abline(h = xx,col="grey"); abline(v = yy, col="grey")
axis(1,pos=orig[2],label=FALSE,col="brown"); axis(2,pos=orig[1],label=FALSE,col="brown")
h <- function(x) x/2-1
curve(h, add=TRUE,col="blue", from=-3, to=3)
 # Il comando pretty consente di individuare valori pari a 1, 2 o 5
# volte una potenza di 10; è comodo per tracciare tacche e griglie.
pretty( (-1:15)/10, n=5) #o: pretty( (-1:15)/10, 5)
[1] -0.5 0.0 0.5 1.0 1.5
# Ottengo circa 5 valori circa tra -0.1 e 1.5
# Ecco il suo comodo impiego per tracciare una griglia a coord. intere:
a <- -5; b <- 5; c <- -5; d <- 10
plot(c(a,b),c(c,d),type="n",xlab="",ylab="")
abline(v=pretty(a:b, 10),h=pretty(c:d, 10),col="blue",lty=3)
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
# Una griglia meno fitta
plot(c(a,b),c(c,d),type="n",xlab="",ylab="")
abline(v=pretty(a:b, 5),h=pretty(c:d, 5),col="blue",lty=3)
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
# Un modo comodissimo per tracciare griglie è usare il comando axTicks (vengono
# posizionate in ascisse/ordiante pari a 1, 2 o 5 volte una potenza di 10; con
# (1) vengono assegnate le ascisse delle rette verticali, con (2) le ordinate
# delle rette orizzontali; posso usare anche solo h=... o v=...)
# Ottengo (come con i comandi precedenti) il grafico sotto a destra:
plot(c(-5,5),c(-5,10),type="n",xlab="",ylab="")
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
# Il comando pretty consente di individuare valori pari a 1, 2 o 5
# volte una potenza di 10; è comodo per tracciare tacche e griglie.
pretty( (-1:15)/10, n=5) #o: pretty( (-1:15)/10, 5)
[1] -0.5 0.0 0.5 1.0 1.5
# Ottengo circa 5 valori circa tra -0.1 e 1.5
# Ecco il suo comodo impiego per tracciare una griglia a coord. intere:
a <- -5; b <- 5; c <- -5; d <- 10
plot(c(a,b),c(c,d),type="n",xlab="",ylab="")
abline(v=pretty(a:b, 10),h=pretty(c:d, 10),col="blue",lty=3)
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
# Una griglia meno fitta
plot(c(a,b),c(c,d),type="n",xlab="",ylab="")
abline(v=pretty(a:b, 5),h=pretty(c:d, 5),col="blue",lty=3)
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
# Un modo comodissimo per tracciare griglie è usare il comando axTicks (vengono
# posizionate in ascisse/ordiante pari a 1, 2 o 5 volte una potenza di 10; con
# (1) vengono assegnate le ascisse delle rette verticali, con (2) le ordinate
# delle rette orizzontali; posso usare anche solo h=... o v=...)
# Ottengo (come con i comandi precedenti) il grafico sotto a destra:
plot(c(-5,5),c(-5,10),type="n",xlab="",ylab="")
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
 # altro esempio di tracciamento di tacche: vedi.
# altro esempio di tracciamento di tacche: vedi.
 #
# Il comando mtext consente di scrivere testi, coordinate, ... ai margini
# dei grafici. Vedi qui per come ottenere il grafico seguente:
#
#
# Il comando mtext consente di scrivere testi, coordinate, ... ai margini
# dei grafici. Vedi qui per come ottenere il grafico seguente:
#
 # I colori usabili sono centinaia; i nomi sono elencati dal comando colors(); non
# mettere il colore è come scegliere black (eccone alcuni: white yellow yellow3
# yellow4 green green4 violet purple pink coral red magenta magenta4 orange brown
# cyan [ciano, tra azzurro e verde chiaro] cyan4 blue blue4 grey grey50 black).
# Scegliere come colore white traccia il bianco, scegliere NULL non traccia nulla.
# (i colori sono chiamabili anche usando le coordinate RossoVerdeBlu: vedi)
# Ecco come aggiungere (al grafico di g <- function(x) x^2-1) la curva
# y^2/10+1 = x tracciata mediante 2000 segmentini: lines(p,q,...) traccia la
# poligonale (ossia l'insieme dei segmenti) con vertici i punti (p,q) dove p e q
# sono i valori descritti in funzione di t, con t che varia tra t1 e t2.
plot(c(-5,5),c(-5,8),type="n",xlab="",ylab="")
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
abline(v=0, h=0, col="blue",lty=2)
g <- function(x) x^2-1; curve(g,col="brown",add=TRUE)
t1 <- -5; t2 <- 8; punti <- 2001; t <- seq(t1,t2,(t2-t1)/punti)
lines(t^2/10+1,t,col="orange")
# I colori usabili sono centinaia; i nomi sono elencati dal comando colors(); non
# mettere il colore è come scegliere black (eccone alcuni: white yellow yellow3
# yellow4 green green4 violet purple pink coral red magenta magenta4 orange brown
# cyan [ciano, tra azzurro e verde chiaro] cyan4 blue blue4 grey grey50 black).
# Scegliere come colore white traccia il bianco, scegliere NULL non traccia nulla.
# (i colori sono chiamabili anche usando le coordinate RossoVerdeBlu: vedi)
# Ecco come aggiungere (al grafico di g <- function(x) x^2-1) la curva
# y^2/10+1 = x tracciata mediante 2000 segmentini: lines(p,q,...) traccia la
# poligonale (ossia l'insieme dei segmenti) con vertici i punti (p,q) dove p e q
# sono i valori descritti in funzione di t, con t che varia tra t1 e t2.
plot(c(-5,5),c(-5,8),type="n",xlab="",ylab="")
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
abline(v=0, h=0, col="blue",lty=2)
g <- function(x) x^2-1; curve(g,col="brown",add=TRUE)
t1 <- -5; t2 <- 8; punti <- 2001; t <- seq(t1,t2,(t2-t1)/punti)
lines(t^2/10+1,t,col="orange")
 # Un altro modo per ottenere il tracciamento di una griglia
x1 <- -5; x2 <- 5; y1 <- -5; y2 <- 8
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
for(i in c(-4,-2,2,4)) abline(v=i,col="grey")
for(i in c(-4,-2,2,4,6,8)) abline(h=i,col="grey")
abline(h=0,col="brown"); abline(v=0,col="brown")
curve(f, add=TRUE,col="red"); curve(g, add=TRUE,col="blue")
curve(h, add=TRUE)
# Un altro modo per ottenere il tracciamento di una griglia
x1 <- -5; x2 <- 5; y1 <- -5; y2 <- 8
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
for(i in c(-4,-2,2,4)) abline(v=i,col="grey")
for(i in c(-4,-2,2,4,6,8)) abline(h=i,col="grey")
abline(h=0,col="brown"); abline(v=0,col="brown")
curve(f, add=TRUE,col="red"); curve(g, add=TRUE,col="blue")
curve(h, add=TRUE)
 # altro modo di tracciare una griglia (nota:
# (-10:16)/2 sta per da -5 a 8 con passo 1/2):
x1 <- -5; x2 <- 5; y1 <- -5; y2 <- 8
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
for(i in (-10:16)/2) abline(h=i,col="grey")
for(i in (-10:10)/2) abline(v=i,col="grey")
abline(h=0,col="brown"); abline(v=0,col="brown")
# altro modo di tracciare una griglia (nota:
# (-10:16)/2 sta per da -5 a 8 con passo 1/2):
x1 <- -5; x2 <- 5; y1 <- -5; y2 <- 8
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
for(i in (-10:16)/2) abline(h=i,col="grey")
for(i in (-10:10)/2) abline(v=i,col="grey")
abline(h=0,col="brown"); abline(v=0,col="brown")
 # Un'altra possibilità (vedi fig. sopra a destra): lty ( line type) specifica il
# tratto di linea (0,1,2,3,4-6: nessuna, piena, tratteggio medio, tr.piccolo, altri tr.)
plot( c(-5,5), c(-5,8), type="n")
abline(h=seq(-5,8,1),v=seq(-5,5,1),lty=3,col="grey60")
abline(h=0,v=0,lty=2)
#
# Se a plot aggiungo asp=1 ottengo l'aspetto in cui il rapporto tra
# le unità sui due assi è 1, ossia ho un sistema monometrico.
# Nota: ridimensionando col mouse la finestra grafica la scala
# rimane monometrica.
x1 <- -6; x2 <- 6; y1 <- -3; y2 <- 9
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="", asp=1)
for(i in c(-6,-4,-2,2,4,6)) abline(v=i,col="grey")
for(i in c(-2,2,4,6,8)) abline(h=i,col="grey")
abline(h=0,col="brown"); abline(v=0,col="brown")
curve(f, add=TRUE,col="red"); curve(g, add=TRUE,col="blue")
curve(h, add=TRUE)
# Un'altra possibilità (vedi fig. sopra a destra): lty ( line type) specifica il
# tratto di linea (0,1,2,3,4-6: nessuna, piena, tratteggio medio, tr.piccolo, altri tr.)
plot( c(-5,5), c(-5,8), type="n")
abline(h=seq(-5,8,1),v=seq(-5,5,1),lty=3,col="grey60")
abline(h=0,v=0,lty=2)
#
# Se a plot aggiungo asp=1 ottengo l'aspetto in cui il rapporto tra
# le unità sui due assi è 1, ossia ho un sistema monometrico.
# Nota: ridimensionando col mouse la finestra grafica la scala
# rimane monometrica.
x1 <- -6; x2 <- 6; y1 <- -3; y2 <- 9
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="", asp=1)
for(i in c(-6,-4,-2,2,4,6)) abline(v=i,col="grey")
for(i in c(-2,2,4,6,8)) abline(h=i,col="grey")
abline(h=0,col="brown"); abline(v=0,col="brown")
curve(f, add=TRUE,col="red"); curve(g, add=TRUE,col="blue")
curve(h, add=TRUE)
 # Sopra, al centro, il tracciamento dell'asse di un segmento, descritto qui.
# Sotto come tracciare un reticolato monometrico, come quello sopra a
# destra, utile come base per realizzare figure geometriche.
par( mai = c(0,0,0,0) )
plot(c(-1,11),c(-1,11),type="n",fg="white",asp=1)
x <- seq(-1,11,1); abline(h=x,v=x,lty=3,col="grey")
abline(h=c(0,5,10),v=c(0,5,10),col="grey50",lty=2)
# Un modo semplice, alternativo, per tracciare un altro:
par( mai = c(0,0,0,0) )
plot(c(-1,11),c(-1,11),type="n",fg="white",asp=1)
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=2)
# Capito come tracciare le figure si può rifare il disegno senza le
# ultime due righe.
#
# Ecco cosa appare con asp pari ad 1/2:
x1 <- -3; x2 <- 3; y1 <- -3; y2 <- 9
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="", asp=1/2)
for(i in c(-2,2)) abline(v=i,col="grey")
for(i in c(-2,2,4,6,8)) abline(h=i,col="grey")
abline(h=0,col="brown"); abline(v=0,col="brown")
curve(f, add=TRUE,col="red"); curve(g, add=TRUE,col="blue")
curve(h, add=TRUE)
# Sopra, al centro, il tracciamento dell'asse di un segmento, descritto qui.
# Sotto come tracciare un reticolato monometrico, come quello sopra a
# destra, utile come base per realizzare figure geometriche.
par( mai = c(0,0,0,0) )
plot(c(-1,11),c(-1,11),type="n",fg="white",asp=1)
x <- seq(-1,11,1); abline(h=x,v=x,lty=3,col="grey")
abline(h=c(0,5,10),v=c(0,5,10),col="grey50",lty=2)
# Un modo semplice, alternativo, per tracciare un altro:
par( mai = c(0,0,0,0) )
plot(c(-1,11),c(-1,11),type="n",fg="white",asp=1)
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=2)
# Capito come tracciare le figure si può rifare il disegno senza le
# ultime due righe.
#
# Ecco cosa appare con asp pari ad 1/2:
x1 <- -3; x2 <- 3; y1 <- -3; y2 <- 9
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="", asp=1/2)
for(i in c(-2,2)) abline(v=i,col="grey")
for(i in c(-2,2,4,6,8)) abline(h=i,col="grey")
abline(h=0,col="brown"); abline(v=0,col="brown")
curve(f, add=TRUE,col="red"); curve(g, add=TRUE,col="blue")
curve(h, add=TRUE)
 # asp si può mettere anche in plot; gli assi con pos possono essere
# fatti passare non per l'origine (0,0)
f <- function(x) 0.1*(x-100)^2-30
plot(f,90,110,asp=1)
abline(h=-30,col="brown"); abline(v=100,col="brown")
axis(1,pos=-30,label=FALSE,col="brown"); axis(2,pos=100,label=FALSE,col="brown")
# asp si può mettere anche in plot; gli assi con pos possono essere
# fatti passare non per l'origine (0,0)
f <- function(x) 0.1*(x-100)^2-30
plot(f,90,110,asp=1)
abline(h=-30,col="brown"); abline(v=100,col="brown")
axis(1,pos=-30,label=FALSE,col="brown"); axis(2,pos=100,label=FALSE,col="brown")
 # ifelse consente di assegnare valori sotto condizioni;
# ecco come ottenere il grafico di due funzioni con salto:
x1 <- -5; x2 <- 5; y1 <- -10; y2 <- 10
f <- function(x) ifelse(x>=2, -6, 7)
g <- function(x) 1/x
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
abline(h=0,col="brown"); abline(v=0,col="brown")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
curve(g, x1,-0.01, add=TRUE,col="red")
curve(g, 0.01,x2, add=TRUE,col="red")
curve(f, x1,2-0.01,add=TRUE,col="blue")
curve(f, 2+0.01,x2,add=TRUE,col="blue")
# ifelse consente di assegnare valori sotto condizioni;
# ecco come ottenere il grafico di due funzioni con salto:
x1 <- -5; x2 <- 5; y1 <- -10; y2 <- 10
f <- function(x) ifelse(x>=2, -6, 7)
g <- function(x) 1/x
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
abline(h=0,col="brown"); abline(v=0,col="brown")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
curve(g, x1,-0.01, add=TRUE,col="red")
curve(g, 0.01,x2, add=TRUE,col="red")
curve(f, x1,2-0.01,add=TRUE,col="blue")
curve(f, 2+0.01,x2,add=TRUE,col="blue")
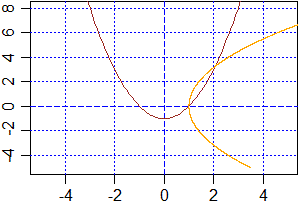
 # Nota. Usando ifelse si possono ottenere dei messaggi come questo:
k <- function(x) ifelse(x >= 0,x^2,sqrt(-x))
plot(k,-4,2,asp=1); abline(h=0,v=0,col="red")
Warning message: In sqrt(-x) : NaNs produced
# Nota. Usando ifelse si possono ottenere dei messaggi come questo:
k <- function(x) ifelse(x >= 0,x^2,sqrt(-x))
plot(k,-4,2,asp=1); abline(h=0,v=0,col="red")
Warning message: In sqrt(-x) : NaNs produced
 # con cui si segnala che sqrt(-x) non è calcolabile per alcuni valori: per x ≥ 0 il
# programma calcola anche sqrt(-x) pur se assegna il valore x^2; per questo viene
# visualizzato il messaggio, anche se ciò non influenza il tracciamento del grafico
#
# In alternativa, con curve o plot, traccio i grafici per punti mettendo type="p"
# Ad n occorre assegnare il numero dei punti
curve(f, add=TRUE,col="blue",n=1000, type="p")
curve(g, add=TRUE,col="red",n=10000, type="p")
# con cui si segnala che sqrt(-x) non è calcolabile per alcuni valori: per x ≥ 0 il
# programma calcola anche sqrt(-x) pur se assegna il valore x^2; per questo viene
# visualizzato il messaggio, anche se ciò non influenza il tracciamento del grafico
#
# In alternativa, con curve o plot, traccio i grafici per punti mettendo type="p"
# Ad n occorre assegnare il numero dei punti
curve(f, add=TRUE,col="blue",n=1000, type="p")
curve(g, add=TRUE,col="red",n=10000, type="p")
 # aggiungendo pch="." (Plotting CHaracter) avrei ottenuto punti piccoli, con
# pch=20 intermedi.
curve(f, add=TRUE,col="blue",n=1000, type="p", pch=".")
curve(g, add=TRUE,col="red",n=10000, type="p", pch=".")
#
# una tabella di dati può essere anche recuperata dal computer o in rete;
# ad esempio col comando readLines posso esaminare le prime (qui 3) righe
# di un file (il file ha questo contenuto):
readLines("http://macosa.dima.unige.it/om/prg/stf/altomas.txt",n=3)
[1] "'record alto maschi dal 32 ogni 4 anni"
[2] "1932,203"
[3] "1936,207"
# Se era sul computer potevo metterne solo il nome (senza il percorso) e selezionare
# la cartella in cui era col comando Change dir dal menu File, ovvero battendo
# setwd("C:/...") e mettendo in … il percorso - usando "/", non "\" (questo comando
# è comodo da memorizzare e copiare - o caricare - se si usano spesso file da una
# particolare cartella); getwd() specifica il percorso corrente. file.show("C:/...")
# consente invece di visualizzare in una nuova finestra un qualunque file di testo.
#
# È una tabella; salto (con skip) 1 riga di commento e ne visualizzo
# 2 righe (rows) col comando read.table; i dati sono separati da ",".
read.table("http://macosa.dima.unige.it/om/prg/stf/altomas.txt",sep=",",skip=1, nrows=2)
V1 V2
1 1932 203
2 1936 207
# V1 e V2 sono i nomi che il programma dà alle due variabili. Metto tutta
# la tabella in un'unica variabile (la chiamo hm: alto maschi) e ne
# visualizzo le dimensioni con dim (20 righe e 2 colonne)
hm <- read.table("http://macosa.dima.unige.it/om/prg/stf/altomas.txt",sep=",",skip=1)
dim(hm)
[1] 20 2
# Con $ posso estrarre le colonne:
c(min(hm$V1),max(hm$V1),min(hm$V2),max(hm$V2))
[1] 1932 2008 203 245
# La prima colonna va da 1932 a 2008, la seconda da 203 a 245
# Leggo un altro file e procedo in modo simile:
readLines("http://macosa.dima.unige.it/om/prg/stf/altofem.txt",n=3)
[1] "'record alto femmine dal 32 ogni 4 anni"
[2] "1932,165"
[3] "1936,166"
hf <- read.table("http://macosa.dima.unige.it/om/prg/stf/altofem.txt",sep=",",skip=1);dim(hf)
[1] 20 2
c(min(hf$V1),max(hf$V1),min(hf$V2),max(hf$V2))
[1] 1932 2008 165 209
# Traccio il grafico per punti di hm con y tra 160 e 250
# (ylim delimita l'intervallo delle "y" di plot; analogamente potrei
# usare xlim per scegliere l'intervallo delle "x"; plot può essere usato
# anche per tracciare punti: plot(x,y) traccia i punti aventi ascisse
# memorizzate in x ed ordinate memorizzate in y)
plot(hm$V1,hm$V2, ylim=c(160,250),col="blue",xlab="",ylab="")
# Aggiungo quello di hf e congiungo i punti
points(hf$V1,hf$V2,col="red"); lines(hf$V1,hf$V2,col="red"); lines(hm$V1,hm$V2,col="blue")
# Traccio una griglia:
abline(h=seq(160,250,10),v=seq(1935,2005,5),lty=3,col="grey50")
# aggiungendo pch="." (Plotting CHaracter) avrei ottenuto punti piccoli, con
# pch=20 intermedi.
curve(f, add=TRUE,col="blue",n=1000, type="p", pch=".")
curve(g, add=TRUE,col="red",n=10000, type="p", pch=".")
#
# una tabella di dati può essere anche recuperata dal computer o in rete;
# ad esempio col comando readLines posso esaminare le prime (qui 3) righe
# di un file (il file ha questo contenuto):
readLines("http://macosa.dima.unige.it/om/prg/stf/altomas.txt",n=3)
[1] "'record alto maschi dal 32 ogni 4 anni"
[2] "1932,203"
[3] "1936,207"
# Se era sul computer potevo metterne solo il nome (senza il percorso) e selezionare
# la cartella in cui era col comando Change dir dal menu File, ovvero battendo
# setwd("C:/...") e mettendo in … il percorso - usando "/", non "\" (questo comando
# è comodo da memorizzare e copiare - o caricare - se si usano spesso file da una
# particolare cartella); getwd() specifica il percorso corrente. file.show("C:/...")
# consente invece di visualizzare in una nuova finestra un qualunque file di testo.
#
# È una tabella; salto (con skip) 1 riga di commento e ne visualizzo
# 2 righe (rows) col comando read.table; i dati sono separati da ",".
read.table("http://macosa.dima.unige.it/om/prg/stf/altomas.txt",sep=",",skip=1, nrows=2)
V1 V2
1 1932 203
2 1936 207
# V1 e V2 sono i nomi che il programma dà alle due variabili. Metto tutta
# la tabella in un'unica variabile (la chiamo hm: alto maschi) e ne
# visualizzo le dimensioni con dim (20 righe e 2 colonne)
hm <- read.table("http://macosa.dima.unige.it/om/prg/stf/altomas.txt",sep=",",skip=1)
dim(hm)
[1] 20 2
# Con $ posso estrarre le colonne:
c(min(hm$V1),max(hm$V1),min(hm$V2),max(hm$V2))
[1] 1932 2008 203 245
# La prima colonna va da 1932 a 2008, la seconda da 203 a 245
# Leggo un altro file e procedo in modo simile:
readLines("http://macosa.dima.unige.it/om/prg/stf/altofem.txt",n=3)
[1] "'record alto femmine dal 32 ogni 4 anni"
[2] "1932,165"
[3] "1936,166"
hf <- read.table("http://macosa.dima.unige.it/om/prg/stf/altofem.txt",sep=",",skip=1);dim(hf)
[1] 20 2
c(min(hf$V1),max(hf$V1),min(hf$V2),max(hf$V2))
[1] 1932 2008 165 209
# Traccio il grafico per punti di hm con y tra 160 e 250
# (ylim delimita l'intervallo delle "y" di plot; analogamente potrei
# usare xlim per scegliere l'intervallo delle "x"; plot può essere usato
# anche per tracciare punti: plot(x,y) traccia i punti aventi ascisse
# memorizzate in x ed ordinate memorizzate in y)
plot(hm$V1,hm$V2, ylim=c(160,250),col="blue",xlab="",ylab="")
# Aggiungo quello di hf e congiungo i punti
points(hf$V1,hf$V2,col="red"); lines(hf$V1,hf$V2,col="red"); lines(hm$V1,hm$V2,col="blue")
# Traccio una griglia:
abline(h=seq(160,250,10),v=seq(1935,2005,5),lty=3,col="grey50")
 # Ho ottenuto il grafico a sinistra. Ecco come ottenere quello a destra,
# dei numeri indici.
# Per rappresentare i numeri indici (= rapporto % col primo dato) ne metto
# i valori in indm e indf e poi procedo nel solito modo
indm <- hm$V2/hm$V2[1]*100; indf <- hf$V2/hf$V2[1]*100
c(min(indm),max(indm),min(indf),max(indf))
[1] 1932 2008 165 209
plot(hm$V1,indm, ylim=c(100,130),col="blue",xlab="",ylab="")
points(hf$V1,indf,col="red")
abline(h=seq(100,130,5),v=seq(1935,2005,5),lty=3,col="grey50")
lines(hf$V1,indf,col="red"); lines(hm$V1,indm,col="blue")
# Un altro esempio (vedi)
# Ho ottenuto il grafico a sinistra. Ecco come ottenere quello a destra,
# dei numeri indici.
# Per rappresentare i numeri indici (= rapporto % col primo dato) ne metto
# i valori in indm e indf e poi procedo nel solito modo
indm <- hm$V2/hm$V2[1]*100; indf <- hf$V2/hf$V2[1]*100
c(min(indm),max(indm),min(indf),max(indf))
[1] 1932 2008 165 209
plot(hm$V1,indm, ylim=c(100,130),col="blue",xlab="",ylab="")
points(hf$V1,indf,col="red")
abline(h=seq(100,130,5),v=seq(1935,2005,5),lty=3,col="grey50")
lines(hf$V1,indf,col="red"); lines(hm$V1,indm,col="blue")
# Un altro esempio (vedi)
 #
# Nota: i dati sono nella notazione standard, "inglese": la eventuale parte
# frazionaria di un numero è separata dalla parte intera da ".", non
# da ",". Se leggo una tabella di dati salvata in un foglio di calcolo
# impostato in lingua italiana come la seguente:
#
# Nota: i dati sono nella notazione standard, "inglese": la eventuale parte
# frazionaria di un numero è separata dalla parte intera da ".", non
# da ",". Se leggo una tabella di dati salvata in un foglio di calcolo
# impostato in lingua italiana come la seguente:
 | |
internamente:
2,3; 6,4
4,1; 5,2
1,3; 7,5
1,7; 8,9 |
# e la apro con
dati <- read.table("http://macosa.dima.unige.it/om/prg/R/tabe.csv", sep=";")
# ottengo 2,3 6,4 4,1 ... che il programma interpreta come coppie:
dati; min(dati)
V1 V2
1 2,3 6,4
2 4,1 5,2
3 1,3 7,5
4 1,7 8,9
Error ...
# Aggiungendo l'opzione dec="," posso correggere la cosa:
dati <- read.table("http://macosa.dima.unige.it/om/prg/R/tabe.csv",sep=";",dec=",")
dati; min(dati)
V1 V2
1 2.3 6.4
2 4.1 5.2
3 1.3 7.5
4 1.7 8.9
[1] 1.3
# Ovvero con (read.csv2) la "," viene automaticamente interpretata come "."
# (header=FALSE comunica al programma che le colonne non hanno intestazioni)
dati <- read.csv2("http://macosa.dima.unige.it/om/prg/R/tabe.csv",sep=";",header=FALSE)
# In "dati" ci sono gli stessi esiti ottenuti sopra con l'opzione dec=","
#
# Come detto, i comandi dati possono essere memorizzati usando il comando Save
# History. I grafici possono essere man mano rieseguiti usando i comandi;
# volendo, ecco come conviene salvare un'immagine. Si clicca su di essa e, dal
# menu che si apre cliccando, la si salva come BitMap e la si incolla su Paint
# (o un altro programma di grafica), si aggiunge quello che si vuole e la si
# ridimensiona. A questo punto o la si copia e salva nel documento in cui si
# sta operando o, da Paint, la si salva in formato GIF, che occupa poco spazio
# e consente di operare successive modifiche, anche dettagliate, con Paint
# (nelle ultime versioni di Windows, conviene, prima di salvarlo, farsi una
# copia del file, quindi memorizzarlo come GIF, attendere un messaggio che
# dice che l'immagine non è salvata perfettamente, quindi incollare l'immagine
# memorizzata e fare Save: l'immagine a questo punto è perfetta; se essa viene
# incollata su una figura già salvata come gif e poi salvata, eventualmente
# cambiando il nome, il salvataggio "perfetto" viene fatto automaticamente),
# o come PNG (occupa un po' di memoria in più, ma non ha i problemi precedenti).
#
# Per visualizzare le coordinate di punti su un grafico do' il comando locator
# con indicato il numero dei punti e faccio dei clic su di essi, e ottengo
# approssimazioni delle loro ascisse e delle loro ordinate (i segmenti della
# crocetta sono ampi 2 pixel; conviene sporgere di un pixel a destra e di uno
# in basso piuttosto che di uno a sinistra ed uno in alto). Vedi QUI per l'uso
# di locator per tracciare punti, segmenti, poligonali.
f <- function(x) x*2-1; g <- function(x) x^2-1
x1 <- -5; x2 <- 5; y1 <- -5; y2 <- 8
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
abline(h=0,col="brown"); abline(v=0,col="brown")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
curve(f, add=TRUE,col="red"); curve(g, add=TRUE,col="blue")
locator(1)
$x
[1] 2.008631
$y
[1] 2.968015
 # (con locator(1)$x ho la visulizzazione solo del valore della ascissa, con
# locator(1)$y solo quello dell'ordinata)
# Ripetendo locator(1) posso via via fare dei clic e vedere, a seconda di
# cosa ho tracciato, le coordinate di punti che stanno sopra, sotto, dentro,
# ... a particolari curve
#
# Se voglio (ad es. per conservare la vista di grafici precedenti), posso
# aprire una o più nuove finestre grafiche usando il comando dev.new()
# [in Windows si può usare anche windows()]
dev.new()
# nel comando posso specificare le dimensioni della finestra in pollici;
# la cosa può servire se voglio ottenere più immagini delle stesse
# dimensioni; sotto ecco che cosa ottengo con i seguenti comandi:
# dev.new(width=2.5,height=2.5); plot(c(0,1),c(0,1),xlab="", ylab="")
# dev.new(width=2.5,height=4); plot(c(0,1),c(0,1),xlab="", ylab="")
# dev.new(width=4,height=4); plot(c(0,1),c(0,1),xlab="", ylab="")
# Posso dare un titolo alla finestra con dev.new( ... title="...")
# Nota. Una finestra grafica può sempre essere spostata e ridimensionata)
# Col comando dev.off() puoi chiudere l'ultima finestra grafica aperta
# (device: dispositivo); con graphics.off() le chiudi tutte.
# [ dev.list() elenca le finestre aperte]
# (con locator(1)$x ho la visulizzazione solo del valore della ascissa, con
# locator(1)$y solo quello dell'ordinata)
# Ripetendo locator(1) posso via via fare dei clic e vedere, a seconda di
# cosa ho tracciato, le coordinate di punti che stanno sopra, sotto, dentro,
# ... a particolari curve
#
# Se voglio (ad es. per conservare la vista di grafici precedenti), posso
# aprire una o più nuove finestre grafiche usando il comando dev.new()
# [in Windows si può usare anche windows()]
dev.new()
# nel comando posso specificare le dimensioni della finestra in pollici;
# la cosa può servire se voglio ottenere più immagini delle stesse
# dimensioni; sotto ecco che cosa ottengo con i seguenti comandi:
# dev.new(width=2.5,height=2.5); plot(c(0,1),c(0,1),xlab="", ylab="")
# dev.new(width=2.5,height=4); plot(c(0,1),c(0,1),xlab="", ylab="")
# dev.new(width=4,height=4); plot(c(0,1),c(0,1),xlab="", ylab="")
# Posso dare un titolo alla finestra con dev.new( ... title="...")
# Nota. Una finestra grafica può sempre essere spostata e ridimensionata)
# Col comando dev.off() puoi chiudere l'ultima finestra grafica aperta
# (device: dispositivo); con graphics.off() le chiudi tutte.
# [ dev.list() elenca le finestre aperte]


 #
# Un modo molto comodo per salvare immagini o gestire contemporaneamente
# immagini su più finestre è ricorrere ai comandi recordPlot e replayPlot,
# che consentono di salvare un'immagine, su cui poi si può lavorare anche
# in un secondo momento. Un esempio:
f <- function(x) x^2-1; plot(f,-2,2); abline(h=0,v=0,col="blue")
fig01 <- recordPlot()
# ho fatto un grafico (A) e l'ho salvato
plot(f,-3,1); abline(h=0,v=0,col="blue")
# ho ottenuto un nuovo grafico (B) ; ora richiamo il precedente e vi
# aggiungo un punto (C) e un altro grafico:
replayPlot(fig01)
points(1/2,1)
g <- function(x) -x; curve(g, add=TRUE)
#
# Un modo molto comodo per salvare immagini o gestire contemporaneamente
# immagini su più finestre è ricorrere ai comandi recordPlot e replayPlot,
# che consentono di salvare un'immagine, su cui poi si può lavorare anche
# in un secondo momento. Un esempio:
f <- function(x) x^2-1; plot(f,-2,2); abline(h=0,v=0,col="blue")
fig01 <- recordPlot()
# ho fatto un grafico (A) e l'ho salvato
plot(f,-3,1); abline(h=0,v=0,col="blue")
# ho ottenuto un nuovo grafico (B) ; ora richiamo il precedente e vi
# aggiungo un punto (C) e un altro grafico:
replayPlot(fig01)
points(1/2,1)
g <- function(x) -x; curve(g, add=TRUE)
 #
# Se voglio visualizzare più finestre e modificarne ora l'una ora l'altra
# posso procedere ad es. così:
dev.new(xpos=600,ypos=10) # posiziono una finestra 600 pixel a destra, 10 in basso
plot(f,-2,2); abline(h=0,v=0,col="blue")
fig01 <- recordPlot() # ho memorizzato l'immagine come fig01
dev.new(xpos=300,ypos=10) # posiziono una nuova finestra più a sinistra
plot(f,-3,1); abline(h=0,v=0,col="blue")
fig02 <- recordPlot() # ho memorizzato l'immagine come fig02
dev.new(xpos=600,ypos=10) # posiziono una fin. come la prima, che se voglio cancello
replayPlot(fig01) # ho richiamato fig01
points(1/2,1); g <- function(x) -x; curve(g, add=TRUE) # ho aggiunto un punto e un grafico
#
# Ecco come posizionare le finestre grafiche (width, height sono le dimensioni usando
# circa 2 cm come unità, xpos, ypos è la posizione in pixel del vertice in alto a
# sinistra)
posiz <- 200
dev.new(width=2, height=2, xpos=1,ypos=1)
par( mai = c(0,0,0,0) )
plot(c(0,10),c(0,10),type="n",xlab="", ylab="",las=1)
axis(1,pos=0); axis(2,pos=0)
f <- function(x) (x-5)^2; plot(f,0,10,add=TRUE)
dev.new(width=2, height=2, xpos=posiz,ypos=1)
par( mai = c(0,0,0,0) )
plot(c(0,10),c(0,10),type="n",xlab="", ylab="",las=1)
g <- function(x) -(x-5)^2+10; plot(g,0,10,add=TRUE)
axis(1,pos=0); axis(2,pos=0)
#
# Se voglio visualizzare più finestre e modificarne ora l'una ora l'altra
# posso procedere ad es. così:
dev.new(xpos=600,ypos=10) # posiziono una finestra 600 pixel a destra, 10 in basso
plot(f,-2,2); abline(h=0,v=0,col="blue")
fig01 <- recordPlot() # ho memorizzato l'immagine come fig01
dev.new(xpos=300,ypos=10) # posiziono una nuova finestra più a sinistra
plot(f,-3,1); abline(h=0,v=0,col="blue")
fig02 <- recordPlot() # ho memorizzato l'immagine come fig02
dev.new(xpos=600,ypos=10) # posiziono una fin. come la prima, che se voglio cancello
replayPlot(fig01) # ho richiamato fig01
points(1/2,1); g <- function(x) -x; curve(g, add=TRUE) # ho aggiunto un punto e un grafico
#
# Ecco come posizionare le finestre grafiche (width, height sono le dimensioni usando
# circa 2 cm come unità, xpos, ypos è la posizione in pixel del vertice in alto a
# sinistra)
posiz <- 200
dev.new(width=2, height=2, xpos=1,ypos=1)
par( mai = c(0,0,0,0) )
plot(c(0,10),c(0,10),type="n",xlab="", ylab="",las=1)
axis(1,pos=0); axis(2,pos=0)
f <- function(x) (x-5)^2; plot(f,0,10,add=TRUE)
dev.new(width=2, height=2, xpos=posiz,ypos=1)
par( mai = c(0,0,0,0) )
plot(c(0,10),c(0,10),type="n",xlab="", ylab="",las=1)
g <- function(x) -(x-5)^2+10; plot(g,0,10,add=TRUE)
axis(1,pos=0); axis(2,pos=0)
 #
# Il tracciamento di punti, segmenti, poligoni
x1 <- -5; x2 <- 5; y1 <- -5; y2 <- 5
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="", asp=1)
abline(h=0,v=0,col="brown")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
points(0,0); points(1,1); points(2,2); lines(c(0,2),c(0,2),col="red")
# (il segmento da (0,0) a (2,2), realizzabile anche nel modo seguente)
# Alternativa: segments(0,0,2,2,col="red"); aggiungendo lwd=… cambio lo spessore
polygon(c(1,-1,-1,1),c(1,1,-1,-1));polygon(c(2,-2,-2,2),c(3,3,-3,-3),border="blue")
polygon(c(2,5,2,5),c(-2,-2,0,0),col="green"); points(3,3, pch=20)
# [Se metto il punto finale il polig. posso tracciarlo anche con lines, ma con col
# metto il colore nel bordo: lines(c(2,5,2,5,2),c(-2,-2,0,0,-2),col="brown") ]
# Con pch=20 si è cambiato aspetto al punto tracciato
symbols(-2, 2, circles=1.5, inches=FALSE, add=TRUE, fg="red")
# il cerchio è tracciato come simbolo (metti le coord. del centro e in "circles"
# il raggio - devi mettere inches=FALSE se no usa i pollici; se vuoi colorare
# l'interno del cerchio, ad es. giallo, aggiungi bg="yellow" - BackGround; il
# cerchio è tracciato correttamente solo se sei in scala monometrica (asp=1);
# in modo simile, con squares=1.5 al posto di circles=1.5, ottengo un quadrato
# con lati lunghi 1.5 paralleli agli assi; per altri quadrati si usa polygon).
points(3,1, bg="green", pch=21)
# Ho tracciato un punto verde; il contorno è nero (con col ne cambierei il colore)
#
# Il tracciamento di punti, segmenti, poligoni
x1 <- -5; x2 <- 5; y1 <- -5; y2 <- 5
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="", asp=1)
abline(h=0,v=0,col="brown")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
points(0,0); points(1,1); points(2,2); lines(c(0,2),c(0,2),col="red")
# (il segmento da (0,0) a (2,2), realizzabile anche nel modo seguente)
# Alternativa: segments(0,0,2,2,col="red"); aggiungendo lwd=… cambio lo spessore
polygon(c(1,-1,-1,1),c(1,1,-1,-1));polygon(c(2,-2,-2,2),c(3,3,-3,-3),border="blue")
polygon(c(2,5,2,5),c(-2,-2,0,0),col="green"); points(3,3, pch=20)
# [Se metto il punto finale il polig. posso tracciarlo anche con lines, ma con col
# metto il colore nel bordo: lines(c(2,5,2,5,2),c(-2,-2,0,0,-2),col="brown") ]
# Con pch=20 si è cambiato aspetto al punto tracciato
symbols(-2, 2, circles=1.5, inches=FALSE, add=TRUE, fg="red")
# il cerchio è tracciato come simbolo (metti le coord. del centro e in "circles"
# il raggio - devi mettere inches=FALSE se no usa i pollici; se vuoi colorare
# l'interno del cerchio, ad es. giallo, aggiungi bg="yellow" - BackGround; il
# cerchio è tracciato correttamente solo se sei in scala monometrica (asp=1);
# in modo simile, con squares=1.5 al posto di circles=1.5, ottengo un quadrato
# con lati lunghi 1.5 paralleli agli assi; per altri quadrati si usa polygon).
points(3,1, bg="green", pch=21)
# Ho tracciato un punto verde; il contorno è nero (con col ne cambierei il colore)

 # Le due scritte "x" e "Prova" sono state aggiunte col comando "text" (la
# scritta viene centrata nel punto indicato):
text(-2,-4,"x"); text(4,2,"Prova")
# Le altre 2 scritte in un font monospazio, di dimensioni 0.5 o 1.5 volte
# Quelle standard, allineate a sinistra o a destra, si sono ottenute con:
text(4,3,"pROVA",family="mono",adj=0,cex=0.5)
text(4,4,"pRoVa",family="mono",adj=1,cex=1.5)
# Quelle non orizzontali aggiungendo l'opzione srt (string rotation):
text(-4,-2,"pRoVa",srt=90); text(-4,4,"pRoVa",srt=-45)
# Quella sue due righe aggiungendo un a capo (nuova riga) con \n
text(4,-3,"ecco una\nprova")
# Sopra a destra un altro esempio. Volendo, con l'opzione font=2 (3,4,5)
# si possono ottenere scritte bold (italic, bold-italic, in Symbol) e con
# col (es. aggiungendo col="red") le si possono ottenere colorate.
#
# Per cancellare una scritta posso tracciarvi sopra un rettangolo con bordo
# e contenuto dello stesso colore dello sfondo. Ecco come posso tracciare il
# rettangolo da (-5,-4) a (-3,-1/2) che cancella la parola nel 3º quadrante.
rect(-5,-4,-3,-1/2,col="white",border="white")
#
# Ecco una figura non matematica, costruita usando le coordinate (vedi):
# Le due scritte "x" e "Prova" sono state aggiunte col comando "text" (la
# scritta viene centrata nel punto indicato):
text(-2,-4,"x"); text(4,2,"Prova")
# Le altre 2 scritte in un font monospazio, di dimensioni 0.5 o 1.5 volte
# Quelle standard, allineate a sinistra o a destra, si sono ottenute con:
text(4,3,"pROVA",family="mono",adj=0,cex=0.5)
text(4,4,"pRoVa",family="mono",adj=1,cex=1.5)
# Quelle non orizzontali aggiungendo l'opzione srt (string rotation):
text(-4,-2,"pRoVa",srt=90); text(-4,4,"pRoVa",srt=-45)
# Quella sue due righe aggiungendo un a capo (nuova riga) con \n
text(4,-3,"ecco una\nprova")
# Sopra a destra un altro esempio. Volendo, con l'opzione font=2 (3,4,5)
# si possono ottenere scritte bold (italic, bold-italic, in Symbol) e con
# col (es. aggiungendo col="red") le si possono ottenere colorate.
#
# Per cancellare una scritta posso tracciarvi sopra un rettangolo con bordo
# e contenuto dello stesso colore dello sfondo. Ecco come posso tracciare il
# rettangolo da (-5,-4) a (-3,-1/2) che cancella la parola nel 3º quadrante.
rect(-5,-4,-3,-1/2,col="white",border="white")
#
# Ecco una figura non matematica, costruita usando le coordinate (vedi):
 # un altro esempio: tracciamento degli assi di più coppie di punti
coor <- c(-10,10,-10,10); orig <- c(0,0)
xx <- c(-10,-8,-6,-4,-2,0,2,4,6,8,10); yy <- xx
plot(c(coor[1],coor[2]),c(coor[3],coor[4]),type="n",xlab="",ylab="",asp=1)
abline(h = xx,col="grey"); abline(v = yy, col="grey")
retta <- function(x) (A[2]+B[2])/2+(x-(A[1]+B[1])/2)*-(B[1]-A[1])/(B[2]-A[2])
A <- c(2,2); B <- c(-2,-2)
points(A[1],A[2]); points(B[1],B[2])
curve(retta,add=TRUE)
A <- c(2,3); B <- c(-2,4)
points(A[1],A[2],col="red"); points(B[1],B[2],col="red")
curve(retta,add=TRUE)
A <- c(2,-5); B <- c(3,-6)
points(A[1],A[2],col="blue"); points(B[1],B[2],col="blue")
curve(retta,add=TRUE)
# un altro esempio: tracciamento degli assi di più coppie di punti
coor <- c(-10,10,-10,10); orig <- c(0,0)
xx <- c(-10,-8,-6,-4,-2,0,2,4,6,8,10); yy <- xx
plot(c(coor[1],coor[2]),c(coor[3],coor[4]),type="n",xlab="",ylab="",asp=1)
abline(h = xx,col="grey"); abline(v = yy, col="grey")
retta <- function(x) (A[2]+B[2])/2+(x-(A[1]+B[1])/2)*-(B[1]-A[1])/(B[2]-A[2])
A <- c(2,2); B <- c(-2,-2)
points(A[1],A[2]); points(B[1],B[2])
curve(retta,add=TRUE)
A <- c(2,3); B <- c(-2,4)
points(A[1],A[2],col="red"); points(B[1],B[2],col="red")
curve(retta,add=TRUE)
A <- c(2,-5); B <- c(3,-6)
points(A[1],A[2],col="blue"); points(B[1],B[2],col="blue")
curve(retta,add=TRUE)
 #
# un altro esempio: il disegno di un pesciolino ...
# (si veda che c(...) può essere usato per applicare un comando ad
# una sequenza di input)
x1 <- -30; x2 <- 30; y1 <- -30; y2 <- 30
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="", asp=1)
for(i in (-3:3)*10) abline(h=i,col="grey")
for(i in (-3:3)*10) abline(v=i,col="grey")
abline(h=0,col="brown"); abline(v=0,col="brown")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
x_1 <- c(13,11,10, 9, 7,7.5, 7, 9,10,11,13,17,20,20.5,18.5,21,20,17,13)
y_1 <- c(17,16,15,13,10, 13,16,13,11,10, 9, 9,11, 12, 13,13,15,17,17)
c_1 <- "black"
x_2 <- c(13,12,15,14,17,13)
y_2 <- c(17,20,17,20,17,17)
c_2 <- "green"
x_3 <- c(17,14,15,12,13,17)
y_3 <- c( 9, 6, 9, 6, 9, 9)
c_3 <- "magenta"
lines(x_1,y_1,col=c_1); lines(x_2,y_2,col=c_2); lines(x_3,y_3,col=c_3)
# ... e di una sua trasformazione geometrica, quella che a
# (x,y) associa (-x-y+8, -y):
xx_1 <- x_1; xx_2 <- x_2; xx_3 <- x_3
yy_1 <- y_1; yy_2 <- y_2; yy_3 <- y_3;
x_1 <- -xx_1-yy_1+8; x_2 <- -xx_2-yy_2+8; x_3 <- -xx_3-yy_3+8
y_1 <- -yy_1; y_2 <- -yy_2; y_3 <- -yy_3
lines(x_1,y_1,col=c_1); lines(x_2,y_2,col=c_2); lines(x_3,y_3,col=c_3)
# e quella che associa (-x-y+10, -y-x/2):
x_1 <- -xx_1+yy_1+10; x_2 <- -xx_2+yy_2+10; x_3 <- -xx_3+yy_3+10
y_1 <- -yy_1-xx_1/2; y_2 <- -yy_2-xx_2/2; y_3 <- -yy_3-xx_3/2
lines(x_1,y_1,col=c_1); lines(x_2,y_2,col=c_2); lines(x_3,y_3,col=c_3)
#
# un altro esempio: il disegno di un pesciolino ...
# (si veda che c(...) può essere usato per applicare un comando ad
# una sequenza di input)
x1 <- -30; x2 <- 30; y1 <- -30; y2 <- 30
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="", asp=1)
for(i in (-3:3)*10) abline(h=i,col="grey")
for(i in (-3:3)*10) abline(v=i,col="grey")
abline(h=0,col="brown"); abline(v=0,col="brown")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
x_1 <- c(13,11,10, 9, 7,7.5, 7, 9,10,11,13,17,20,20.5,18.5,21,20,17,13)
y_1 <- c(17,16,15,13,10, 13,16,13,11,10, 9, 9,11, 12, 13,13,15,17,17)
c_1 <- "black"
x_2 <- c(13,12,15,14,17,13)
y_2 <- c(17,20,17,20,17,17)
c_2 <- "green"
x_3 <- c(17,14,15,12,13,17)
y_3 <- c( 9, 6, 9, 6, 9, 9)
c_3 <- "magenta"
lines(x_1,y_1,col=c_1); lines(x_2,y_2,col=c_2); lines(x_3,y_3,col=c_3)
# ... e di una sua trasformazione geometrica, quella che a
# (x,y) associa (-x-y+8, -y):
xx_1 <- x_1; xx_2 <- x_2; xx_3 <- x_3
yy_1 <- y_1; yy_2 <- y_2; yy_3 <- y_3;
x_1 <- -xx_1-yy_1+8; x_2 <- -xx_2-yy_2+8; x_3 <- -xx_3-yy_3+8
y_1 <- -yy_1; y_2 <- -yy_2; y_3 <- -yy_3
lines(x_1,y_1,col=c_1); lines(x_2,y_2,col=c_2); lines(x_3,y_3,col=c_3)
# e quella che associa (-x-y+10, -y-x/2):
x_1 <- -xx_1+yy_1+10; x_2 <- -xx_2+yy_2+10; x_3 <- -xx_3+yy_3+10
y_1 <- -yy_1-xx_1/2; y_2 <- -yy_2-xx_2/2; y_3 <- -yy_3-xx_3/2
lines(x_1,y_1,col=c_1); lines(x_2,y_2,col=c_2); lines(x_3,y_3,col=c_3)

 # Un altro movimento, guidato col MOUSE; riporto il pesce con la "coda" nella
# origine e poi, quando il programma si ferma, faccio un clic su un punto del
# riquadro grafico (in tutto dovrò fare 3 clic):
x1 <- -30; x2 <- 30; y1 <- -30; y2 <- 30
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="", asp=1)
abline(h=seq(y1,y2,5),v=seq(x1,x2,5),lty=3,col="orange")
abline(h=0,v=0,col="brown")
x <- c(13,11,10, 9, 7,7.5, 7, 9,10,11,13,17,20,20.5,18.5,21,20,17,13)
y <- c(17,16,15,13,10, 13,16,13,11,10, 9, 9,11, 12, 13,13,15,17,17)
x <- x-7; y <- y-10; lines(x,y)
p <- locator(1); p$x; p$y; lines(x + p$x, y + p$y, col="red")
[1] -14.8407
[1] 20.15971
p <- locator(1); p$x; p$y; lines(x + p$x, y + p$y, col="blue")
[1] 15.0377
[1] 10.30969
p <- locator(1); p$x; p$y; lines(x + p$x, y + p$y, col="green")
[1] -25.01905
[1] -19.89704
# Un altro movimento, guidato col MOUSE; riporto il pesce con la "coda" nella
# origine e poi, quando il programma si ferma, faccio un clic su un punto del
# riquadro grafico (in tutto dovrò fare 3 clic):
x1 <- -30; x2 <- 30; y1 <- -30; y2 <- 30
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="", asp=1)
abline(h=seq(y1,y2,5),v=seq(x1,x2,5),lty=3,col="orange")
abline(h=0,v=0,col="brown")
x <- c(13,11,10, 9, 7,7.5, 7, 9,10,11,13,17,20,20.5,18.5,21,20,17,13)
y <- c(17,16,15,13,10, 13,16,13,11,10, 9, 9,11, 12, 13,13,15,17,17)
x <- x-7; y <- y-10; lines(x,y)
p <- locator(1); p$x; p$y; lines(x + p$x, y + p$y, col="red")
[1] -14.8407
[1] 20.15971
p <- locator(1); p$x; p$y; lines(x + p$x, y + p$y, col="blue")
[1] 15.0377
[1] 10.30969
p <- locator(1); p$x; p$y; lines(x + p$x, y + p$y, col="green")
[1] -25.01905
[1] -19.89704

 # Qui vedi come ottenere pi� spostamenti.
# Qui vedi come ottenere col mouse spostamenti della curva
# soprastante e, contemporaneamente, i cambiamenti della sua equazione.
#
# è facile ottenere fasci di curve e in generale grafici dinamici; un
# esempio: definisco f dipendente da un parametro a a cui assegno un
# valore iniziale; definita la scala e scelto come modificare a
# (qui scelgo di aumentarlo di 1 ogni volta), scrivo il comando:
# curve(f, add=TRUE,col="blue"); a <- a+1 e lo richiamo via via
# premendo il tasto FrecciaSu e il tasto Invio:
f <- function(x) a*x^2+2*x-2
x1 <- -5; x2 <- 5; y1 <- -10; y2 <- 10
a <- -2
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
curve(f, add=TRUE,col="blue"); a <- a+1
curve(f, add=TRUE,col="blue"); a <- a+1
curve(f, add=TRUE,col="blue"); a <- a+1
curve(f, add=TRUE,col="blue"); a <- a+1
curve(f, add=TRUE,col="blue"); a <- a+1
curve(f, add=TRUE,col="blue"); a <- a+1
# Qui vedi come ottenere pi� spostamenti.
# Qui vedi come ottenere col mouse spostamenti della curva
# soprastante e, contemporaneamente, i cambiamenti della sua equazione.
#
# è facile ottenere fasci di curve e in generale grafici dinamici; un
# esempio: definisco f dipendente da un parametro a a cui assegno un
# valore iniziale; definita la scala e scelto come modificare a
# (qui scelgo di aumentarlo di 1 ogni volta), scrivo il comando:
# curve(f, add=TRUE,col="blue"); a <- a+1 e lo richiamo via via
# premendo il tasto FrecciaSu e il tasto Invio:
f <- function(x) a*x^2+2*x-2
x1 <- -5; x2 <- 5; y1 <- -10; y2 <- 10
a <- -2
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
curve(f, add=TRUE,col="blue"); a <- a+1
curve(f, add=TRUE,col="blue"); a <- a+1
curve(f, add=TRUE,col="blue"); a <- a+1
curve(f, add=TRUE,col="blue"); a <- a+1
curve(f, add=TRUE,col="blue"); a <- a+1
curve(f, add=TRUE,col="blue"); a <- a+1
 # Posso anche cambiare automaticamente il colore
a <- -2; c <- 1
curve(f, add=TRUE,col=c); a <- a+1; c <- c+1
curve(f, add=TRUE,col=c); a <- a+1; c <- c+1
# ...
# Posso anche cambiare automaticamente il colore
a <- -2; c <- 1
curve(f, add=TRUE,col=c); a <- a+1; c <- c+1
curve(f, add=TRUE,col=c); a <- a+1; c <- c+1
# ...
 # ecco gli 8 colori richiamabili con "col=numero"
x1 <- 0; x2 <- 21; y1 <- -1; y2 <- 1
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
for (c in 1:20) points(c,0,col=c)
# ecco gli 8 colori richiamabili con "col=numero"
x1 <- 0; x2 <- 21; y1 <- -1; y2 <- 1
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
for (c in 1:20) points(c,0,col=c)
 # volendo i pallini "pieni"
for (c in 1:20) points(c,0,col=c,pch=19)
# volendo i pallini "pieni"
for (c in 1:20) points(c,0,col=c,pch=19)
 # volendo posso generare direttamente un fascio di curve:
x1 <- -5; x2 <- 5; y1 <- -10; y2 <- 10
f <- function(x) a*x^2+2*x-2
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
for (i in 1:10) {a <- -3+i; curve(f, add=TRUE,col=i)}
#
# vediamo la soluzione di una equazione (x^2-x=3.2) interpretabile come la
# ascissa in cui il grafico di una funzione scavalca una retta: l'individuazione
# grafica e la ricerca numerica (ci limitiamo alla soluzione maggiore)
f <- function(x) x^2-x; k <- 3.2
x1 <- -5; x2 <- 5; y1 <- -5; y2 <- 8
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
abline(h=0,col="brown"); abline(v=0,col="brown")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
curve(f, add=TRUE,col="blue")
abline(h=k,col="red")
# volendo posso generare direttamente un fascio di curve:
x1 <- -5; x2 <- 5; y1 <- -10; y2 <- 10
f <- function(x) a*x^2+2*x-2
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
for (i in 1:10) {a <- -3+i; curve(f, add=TRUE,col=i)}
#
# vediamo la soluzione di una equazione (x^2-x=3.2) interpretabile come la
# ascissa in cui il grafico di una funzione scavalca una retta: l'individuazione
# grafica e la ricerca numerica (ci limitiamo alla soluzione maggiore)
f <- function(x) x^2-x; k <- 3.2
x1 <- -5; x2 <- 5; y1 <- -5; y2 <- 8
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="")
abline(h=0,col="brown"); abline(v=0,col="brown")
axis(1,pos=0,label=FALSE,col="brown"); axis(2,pos=0,label=FALSE,col="brown")
curve(f, add=TRUE,col="blue")
abline(h=k,col="red")
 # si vede che la soluzione è 2 e qualcosa; la ricerca numerica si esegue
# col comando uniroot (root sta per "radice") speficando un intervallo
# in cui il grafico scavalca la retta y=k e la precisione (o tolleranza)
# con cui si cerca la soluzione:
g <- function (x) f(x)-k; uniroot(g, c(1, 3), tol = 0.00001)
$root
[1] 2.357418
$f.root
[1] -1.572662e-08
$iter
[1] 6
$estim.prec
[1] 5e-06
# [ vedi qui per una soluzione usando il metodo di bisezione ]
# Oltre alla soluzione (2.357418) vengono precisati il valore di g
# in essa, le iterazioni che il particolare algoritmo usato dal programma
# ha impiegato per trovarla e la precisione del risultato trovato.
# Volendo possiamo estrarre solo il valore della soluzione aggiungendo
# $root:
soluz <- uniroot(g, c(1, 3),tol=10^-9)$root; soluz
[1] 2.357418
# In questo caso particolare x^2-x-3.2=0 (eq. di 2^ grado) saprei trovare la
# soluzione direttamente:
1/2+sqrt(1+4*3.2)/2
[1] 2.357418
# Un modo veloce per risolvere le equazioni a*x^2 + b*x + c = 0:
s <- function(a,b,c) noquote(c(paste("(",-b,"+sqrt(",b^2-4*a*c,"))/",2*a),";",paste("(",-b,"-sqrt(",b^2-4*a*c,"))/",2*a)))
# Per l'eq. precedente batterei s(1,-1,-3.2). Risolvo 3*x^2 - 5*x + 2 = 0:
s(3, -5, 2)
[1] ( 5 +sqrt( 1 ))/ 6 ; ( 5 -sqrt( 1 ))/ 6
# Copiando questa riga ottengo il valore delle soluzioni:
( 5 +sqrt( 1 ))/ 6 ; ( 5 -sqrt( 1 ))/ 6
[1] 1
[1] 0.6666667
# Volendo ottenere la 2ª soluzione in forma frazionaria:
library(MASS); fractions( ( 5 -sqrt( 1 ))/ 6 )
[1] 2/3
#
# Come valutare il punto in cui una funzione assume un valore di
# minimo o di massimo relativo, ossia il vertice di una gobba del
# suo grafico. Vediamo prima il caso di un punto di minimo.
# Vedremo più avanti come farlo con un apposito comando.
# si vede che la soluzione è 2 e qualcosa; la ricerca numerica si esegue
# col comando uniroot (root sta per "radice") speficando un intervallo
# in cui il grafico scavalca la retta y=k e la precisione (o tolleranza)
# con cui si cerca la soluzione:
g <- function (x) f(x)-k; uniroot(g, c(1, 3), tol = 0.00001)
$root
[1] 2.357418
$f.root
[1] -1.572662e-08
$iter
[1] 6
$estim.prec
[1] 5e-06
# [ vedi qui per una soluzione usando il metodo di bisezione ]
# Oltre alla soluzione (2.357418) vengono precisati il valore di g
# in essa, le iterazioni che il particolare algoritmo usato dal programma
# ha impiegato per trovarla e la precisione del risultato trovato.
# Volendo possiamo estrarre solo il valore della soluzione aggiungendo
# $root:
soluz <- uniroot(g, c(1, 3),tol=10^-9)$root; soluz
[1] 2.357418
# In questo caso particolare x^2-x-3.2=0 (eq. di 2^ grado) saprei trovare la
# soluzione direttamente:
1/2+sqrt(1+4*3.2)/2
[1] 2.357418
# Un modo veloce per risolvere le equazioni a*x^2 + b*x + c = 0:
s <- function(a,b,c) noquote(c(paste("(",-b,"+sqrt(",b^2-4*a*c,"))/",2*a),";",paste("(",-b,"-sqrt(",b^2-4*a*c,"))/",2*a)))
# Per l'eq. precedente batterei s(1,-1,-3.2). Risolvo 3*x^2 - 5*x + 2 = 0:
s(3, -5, 2)
[1] ( 5 +sqrt( 1 ))/ 6 ; ( 5 -sqrt( 1 ))/ 6
# Copiando questa riga ottengo il valore delle soluzioni:
( 5 +sqrt( 1 ))/ 6 ; ( 5 -sqrt( 1 ))/ 6
[1] 1
[1] 0.6666667
# Volendo ottenere la 2ª soluzione in forma frazionaria:
library(MASS); fractions( ( 5 -sqrt( 1 ))/ 6 )
[1] 2/3
#
# Come valutare il punto in cui una funzione assume un valore di
# minimo o di massimo relativo, ossia il vertice di una gobba del
# suo grafico. Vediamo prima il caso di un punto di minimo.
# Vedremo più avanti come farlo con un apposito comando.

 # MIN:
# valuto fun in 2 punti interni, e prendo quello in cui il val. è massimo
# come nuovo estremo:
# h<-(b-a)/3; y1<-f(a);y2<-f(a+h); y3 <-f(a+2*h)
# if(y3<y2 & y2<y1) a<-a+h else b<-b-h; c(a,b)
# Per il MAX il procedimento è simile:
# if(y1<y2 & y2<y3) a<-a+h else b<-b-h; c(a,b)
# Prendiamo come esempio la ricerca del minimo della seguente funzione:
f <- function(x) x^2-x; a <- -5; b <- 5
# Graficamente riesco ad individuare dove sta il punto di minimo
# MIN:
# valuto fun in 2 punti interni, e prendo quello in cui il val. è massimo
# come nuovo estremo:
# h<-(b-a)/3; y1<-f(a);y2<-f(a+h); y3 <-f(a+2*h)
# if(y3<y2 & y2<y1) a<-a+h else b<-b-h; c(a,b)
# Per il MAX il procedimento è simile:
# if(y1<y2 & y2<y3) a<-a+h else b<-b-h; c(a,b)
# Prendiamo come esempio la ricerca del minimo della seguente funzione:
f <- function(x) x^2-x; a <- -5; b <- 5
# Graficamente riesco ad individuare dove sta il punto di minimo

 # Con procedimento numerico ne trovo il valore, interando il procedimento:
f <- function(x) x^2-x; a <- -5; b <- 5
for(i in 1:20) { h <- (b-a)/3;y1 <- f(a);y2 <- f(a+h); y3 <- f(a+2*h)
if(y1 > y2 & y2 > y3) a <- a+h else b <- b-h }; c(a,b)
[1] 0.4988708 0.5018781
# { e } consentono di raggruppare più comandi;
# con altre iterazioni:
for(i in 1:20) { h <- (b-a)/3;y1 <- f(a);y2 <- f(a+h); y3 <- f(a+2*h)
if(y1 > y2 & y2 > y3) a <- a+h else b <- b-h }; c(a,b)
[1] 0.4999995 0.5000004
for(i in 1:20) { h <- (b-a)/3;y1 <- f(a);y2 <- f(a+h); y3 <- f(a+2*h)
if(y1 > y2 & y2 > y3) a <- a+h else b <- b-h }; c(a,b)
[1] -5 -5
# Vediamo come trovare il punto di max relativo della seguente funzione:
f <- function(x) -x^3+5*x^2-2*x; plot(f,-2,5)
# Con procedimento numerico ne trovo il valore, interando il procedimento:
f <- function(x) x^2-x; a <- -5; b <- 5
for(i in 1:20) { h <- (b-a)/3;y1 <- f(a);y2 <- f(a+h); y3 <- f(a+2*h)
if(y1 > y2 & y2 > y3) a <- a+h else b <- b-h }; c(a,b)
[1] 0.4988708 0.5018781
# { e } consentono di raggruppare più comandi;
# con altre iterazioni:
for(i in 1:20) { h <- (b-a)/3;y1 <- f(a);y2 <- f(a+h); y3 <- f(a+2*h)
if(y1 > y2 & y2 > y3) a <- a+h else b <- b-h }; c(a,b)
[1] 0.4999995 0.5000004
for(i in 1:20) { h <- (b-a)/3;y1 <- f(a);y2 <- f(a+h); y3 <- f(a+2*h)
if(y1 > y2 & y2 > y3) a <- a+h else b <- b-h }; c(a,b)
[1] -5 -5
# Vediamo come trovare il punto di max relativo della seguente funzione:
f <- function(x) -x^3+5*x^2-2*x; plot(f,-2,5)
 a <- 2; b <-4
for(i in 1:20) {h <- (b-a)/3;y1 <- f(a); y2 <- f(a+h); y3 <- f(a+2*h)
if(y1 < y2 & y2 < y3) a <- a+h else b <- b-h}; c(a,b)
[1] 3.119380 3.119981
for(i in 1:20) {h <- (b-a)/3;y1 <- f(a); y2 <- f(a+h); y3 <- f(a+2*h)
if(y1 < y2 & y2 < y3) a <- a+h else b <- b-h}; c(a,b)
[1] 3.119633 3.119633
#
# Tutto ciò si può fare anche, velocemente, col comando optimize,
# in modo simile a come si procede col comando uniroot.
f <- function(x) -x^3+5*x^2-2*x; plot(f,-2,5)
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
a <- 2; b <-4
for(i in 1:20) {h <- (b-a)/3;y1 <- f(a); y2 <- f(a+h); y3 <- f(a+2*h)
if(y1 < y2 & y2 < y3) a <- a+h else b <- b-h}; c(a,b)
[1] 3.119380 3.119981
for(i in 1:20) {h <- (b-a)/3;y1 <- f(a); y2 <- f(a+h); y3 <- f(a+2*h)
if(y1 < y2 & y2 < y3) a <- a+h else b <- b-h}; c(a,b)
[1] 3.119633 3.119633
#
# Tutto ciò si può fare anche, velocemente, col comando optimize,
# in modo simile a come si procede col comando uniroot.
f <- function(x) -x^3+5*x^2-2*x; plot(f,-2,5)
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
 optimize(f,c(2,4),maximum = TRUE,tol=1e-12)
$maximum
[1] 3.119633
$objective
[1] 12.06067
print(optimize(f,c(2,4),maximum = TRUE,tol=1e-13),12)
$maximum
[1] 3.11963298088
$objective
[1] 12.0606725872
print(optimize(f,c(-1,1),maximum = FALSE,tol=1e-13),12)
$minimum
[1] 0.213700352165
$objective
[1] -0.208820735354
#
# Il mass. com. divisore di due numeri naturali (con l'algoritmo
# euclideo) e il min. com. multiplo
mcd <- function(m,n) {a <- m; r <- n; while(r > 0)
{b <- r; q <- floor(a/b); r <- a-b*q; a <- b}; a}
mcm <- function(m,n) m*n/mcd(m,n)
mcd(3276,396); mcm(3276,396)
[1] 36
[1] 36036
# Possiamo facilmente estendere queste funzioni a più input:
MCD <- function(x) {m <- x[1]; for(i in 2:length(x)) m <- mcd(m,x[i]); m}
MCM <- function(x) {m <- x[1]; for(i in 2:length(x)) m <- mcm(m,x[i]); m}
MCD(c(2,3,10)); MCM(c(2,3,10))
[1] 1
[1] 30
#
# Un modo per confrontare se termini contenenti più di una variabile
# sono uguali (se ne hanno solo una conviene farlo graficamente); in questo
# caso ottengo differenze nulle o trascurabili (dovute ad approssimazioni)
x <- 7; a <- 5; print(c(x^4-a^2,(x^2-a)*(x^2+a),(x^4-a^2) - (x^2-a)*(x^2+a)))
[1] 2376 2376 0
x <- 3; a <- -5; print(c(x^4-a^2,(x^2-a)*(x^2+a),(x^4-a^2) - (x^2-a)*(x^2+a)))
[1] 56 56 0
x <- 0.123456; a <- 0.123456; print(c(x^4-a^2,(x^2-a)*(x^2+a),(x^4-a^2) - (x^2-a)*(x^2+a)))
[1] -1.500908e-02 -1.500908e-02 1.734723e-18
#
# Come definire ricorsivamente successioni. Un esempio:
# x(1)=1, x(n+1) = ( x(n) + A/x(n) ) / 2 (che converge a √A)
A <- 155.2516
x <-1; for (i in 1:8) {x <- (x+A/x)/2; print(x)}
[1] 78.1258
[1] 40.0565
[1] 21.96616
[1] 14.51696
[1] 12.60573
[1] 12.46084
[1] 12.46
[1] 12.46
# Alternativa, usando il comando Recall (vediamo un uso per definire
# ricorsivamente il fattoriale):
fat <- function(n) if (n==0) 1 else Recall(n-1)*n
fat(0); fat(1); fat(10); fat(170)
[1] 1
[1] 1
[1] 3628800
[1] 7.257416e+306
# Altra possibilità: usando .Last.value che richiama l'ultimo
# risultato o l'ulitma assegnazione o l'esito dell'ultimo comando ...
1
[1] 1
.Last.value*2
[1] 2
.Last.value*2
[1] 4
.Last.value*2
[1] 8
#
# Il comando str richiama la struttura di oggetti definiti dall'utente
# o incorporati nel programma stesso, e può essere comodo (eventualmente
# accoppiato al comando ls)
x <- -8*2; a <- seq(1,20,1); f <- function(p) p+3
str(x); str(a); str(f); str(3+5^2)
num -16
num [1:20] 1 2 3 4 5 6 7 8 9 10 ...
function (p) "function(p) p+3"
num 28
str(print); str(plot); str(choose); str(factorial)
function (x, ...)
function (x, y, ...)
function (n, k)
function (x)
#
# Comandi, funzioni, costanti, programmi,... possono essere recuperati
# da file, consentendo di gestire R a persone con conoscenze diverse
# (tutta una serie di cose possono essere caricate automaticamente).
# La cosa può essere fatta in modi vari. Il più semplice è l'uso del
# comando source. Se ad es. in un file ho i seguenti comandi:
# boh <- 3
# funprova <- function(pippo) (pippo+1)^2+boh
# e il file è http://macosa.dima.unige.it/om/prg/R/provacom.txt
# ecco che cosa posso ottenere:
source("http://macosa.dima.unige.it/om/prg/R/provacom.txt")
boh; funprova(-3)
[1] 3
[1] 7
# Se il file è sul computer: C:/Users/pippo/Documents/provacom.txt
# basta che batta: source("C:/Users/pippo/Documents/provacom.txt")
#
# Invece di battere "source( )" puoi usare l'analogo comando dal menu File (è
# predisposta la scelta dei file *.R; per vederli tutti usa il bottone a destra).
# Se vuoi visionare il file mettine il nome nella finestra che si apre coi
# comandi (dal menu File) OpenScript/ApriScript o DisplayFile/VisualizzaFile;
# in questo caso metti: http://macosa.dima.unige.it/om/prg/R/provacom.txt.
# Puoi anche usare source("http://macosa/.../R/provacom.txt",echo=TRUE)
# Nel nostro caso abbiamo messo anche un "help" azionabile con "aiuto"
# (vedi il file).
aiuto
[1] "Sono stati caricati i valori di boh e la definizione della funzione"
[2] "funprova. Per ora con c'è altro."
# Il file http://macosa.dima.unige.it/om/prg/R/provaco2.txt (vedilo) stampa
# invece automaticamente lo stesso "help".
# (Un'altra possibilità è mettere i comandi da richiamare in una sessione
# di R, salvare questa con Save WorkSpace come file con estensione RData;
# quando si ricarica il file con Load WorkSpace essi vengono automaticamente
# richiamati)
# Ovviamente, in alternativa, posso aprire il file e incollarlo dove
# sto lavorando, o farmi una banca di comandi da salvarmi e mettere
# sul mio computer in uno o più file, e caricarli quando serve
# Save History consente di salvare (in formato testo) tutti i comandi
# eseguiti (che possono essere poi richiamati con Load History;
# Load History può essere usato anche per richiamare comandi battuti
# fuori da R)
#
# Osserviamo che se un comando è lungo si puo' scriverlo tutto su una
# stessa riga fino a qualche migliaio di caratteri, o si puo' andare a
# capo: la riga successiva viene interpretata come continuazione (sullo
# schermo è aggiunto automaticamente un "+" all'inizio della nuova riga)
# Ecco un esempio d'uso di questa possibilità:
dati <- c(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,
22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40); mean(dati)
[1] 20.5
# Può essere utile (per agevolare la lettura) mettere degli spazi bianchi
# e degli opportuni "a capo"
dati <- c(1, 2, 3, 4, 5, 6, 7, 8, 9,10,11,12,13,14,15,16,17,18,19,20,
21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40)
#
# A differenza di altre applicazioni, le stringhe non sono concatenate
# con "+", ma occorre usare altri comandi. Ad es. si può usare paste
# ("paste" = "incolla"):
paste("ca","sa",sep=""); paste("sa","ca",sep=""); paste("ca","sa",sep=" ")
[1] "casa"
[1] "saca"
[1] "ca sa"
# Per estrarre la sottostringa dal posto M all'N si usa substr(stringa,M,N)
substr("abcdefgh",3,5)
[1] "cde"
# nchar dà il numero dei caratteri di una stringa
nchar('1234567890 - 1234567890')
[1] 23
# tolower e toupper trasformano le dimensioni dei caratteri di una stringa:
tolower("piPPo"); toupper("piPPo")
[1] "pippo"
[1] "PIPPO"
#
# È possibile caricare file visualizzabili in html con browseURL
# Prova ad eseguire i seguenti comandi:
browseURL("http://macosa.dima.unige.it/om/prg/R/alf.htm")
browseURL("http://macosa.dima.unige.it/peace.gif")
#
# Un file per fare grafici e calcoli vari automaticamente lo trovi qui
source("http://macosa.dima.unige.it/R.R")
# ovvero vedi qui
optimize(f,c(2,4),maximum = TRUE,tol=1e-12)
$maximum
[1] 3.119633
$objective
[1] 12.06067
print(optimize(f,c(2,4),maximum = TRUE,tol=1e-13),12)
$maximum
[1] 3.11963298088
$objective
[1] 12.0606725872
print(optimize(f,c(-1,1),maximum = FALSE,tol=1e-13),12)
$minimum
[1] 0.213700352165
$objective
[1] -0.208820735354
#
# Il mass. com. divisore di due numeri naturali (con l'algoritmo
# euclideo) e il min. com. multiplo
mcd <- function(m,n) {a <- m; r <- n; while(r > 0)
{b <- r; q <- floor(a/b); r <- a-b*q; a <- b}; a}
mcm <- function(m,n) m*n/mcd(m,n)
mcd(3276,396); mcm(3276,396)
[1] 36
[1] 36036
# Possiamo facilmente estendere queste funzioni a più input:
MCD <- function(x) {m <- x[1]; for(i in 2:length(x)) m <- mcd(m,x[i]); m}
MCM <- function(x) {m <- x[1]; for(i in 2:length(x)) m <- mcm(m,x[i]); m}
MCD(c(2,3,10)); MCM(c(2,3,10))
[1] 1
[1] 30
#
# Un modo per confrontare se termini contenenti più di una variabile
# sono uguali (se ne hanno solo una conviene farlo graficamente); in questo
# caso ottengo differenze nulle o trascurabili (dovute ad approssimazioni)
x <- 7; a <- 5; print(c(x^4-a^2,(x^2-a)*(x^2+a),(x^4-a^2) - (x^2-a)*(x^2+a)))
[1] 2376 2376 0
x <- 3; a <- -5; print(c(x^4-a^2,(x^2-a)*(x^2+a),(x^4-a^2) - (x^2-a)*(x^2+a)))
[1] 56 56 0
x <- 0.123456; a <- 0.123456; print(c(x^4-a^2,(x^2-a)*(x^2+a),(x^4-a^2) - (x^2-a)*(x^2+a)))
[1] -1.500908e-02 -1.500908e-02 1.734723e-18
#
# Come definire ricorsivamente successioni. Un esempio:
# x(1)=1, x(n+1) = ( x(n) + A/x(n) ) / 2 (che converge a √A)
A <- 155.2516
x <-1; for (i in 1:8) {x <- (x+A/x)/2; print(x)}
[1] 78.1258
[1] 40.0565
[1] 21.96616
[1] 14.51696
[1] 12.60573
[1] 12.46084
[1] 12.46
[1] 12.46
# Alternativa, usando il comando Recall (vediamo un uso per definire
# ricorsivamente il fattoriale):
fat <- function(n) if (n==0) 1 else Recall(n-1)*n
fat(0); fat(1); fat(10); fat(170)
[1] 1
[1] 1
[1] 3628800
[1] 7.257416e+306
# Altra possibilità: usando .Last.value che richiama l'ultimo
# risultato o l'ulitma assegnazione o l'esito dell'ultimo comando ...
1
[1] 1
.Last.value*2
[1] 2
.Last.value*2
[1] 4
.Last.value*2
[1] 8
#
# Il comando str richiama la struttura di oggetti definiti dall'utente
# o incorporati nel programma stesso, e può essere comodo (eventualmente
# accoppiato al comando ls)
x <- -8*2; a <- seq(1,20,1); f <- function(p) p+3
str(x); str(a); str(f); str(3+5^2)
num -16
num [1:20] 1 2 3 4 5 6 7 8 9 10 ...
function (p) "function(p) p+3"
num 28
str(print); str(plot); str(choose); str(factorial)
function (x, ...)
function (x, y, ...)
function (n, k)
function (x)
#
# Comandi, funzioni, costanti, programmi,... possono essere recuperati
# da file, consentendo di gestire R a persone con conoscenze diverse
# (tutta una serie di cose possono essere caricate automaticamente).
# La cosa può essere fatta in modi vari. Il più semplice è l'uso del
# comando source. Se ad es. in un file ho i seguenti comandi:
# boh <- 3
# funprova <- function(pippo) (pippo+1)^2+boh
# e il file è http://macosa.dima.unige.it/om/prg/R/provacom.txt
# ecco che cosa posso ottenere:
source("http://macosa.dima.unige.it/om/prg/R/provacom.txt")
boh; funprova(-3)
[1] 3
[1] 7
# Se il file è sul computer: C:/Users/pippo/Documents/provacom.txt
# basta che batta: source("C:/Users/pippo/Documents/provacom.txt")
#
# Invece di battere "source( )" puoi usare l'analogo comando dal menu File (è
# predisposta la scelta dei file *.R; per vederli tutti usa il bottone a destra).
# Se vuoi visionare il file mettine il nome nella finestra che si apre coi
# comandi (dal menu File) OpenScript/ApriScript o DisplayFile/VisualizzaFile;
# in questo caso metti: http://macosa.dima.unige.it/om/prg/R/provacom.txt.
# Puoi anche usare source("http://macosa/.../R/provacom.txt",echo=TRUE)
# Nel nostro caso abbiamo messo anche un "help" azionabile con "aiuto"
# (vedi il file).
aiuto
[1] "Sono stati caricati i valori di boh e la definizione della funzione"
[2] "funprova. Per ora con c'è altro."
# Il file http://macosa.dima.unige.it/om/prg/R/provaco2.txt (vedilo) stampa
# invece automaticamente lo stesso "help".
# (Un'altra possibilità è mettere i comandi da richiamare in una sessione
# di R, salvare questa con Save WorkSpace come file con estensione RData;
# quando si ricarica il file con Load WorkSpace essi vengono automaticamente
# richiamati)
# Ovviamente, in alternativa, posso aprire il file e incollarlo dove
# sto lavorando, o farmi una banca di comandi da salvarmi e mettere
# sul mio computer in uno o più file, e caricarli quando serve
# Save History consente di salvare (in formato testo) tutti i comandi
# eseguiti (che possono essere poi richiamati con Load History;
# Load History può essere usato anche per richiamare comandi battuti
# fuori da R)
#
# Osserviamo che se un comando è lungo si puo' scriverlo tutto su una
# stessa riga fino a qualche migliaio di caratteri, o si puo' andare a
# capo: la riga successiva viene interpretata come continuazione (sullo
# schermo è aggiunto automaticamente un "+" all'inizio della nuova riga)
# Ecco un esempio d'uso di questa possibilità:
dati <- c(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,
22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40); mean(dati)
[1] 20.5
# Può essere utile (per agevolare la lettura) mettere degli spazi bianchi
# e degli opportuni "a capo"
dati <- c(1, 2, 3, 4, 5, 6, 7, 8, 9,10,11,12,13,14,15,16,17,18,19,20,
21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40)
#
# A differenza di altre applicazioni, le stringhe non sono concatenate
# con "+", ma occorre usare altri comandi. Ad es. si può usare paste
# ("paste" = "incolla"):
paste("ca","sa",sep=""); paste("sa","ca",sep=""); paste("ca","sa",sep=" ")
[1] "casa"
[1] "saca"
[1] "ca sa"
# Per estrarre la sottostringa dal posto M all'N si usa substr(stringa,M,N)
substr("abcdefgh",3,5)
[1] "cde"
# nchar dà il numero dei caratteri di una stringa
nchar('1234567890 - 1234567890')
[1] 23
# tolower e toupper trasformano le dimensioni dei caratteri di una stringa:
tolower("piPPo"); toupper("piPPo")
[1] "pippo"
[1] "PIPPO"
#
# È possibile caricare file visualizzabili in html con browseURL
# Prova ad eseguire i seguenti comandi:
browseURL("http://macosa.dima.unige.it/om/prg/R/alf.htm")
browseURL("http://macosa.dima.unige.it/peace.gif")
#
# Un file per fare grafici e calcoli vari automaticamente lo trovi qui
source("http://macosa.dima.unige.it/R.R")
# ovvero vedi qui
#
# Vediamo come affrontare alcune attività di tipo STATISTICO
#
# Abbiamo già visto che c() consente di fare una collezione di valori,
# su cui possiamo fare varie attività: trovare la lunghezza, minimo,
# massimo e range, ordinarla, trovare media, mediana, somma e prodotto.
x <- c(10.4, 5.6, 3.1, 6.4, 21.7); x
[1] 10.4 5.6 3.1 6.4 21.7
length(x); min(x); max(x); range(x); sort(x)
[1] 5
[1] 3.1
[1] 21.7
[1] 3.1 21.7
[1] 3.1 5.6 6.4 10.4 21.7
mean(x); median(x); sum(x); prod(x)
[1] 9.44
[1] 6.4
[1] 47.2
[1] 25073.95
# Posso definire il punto medio e la distanza tra due punti, in modo
# che funzioni sia sulla retta che nel piano o nello spazio:
pm <- function(P1,P2) P1+(P2-P1)/2
pm(1,2)
[1] 1.5
pm(c(1,1,1), c(2,3,3))
[1] 1.5 2.0 2.0
dist <- function(P1,P2) sqrt(sum((P1-P2)^2))
dist(7,3)
[1] 4
dist(c(1,1), c(2,3))
[1] 2.236068
dist(c(1,1,1), c(2,3,3))
[1] 3
# Verificare una condizione sugli elementi di una collezione x
x >= 13
[1] FALSE FALSE FALSE FALSE TRUE
# posso da x ottenere altri dati
y <- 1/x; y
[1] 0.09615385 0.17857143 0.32258065 0.15625000 0.04608295
a <- x+y; a
[1] 10.496154 5.778571 3.422581 6.556250 21.746083
b <- c(x,0,y); b # unire collezioni di dati
[1] 10.40000000 5.60000000 3.10000000 6.40000000 21.70000000 0.00000000 0.09615385
[8] 0.17857143 0.32258065 0.15625000 0.04608295
#
# generazione di alcune sequenze di numeri interi:
5:11; 5:11-1; 5:(11-1); 11:5
[1] 5 6 7 8 9 10 11
[1] 4 5 6 7 8 9 10
[1] 5 6 7 8 9 10
[1] 11 10 9 8 7 6 5
# altro es.:
(1:10)^3
[1] 1 8 27 64 125 216 343 512 729 1000
# generazione di altre sequenze:
s2 <- (5:11)/2; s3 <- seq(6); s4 <- seq(3,9); s5 <- seq(3,10,0.8); s6 <- seq(3,10,by=0.8)
s2; s3; s4; s5; s6
[1] 2.5 3.0 3.5 4.0 4.5 5.0 5.5
[1] 1 2 3 4 5 6
[1] 3 4 5 6 7 8 9
[1] 3.0 3.8 4.6 5.4 6.2 7.0 7.8 8.6 9.4
[1] 3.0 3.8 4.6 5.4 6.2 7.0 7.8 8.6 9.4
# seq genera una sequenza di numeri interi: i primi n interi positivi se tra
# parentesi metto solo n o i numeri che vanno di 1 in 1 da a a b se metto a,b
# o quelli che vanno di h in h da a a b se metto a,b,h o a,b,by=h o ...
seq(3,10,len=4); seq(3,by=0.8,len=6); seq(2.4,7)
[1] 3.000000 5.333333 7.666667 10.000000
[1] 3.0 3.8 4.6 5.4 6.2 7.0
[1] 2.4 3.4 4.4 5.4 6.4
# ... gli n numeri che vanno da a a b se metto a,b,len=n o che partono da a e
# vanno di h in h se metto a,by=h,len=n (al posto di len posso scrivere length)
# o i numeri che vanno da a a b di passo 1 se metto a,b
#
# modi per ripetere più volte dei dati:
x <- c(10.4, 5.6, 3.1, 6.4, 21.7); rep(x,times=5) # o: rep(x, 5)
[1] 10.4 5.6 3.1 6.4 21.7 10.4 5.6 3.1 6.4 21.7 10.4 5.6 3.1 6.4 21.7 10.4 5.6 3.1
[19] 6.4 21.7 10.4 5.6 3.1 6.4 21.7
rep(x,each=5)
[1] 10.4 10.4 10.4 10.4 10.4 5.6 5.6 5.6 5.6 5.6 3.1 3.1 3.1 3.1 3.1 6.4 6.4 6.4
[19] 6.4 6.4 21.7 21.7 21.7 21.7 21.7
#
# analisi dei dati relativi ad un gruppo di alunne quindicenni (altezze in cm)
alu <- c(156,168,162,150,167,157,170,157,159,164,157,165,163,165,166,160,163,162,155)
length(alu); min(alu); max(alu); range(alu); sort(alu)
[1] 19
[1] 150
[1] 170
[1] 150 170
[1] 150 155 156 157 157 157 159 160 162 162 163 163 164 165 165 166 167 168 170
# la sottosuccessione ottenuta togliendo il primo e l'ultimo dato:
alu[ 2:(length(alu)-1) ]
[1] 168 162 150 167 157 170 157 159 164 157 165 163 165 166 160 163 162
mean(alu); median(alu)
[1] 161.3684
[1] 162
# i dati precedenti riprodotti in forma grafica (stem-and-leaf);
# vedi la soluz. di questo es. - clicca >>>)
stem(alu)
The decimal point is 1 digit(s) to the right of the |
15 | 0
15 | 567779
16 | 022334
16 | 55678
17 | 0
# un modo per contare le lunghezze delle colonne, anche parziali
stem(alu, width = 0)
15 | +1
15 | +6
16 | +6
16 | +5
17 | +1
stem(alu, width = 2)
15 |
15 | +4
16 | +4
16 | +3
17 |
# come scegliere intervalli diversi (lo standard equivale a scale=1)
stem(alu,scale=0.5)
15 | 0567779
16 | 02233455678
17 | 0
stem(alu,scale=3)
150 | 0
152 |
154 | 0
156 | 0000
158 | 0
160 | 0
162 | 0000
164 | 000
166 | 00
168 | 0
170 | 0
#
# Ovviamente, quando i dati sono pochi, si possono ottenere istogrammi
# abbastanza diversi a seconda delle scelte operate; lo abbiamo visto ora
# con gli "stem". Vediamolo usando il comando hist, che se non si sceglie
# il numero delle classi lo sceglie automaticamente e, se non si specifica
# come classificare i dati, lo fa, in genere, in intervalli del tipo (,]
 hist(alu) # (1)
hist(alu,right=FALSE) # (2)
hist(alu,nclass=10) # (3)
hist(alu,right=FALSE,nclass=10) # (4)
#
# Posso avere informazioni sui valori con cui è stato costruito l'istogramma e sulle
# frequenze delle varie classi (counts) con:
hist(alu,plot=FALSE,right=FALSE)
$breaks
[1] 150 155 160 165 170
$counts
[1] 1 6 6 6
$density
[1] 0.01052632 0.06315789 0.06315789 0.06315789
$mids
[1] 152.5 157.5 162.5 167.5
...
hist(alu,plot=FALSE,right=FALSE)$counts
[1] 1 6 6 6
hist(alu,plot=FALSE,right=FALSE)$counts[3]
[1] 6
#
# Ecco come realizzarli scegliendo le classi: scelto un certo intervallo
# (da 140 a 180) e la ampiezza (5) delle classi in cui suddividerlo,
# classifico i dati in intervalli del tipo [.,.) - right=FALSE - ossia
# [140,145), [145,150), [150,155), …, come fa automaticamente lo stem, o
# (.,.] - right=TRUE - ossia (140,145], (145,150], (150,155], …:
hist(alu, seq(140,180,5), right=FALSE)
hist(alu, seq(140,180,5), right=TRUE)
hist(alu) # (1)
hist(alu,right=FALSE) # (2)
hist(alu,nclass=10) # (3)
hist(alu,right=FALSE,nclass=10) # (4)
#
# Posso avere informazioni sui valori con cui è stato costruito l'istogramma e sulle
# frequenze delle varie classi (counts) con:
hist(alu,plot=FALSE,right=FALSE)
$breaks
[1] 150 155 160 165 170
$counts
[1] 1 6 6 6
$density
[1] 0.01052632 0.06315789 0.06315789 0.06315789
$mids
[1] 152.5 157.5 162.5 167.5
...
hist(alu,plot=FALSE,right=FALSE)$counts
[1] 1 6 6 6
hist(alu,plot=FALSE,right=FALSE)$counts[3]
[1] 6
#
# Ecco come realizzarli scegliendo le classi: scelto un certo intervallo
# (da 140 a 180) e la ampiezza (5) delle classi in cui suddividerlo,
# classifico i dati in intervalli del tipo [.,.) - right=FALSE - ossia
# [140,145), [145,150), [150,155), …, come fa automaticamente lo stem, o
# (.,.] - right=TRUE - ossia (140,145], (145,150], (150,155], …:
hist(alu, seq(140,180,5), right=FALSE)
hist(alu, seq(140,180,5), right=TRUE)
 # nel seguito dell'help sceglieremo la prima forma; ecco l'istogramma
# in intervalli di altra ampiezza, colorato, senza scritte:
# (con main si può inserire un titolo alternativo, eventualmente 'vuoto',
# al posto di quello automaticamente generato dal comando hist)
hist(alu,seq(150,171,3),right=FALSE,col="yellow",xlab="",ylab="",main="")
# nel seguito dell'help sceglieremo la prima forma; ecco l'istogramma
# in intervalli di altra ampiezza, colorato, senza scritte:
# (con main si può inserire un titolo alternativo, eventualmente 'vuoto',
# al posto di quello automaticamente generato dal comando hist)
hist(alu,seq(150,171,3),right=FALSE,col="yellow",xlab="",ylab="",main="")
 # Volendo puoi far gestire al software l'istogramma specificando con nclass più o meno
# in quante classi vuoi siano classificati i dati [viene scelto un n. di classi tale che
# esse siano ampie 1, 2 o 5 volte una potenza di 10; puoi omettere "nclass=":
# hist(alu,8, ... ].
hist(alu,nclass=8,right=FALSE,col="yellow",xlab="",main="")
# Volendo puoi far gestire al software l'istogramma specificando con nclass più o meno
# in quante classi vuoi siano classificati i dati [viene scelto un n. di classi tale che
# esse siano ampie 1, 2 o 5 volte una potenza di 10; puoi omettere "nclass=":
# hist(alu,8, ... ].
hist(alu,nclass=8,right=FALSE,col="yellow",xlab="",main="")
 # si può tracciare anche l'istogramma in classi di diverse
# ampiezze; sulla scala verticale appare la densità, ossia
# il rapporto tra le frequenze e le ampiezze delle classi (si
# può ottenere anche negli altri casi questa scala verticale
# aggiungendo l'opzione probability=TRUE o freq=FALSE)
hist(alu,c(150,156,159,162,168,171),right=FALSE,xlab="",main="")
# si può tracciare anche l'istogramma in classi di diverse
# ampiezze; sulla scala verticale appare la densità, ossia
# il rapporto tra le frequenze e le ampiezze delle classi (si
# può ottenere anche negli altri casi questa scala verticale
# aggiungendo l'opzione probability=TRUE o freq=FALSE)
hist(alu,c(150,156,159,162,168,171),right=FALSE,xlab="",main="")
 # Posso colorare anche diverse colonne, sovrapponendo dei rettangoli colorati:
ist <- hist(alu,seq(150,171,3),right=FALSE,probability=TRUE)
# Vediamo gli estremi degli intervalli e le altezze delle colonne:
ist$breaks; ist$density
[1] 150 153 156 159 162 165 168 171
[1] 0.01754386 0.01754386 0.07017544 0.03508772 0.08771930 0.07017544 0.03508772
# Coloro, con colori diversi, la 3ª e la 6ª colonna:
po <- 3; rect(ist$breaks[po],0,ist$breaks[po+1],ist$density[po],col="red")
po <- 6; rect(ist$breaks[po],0,ist$breaks[po+1],ist$density[po],col="yellow")
# Posso colorare anche diverse colonne, sovrapponendo dei rettangoli colorati:
ist <- hist(alu,seq(150,171,3),right=FALSE,probability=TRUE)
# Vediamo gli estremi degli intervalli e le altezze delle colonne:
ist$breaks; ist$density
[1] 150 153 156 159 162 165 168 171
[1] 0.01754386 0.01754386 0.07017544 0.03508772 0.08771930 0.07017544 0.03508772
# Coloro, con colori diversi, la 3ª e la 6ª colonna:
po <- 3; rect(ist$breaks[po],0,ist$breaks[po+1],ist$density[po],col="red")
po <- 6; rect(ist$breaks[po],0,ist$breaks[po+1],ist$density[po],col="yellow")
 # Posso aggiungere griglia e altezze delle colonne (le freq. perc.):
hist(alu,c(150,156,159,162,168,171),right=FALSE,xlab="",main="",labels=TRUE,ylim=c(0,0.09))
abline(h=axTicks(2), col="blue",lty=3)
# Posso aggiungere griglia e altezze delle colonne (le freq. perc.):
hist(alu,c(150,156,159,162,168,171),right=FALSE,xlab="",main="",labels=TRUE,ylim=c(0,0.09))
abline(h=axTicks(2), col="blue",lty=3)
 # se come ultimo estremo metto 170 invece di 171, anche se ho scelto
# intervalli right=FALSE, l'istogramma accetta anche il dato 170:
# se come ultimo estremo metto 170 invece di 171, anche se ho scelto
# intervalli right=FALSE, l'istogramma accetta anche il dato 170:
 # il comando summary dà una sintesi delle informazioni statistiche sui
# dati: min e max, mediana e media, 1º quartile (o 25º percentile)
# e 3º quartile (o 75º percentile):
summary(alu)
Min. 1st Qu. Median Mean 3rd Qu. Max.
150.0 157.0 162.0 161.4 165.0 170.0
# Posso aumentare le cifre usando digits
summary(alu, digits=6)
Min. 1st Qu. Median Mean 3rd Qu. Max.
150.000 157.000 162.000 161.368 165.000 170.000
# Per avere solo min, 1st Qu, Median, 3rd Qu posso usare fivenum:
fivenum(alu)
[1] 150 157 162 165 170
fivenum(alu)[2]
[1] 157
# altri dati e confronto con i precedenti mediante due box-plot: il box
# centrale inizia dal primo quartile, è tagliato dal secondo (mediana) e
# termina col terzo; i baffi iniziano dal minimo e finiscono col massimo
alu <- c(156,168,162,150,167,157,170,157,159,164,157,165,163,165,166,160,163,162,155)
alu2 <- c(172,162,150,167,157,170,157,159,164,157,165,163,165,166,160,163,162,155)
summary(alu2)
Min. 1st Qu. Median Mean 3rd Qu. Max.
150.0 157.5 162.5 161.9 165.0 172.0
boxplot(alu,alu2)
# il comando summary dà una sintesi delle informazioni statistiche sui
# dati: min e max, mediana e media, 1º quartile (o 25º percentile)
# e 3º quartile (o 75º percentile):
summary(alu)
Min. 1st Qu. Median Mean 3rd Qu. Max.
150.0 157.0 162.0 161.4 165.0 170.0
# Posso aumentare le cifre usando digits
summary(alu, digits=6)
Min. 1st Qu. Median Mean 3rd Qu. Max.
150.000 157.000 162.000 161.368 165.000 170.000
# Per avere solo min, 1st Qu, Median, 3rd Qu posso usare fivenum:
fivenum(alu)
[1] 150 157 162 165 170
fivenum(alu)[2]
[1] 157
# altri dati e confronto con i precedenti mediante due box-plot: il box
# centrale inizia dal primo quartile, è tagliato dal secondo (mediana) e
# termina col terzo; i baffi iniziano dal minimo e finiscono col massimo
alu <- c(156,168,162,150,167,157,170,157,159,164,157,165,163,165,166,160,163,162,155)
alu2 <- c(172,162,150,167,157,170,157,159,164,157,165,163,165,166,160,163,162,155)
summary(alu2)
Min. 1st Qu. Median Mean 3rd Qu. Max.
150.0 157.5 162.5 161.9 165.0 172.0
boxplot(alu,alu2)
 # Aggiungendo varwidth=TRUE i box sono tracciati con larghezza proporzionale
# alla radice quadrata del numero dei dati (dal diagramma capisco così
# subito che i dati sono meno)
alu3 <- c(172,162,157,164,165,166,160,163,155)
boxplot(alu,alu2,alu3,varwidth=TRUE)
# Aggiungendo varwidth=TRUE i box sono tracciati con larghezza proporzionale
# alla radice quadrata del numero dei dati (dal diagramma capisco così
# subito che i dati sono meno)
alu3 <- c(172,162,157,164,165,166,160,163,155)
boxplot(alu,alu2,alu3,varwidth=TRUE)
 #
# per vedere meglio il significato dei box-plot generati da R vediamo
# quelli dei dati 40,41,42,51,52,53,54,55,56,57,58,59,60
x <- c(40,41,42,51,52,53,54,55,56,57,58,59,60)
boxplot(x, horizontal=TRUE, col="yellow")
#
# per vedere meglio il significato dei box-plot generati da R vediamo
# quelli dei dati 40,41,42,51,52,53,54,55,56,57,58,59,60
x <- c(40,41,42,51,52,53,54,55,56,57,58,59,60)
boxplot(x, horizontal=TRUE, col="yellow")
 # R evidenzia con dei pallini gli eventuali dati che precedono il 25º
# percentile o seguono il 75º per più di 1.5 volte la distanza
# interquartile. Con l'opzione range=0 si può evitare la visualizzazione
# dei "pallini" (con altri valori di range=... ho altre visualizzazioni).
# Il secondo box-plot ha anche delle tacche che rappresentano i valori dei
# vari dati; sono state aggiunte col comando rug, in cui si è specificato
# anche che le tacche devono essere alte 0.2 volte l'altezza del riquadro
# (occorre, a rug, aggiungere l'opzione "side=2" se il box è verticale:
# vedi l'help on-line di "rug" - è il "tappeto" [dei nostri grafici]).
rug(x,ticksize=0.2)
#
# Volendo avere anche il 5º e il 95º percentile posso fare:
quantile(alu,0.05); quantile(alu,0.95)
5%
154.5
95%
168.2
quantile(alu2,0.05); quantile(alu2,0.95)
5%
154.25
95%
170.3
# Se voglio solo i valori (come posso vedere dall'help) aggiungo name=FALSE:
quantile(alu,0.05,name=FALSE); quantile(alu, c(0.05, 0.25, 0.5, 0.75, 0.95), name=FALSE)
[1] 154.5
[1] 154.5 157.0 162.0 165.0 168.2
# Volendo possiamo evidenziare sul boxplot altri percentili. Ecco la
# visualizzazione sullo stesso boxplot (per i dati x e y) dei percentili
# 5°,95°,10°,90°,20°,80° in forme e colori diversi (vedi qui per "pch")
# (come ordinata dei "points" tracciati devo prendere 1 e 2 per x ed y)
x <- c(40,41,42,51,52,53,54,55,56,57,58,59,60)
y <- c(40,41,42,51,52,53,54,55,56,57,58,59)
boxplot(x,y, horizontal=TRUE, col="yellow", range=0)
points(quantile(x,0.05),1,col="blue"); points(quantile(x,0.95),1,col="blue")
points(quantile(x,0.9),1,col="red",pch=20); points(quantile(x,0.1),1,col="red",pch=20)
points(quantile(x,0.2),1,pch=25); points(quantile(x,0.8),1,pch=25)
points(quantile(y,0.05),2,col="blue"); points(quantile(y,0.95),2,col="blue")
points(quantile(y,0.9),2,col="red",pch=20); points(quantile(y,0.1),2,col="red",pch=20)
points(quantile(y,0.2),2,pch=25); points(quantile(y,0.8),2,pch=25)
# R evidenzia con dei pallini gli eventuali dati che precedono il 25º
# percentile o seguono il 75º per più di 1.5 volte la distanza
# interquartile. Con l'opzione range=0 si può evitare la visualizzazione
# dei "pallini" (con altri valori di range=... ho altre visualizzazioni).
# Il secondo box-plot ha anche delle tacche che rappresentano i valori dei
# vari dati; sono state aggiunte col comando rug, in cui si è specificato
# anche che le tacche devono essere alte 0.2 volte l'altezza del riquadro
# (occorre, a rug, aggiungere l'opzione "side=2" se il box è verticale:
# vedi l'help on-line di "rug" - è il "tappeto" [dei nostri grafici]).
rug(x,ticksize=0.2)
#
# Volendo avere anche il 5º e il 95º percentile posso fare:
quantile(alu,0.05); quantile(alu,0.95)
5%
154.5
95%
168.2
quantile(alu2,0.05); quantile(alu2,0.95)
5%
154.25
95%
170.3
# Se voglio solo i valori (come posso vedere dall'help) aggiungo name=FALSE:
quantile(alu,0.05,name=FALSE); quantile(alu, c(0.05, 0.25, 0.5, 0.75, 0.95), name=FALSE)
[1] 154.5
[1] 154.5 157.0 162.0 165.0 168.2
# Volendo possiamo evidenziare sul boxplot altri percentili. Ecco la
# visualizzazione sullo stesso boxplot (per i dati x e y) dei percentili
# 5°,95°,10°,90°,20°,80° in forme e colori diversi (vedi qui per "pch")
# (come ordinata dei "points" tracciati devo prendere 1 e 2 per x ed y)
x <- c(40,41,42,51,52,53,54,55,56,57,58,59,60)
y <- c(40,41,42,51,52,53,54,55,56,57,58,59)
boxplot(x,y, horizontal=TRUE, col="yellow", range=0)
points(quantile(x,0.05),1,col="blue"); points(quantile(x,0.95),1,col="blue")
points(quantile(x,0.9),1,col="red",pch=20); points(quantile(x,0.1),1,col="red",pch=20)
points(quantile(x,0.2),1,pch=25); points(quantile(x,0.8),1,pch=25)
points(quantile(y,0.05),2,col="blue"); points(quantile(y,0.95),2,col="blue")
points(quantile(y,0.9),2,col="red",pch=20); points(quantile(y,0.1),2,col="red",pch=20)
points(quantile(y,0.2),2,pch=25); points(quantile(y,0.8),2,pch=25)
 #
# Se ho una collezione di dati, ecco come posso calcolare frequenze relative:
alu <- c(156,168,162,150,167,157,170,157,159,164,157,165,163,165,166,160,163,162,155)
length(alu); length(subset(alu, alu >= 165))
[1] 19
[1] 6
length(subset(alu, alu >= 165))/length(alu)*100
[1] 31.57895
#
# ecco come ottenere i grafici delle frequenze cumulate relative
# (empirical cumulative distribution function), con
# diverse opzioni:
plot(ecdf(alu))
plot(ecdf(alu), do.points=FALSE)
plot(ecdf(alu), do.points=FALSE, verticals=TRUE)
#
# Se ho una collezione di dati, ecco come posso calcolare frequenze relative:
alu <- c(156,168,162,150,167,157,170,157,159,164,157,165,163,165,166,160,163,162,155)
length(alu); length(subset(alu, alu >= 165))
[1] 19
[1] 6
length(subset(alu, alu >= 165))/length(alu)*100
[1] 31.57895
#
# ecco come ottenere i grafici delle frequenze cumulate relative
# (empirical cumulative distribution function), con
# diverse opzioni:
plot(ecdf(alu))
plot(ecdf(alu), do.points=FALSE)
plot(ecdf(alu), do.points=FALSE, verticals=TRUE)
 # se dispongo della ripartizione di un certo totale nelle sue parti A, B e C posso
# farne un istogramma a barre (bar chart), senza etichette o dando nomi alle 3 classi;
# posso anche realizzare un diagramma a torta (pie chart), con i colori assegnati
# automaticamente o scelti, e dei diagramma per punti (dot chart); i diagrammi a torta
# facilitano il confronto col totale, ma non quello tra le varie voci; vedi "help(pie)".
dati <- c(15.5, 47.8, 36.7); barplot(dati)
names(dati) <- LETTERS[1:length(dati)]; barplot(dati)
pie(dati)
pie(dati, col = c("red","green","yellow"))
dotchart(dati)
# se dispongo della ripartizione di un certo totale nelle sue parti A, B e C posso
# farne un istogramma a barre (bar chart), senza etichette o dando nomi alle 3 classi;
# posso anche realizzare un diagramma a torta (pie chart), con i colori assegnati
# automaticamente o scelti, e dei diagramma per punti (dot chart); i diagrammi a torta
# facilitano il confronto col totale, ma non quello tra le varie voci; vedi "help(pie)".
dati <- c(15.5, 47.8, 36.7); barplot(dati)
names(dati) <- LETTERS[1:length(dati)]; barplot(dati)
pie(dati)
pie(dati, col = c("red","green","yellow"))
dotchart(dati)
 # I diagrammi a barre possono essere usati anche per confrontare quantità
# Vediamo ad es. alcuni moduli di elasticità alla trazione (in N/mm^2):
dati <- c(400,250,214,200,147,113,76,40); dati <- dati*100
nomi <- c("tungsteno","cromo","nickel","ferro","platino","bronzo","oro 18k","stagno")
barplot(dati,horiz=TRUE,names.arg=substr(nomi,1,2))
# ovvero, aggiungendo las=1 per avere le scritte orizzontali
# (las: labels axis style); con las=2/3 si hanno le altre disposizioni
barplot(dati,horiz=TRUE,names.arg=substr(nomi,1,6),las=1)
abline(v=c(1e4,2e4,3e4,4e4), lty=3)
# I diagrammi a barre possono essere usati anche per confrontare quantità
# Vediamo ad es. alcuni moduli di elasticità alla trazione (in N/mm^2):
dati <- c(400,250,214,200,147,113,76,40); dati <- dati*100
nomi <- c("tungsteno","cromo","nickel","ferro","platino","bronzo","oro 18k","stagno")
barplot(dati,horiz=TRUE,names.arg=substr(nomi,1,2))
# ovvero, aggiungendo las=1 per avere le scritte orizzontali
# (las: labels axis style); con las=2/3 si hanno le altre disposizioni
barplot(dati,horiz=TRUE,names.arg=substr(nomi,1,6),las=1)
abline(v=c(1e4,2e4,3e4,4e4), lty=3)
 #
# Posso imporre che lo spazio tra le colonne di un diagramma a barre sia
# nullo, in modo da ottenere un istogramma. Un esempio (sotto a sinistra):
a <- function(n) 1/2^n
barplot(a(1:10), space=0)
abline(v=(1:10), h=axTicks(2), col="brown",lty=3)
#
# Posso imporre che lo spazio tra le colonne di un diagramma a barre sia
# nullo, in modo da ottenere un istogramma. Un esempio (sotto a sinistra):
a <- function(n) 1/2^n
barplot(a(1:10), space=0)
abline(v=(1:10), h=axTicks(2), col="brown",lty=3)
 # Coi comandi seguenti ottengo l'istogramma sopra a destra (type="h" sta
# per "tipo istogramma"):
a <- function(n) 1/2^n
plot(a,1,10, n=10, type="h", lwd=5, xlab="", ylab="",xlim=c(0,10))
# ovvero: plot(1:10,a(1:10),type="h", lwd=5, xlab="", ylab="",xlim=c(0,10))
abline(v=axTicks(1), h=axTicks(2), col="brown",lty=3)
#
# Se dispongo di dati già classificati, in intervalli di diversa ampiezza,
# come i seguenti, relativi alla distribuzione dell'età dei morti in Italia
# nel 1951: negli intervalli di età [0,5), [5,10), [10,20), [20,30), [30,40),
# [40,50), [50,60), [60,75), [75,100) sono morte 729, 35, 77, 132, 134, 285,
# 457, 1401, 1569 migliaia di persone, basta compilare le due righe seguenti:
freq <- c(729,35,77,132,134,285,457,1401,1569)
interv <- c(0,5,10,20,30,40,50,60,75,100) # un dato in più di freq
# e procedere nel modo illustrato qui o, più semplicemente, richiamare a
# scatola nera i comandi ivi impiegati usando il comando source:
source("http://macosa.dima.unige.it/R/daticlas.txt")
Frequenze percentuali e summary:
[1] 15.1276198 0.7262918 1.5978419 2.7391575 2.7806599
[2] 5.9140901 9.4832953 29.0724217 32.5586221
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.00 43.43 66.00 58.32 80.80 100.00
# Coi comandi seguenti ottengo l'istogramma sopra a destra (type="h" sta
# per "tipo istogramma"):
a <- function(n) 1/2^n
plot(a,1,10, n=10, type="h", lwd=5, xlab="", ylab="",xlim=c(0,10))
# ovvero: plot(1:10,a(1:10),type="h", lwd=5, xlab="", ylab="",xlim=c(0,10))
abline(v=axTicks(1), h=axTicks(2), col="brown",lty=3)
#
# Se dispongo di dati già classificati, in intervalli di diversa ampiezza,
# come i seguenti, relativi alla distribuzione dell'età dei morti in Italia
# nel 1951: negli intervalli di età [0,5), [5,10), [10,20), [20,30), [30,40),
# [40,50), [50,60), [60,75), [75,100) sono morte 729, 35, 77, 132, 134, 285,
# 457, 1401, 1569 migliaia di persone, basta compilare le due righe seguenti:
freq <- c(729,35,77,132,134,285,457,1401,1569)
interv <- c(0,5,10,20,30,40,50,60,75,100) # un dato in più di freq
# e procedere nel modo illustrato qui o, più semplicemente, richiamare a
# scatola nera i comandi ivi impiegati usando il comando source:
source("http://macosa.dima.unige.it/R/daticlas.txt")
Frequenze percentuali e summary:
[1] 15.1276198 0.7262918 1.5978419 2.7391575 2.7806599
[2] 5.9140901 9.4832953 29.0724217 32.5586221
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.00 43.43 66.00 58.32 80.80 100.00
 # essendo dati approssimati conviene che li arrotondi agli interi
# (43, 66, 58, 81) o ai decimi (43.4, 66.0, 58.3, 80.8)
# Battendo aiuto (vedi) posso avere un help:
aiuto
[1] Ist. di dati gi� classificati in intervalli di diversa ampiezza. Metti
[2] in freq [con freq <- c(..) ] le frequenze delle varie classi e metti
[3] in interv [con interv <- c(..) ] gli estremi delle classi (gli estremi
[4] sono 1 in pi� delle classi). Se non hai ancora introdotto freq e interv
[5] fallo e ricarica questo file (se ti serve, il nuovo file dei dati
[6] � XxXx - � grosso: non visualizzarlo). L'istogramma ha area 1.
[7] Se vuoi prova con: freq <- c(9,12,9); interv <- c(5,15,20,35)
plot(ecdf(XxXx),xlab="", ylab="",main="")
# main ="" è per non avere il "titolo" con XxXx
# essendo dati approssimati conviene che li arrotondi agli interi
# (43, 66, 58, 81) o ai decimi (43.4, 66.0, 58.3, 80.8)
# Battendo aiuto (vedi) posso avere un help:
aiuto
[1] Ist. di dati gi� classificati in intervalli di diversa ampiezza. Metti
[2] in freq [con freq <- c(..) ] le frequenze delle varie classi e metti
[3] in interv [con interv <- c(..) ] gli estremi delle classi (gli estremi
[4] sono 1 in pi� delle classi). Se non hai ancora introdotto freq e interv
[5] fallo e ricarica questo file (se ti serve, il nuovo file dei dati
[6] � XxXx - � grosso: non visualizzarlo). L'istogramma ha area 1.
[7] Se vuoi prova con: freq <- c(9,12,9); interv <- c(5,15,20,35)
plot(ecdf(XxXx),xlab="", ylab="",main="")
# main ="" è per non avere il "titolo" con XxXx
 # Vedi qui come ottenere boxplot di dati già classificati:
# Vedi qui come ottenere boxplot di dati già classificati:
 (evoluz. distr. per età della popolaz. italiana)
#
# Per aver solo l'istogramma posso semplicemente fare (senza
# richiamare scatole nere)
freq <- c(729,35,77,132,134,285,457,1401,1569)
amp <- c( 5, 5,10, 10, 10, 10, 10, 15, 25)
# Le densità di freq. sono freq/sum(freq)/amp:
barplot(freq/sum(freq)/amp*100,space=0, width=amp)
abline(h=axTicks(2),v=axTicks(1), lty=3)
title("freq.% morti tra 0 e 100 anni")
axis(1,pos=0,label=TRUE)
(evoluz. distr. per età della popolaz. italiana)
#
# Per aver solo l'istogramma posso semplicemente fare (senza
# richiamare scatole nere)
freq <- c(729,35,77,132,134,285,457,1401,1569)
amp <- c( 5, 5,10, 10, 10, 10, 10, 15, 25)
# Le densità di freq. sono freq/sum(freq)/amp:
barplot(freq/sum(freq)/amp*100,space=0, width=amp)
abline(h=axTicks(2),v=axTicks(1), lty=3)
title("freq.% morti tra 0 e 100 anni")
axis(1,pos=0,label=TRUE)

 # Vedi qui per la rappresentazione a destra, migliore.
#
# Per avere la media, presi i centri degli intervalli, posso fare:
cinterv <- c(2.5, 7.5, 15, 25, 35, 45, 55, 67.5, 87.5)
dati <- rep(cinterv, freq); mean(dati)
[1] 58.32019
# Nell'esempio precedente il primo intervallo aveva come estremo sinistro 0.
# Vedi qui come fare quando il primo intervallo non è [0,…)
#
# I dati possono essere anche recuperati dal computer o in rete,
# senza dei copia/incolla; ad esempio col comando:
readLines("http://macosa.dima.unige.it/om/prg/R/alunne.txt")
[1] "# altezze alunne" "156" "168" "162"
[5] "150" "167" "157" "170"
[9] "157" "159" "164" "157"
[13] "165" "163" "165" "166"
[17] "160" "163" "162" "155"
[21] "" ""
# Volendo potevo già assegnare i dati ad una variabile (ad es. "dati")
# in un file e richiamare il file con source. Ad es.
readLines("http://macosa.dima.unige.it/om/prg/R/dati_alunne.txt",n=3)
[1] "dati <- c(156,168,162,150,167, 157,170,157,159,164,"
[2] " 157,165,163,165,166, 160,163,162,155)"
[3] ""
# mi fa vedere che nel file dati_alunne è contenuta l'assegnazione a
# "dati" di 19 dati; col comando source eseguo questa assegnazione
source("http://macosa.dima.unige.it/om/prg/R/dati_alunne.txt")
# A questo punto in dati ho i valori indicati.
#
# Ritorniamo ora al contenuto del file alunne.txt presente in rete;
# vediamo che la prima riga è un commento; allora col seguente
# comando metto in "dati" il file saltando con skip una riga
dati <- scan("http://macosa.dima.unige.it/om/prg/R/alunne.txt", skip=1)
dati
[1] 156 168 162 150 167 157 170 157 159 164 157 165 163 165 166 160
[17] 163 162 155
# [se i dati hanno parte fraz. separata da "," invece che da "." vedi qui]
# poi posso eleborare il file come fatto sopra; ad es:
hist(dati,seq(150,171,3),right=FALSE,col="yellow",xlab="",main="")
# Vedi qui per la rappresentazione a destra, migliore.
#
# Per avere la media, presi i centri degli intervalli, posso fare:
cinterv <- c(2.5, 7.5, 15, 25, 35, 45, 55, 67.5, 87.5)
dati <- rep(cinterv, freq); mean(dati)
[1] 58.32019
# Nell'esempio precedente il primo intervallo aveva come estremo sinistro 0.
# Vedi qui come fare quando il primo intervallo non è [0,…)
#
# I dati possono essere anche recuperati dal computer o in rete,
# senza dei copia/incolla; ad esempio col comando:
readLines("http://macosa.dima.unige.it/om/prg/R/alunne.txt")
[1] "# altezze alunne" "156" "168" "162"
[5] "150" "167" "157" "170"
[9] "157" "159" "164" "157"
[13] "165" "163" "165" "166"
[17] "160" "163" "162" "155"
[21] "" ""
# Volendo potevo già assegnare i dati ad una variabile (ad es. "dati")
# in un file e richiamare il file con source. Ad es.
readLines("http://macosa.dima.unige.it/om/prg/R/dati_alunne.txt",n=3)
[1] "dati <- c(156,168,162,150,167, 157,170,157,159,164,"
[2] " 157,165,163,165,166, 160,163,162,155)"
[3] ""
# mi fa vedere che nel file dati_alunne è contenuta l'assegnazione a
# "dati" di 19 dati; col comando source eseguo questa assegnazione
source("http://macosa.dima.unige.it/om/prg/R/dati_alunne.txt")
# A questo punto in dati ho i valori indicati.
#
# Ritorniamo ora al contenuto del file alunne.txt presente in rete;
# vediamo che la prima riga è un commento; allora col seguente
# comando metto in "dati" il file saltando con skip una riga
dati <- scan("http://macosa.dima.unige.it/om/prg/R/alunne.txt", skip=1)
dati
[1] 156 168 162 150 167 157 170 157 159 164 157 165 163 165 166 160
[17] 163 162 155
# [se i dati hanno parte fraz. separata da "," invece che da "." vedi qui]
# poi posso eleborare il file come fatto sopra; ad es:
hist(dati,seq(150,171,3),right=FALSE,col="yellow",xlab="",main="")
 # I dati raccolti da rete posso poi metterli (usando paste) in una variabile;
# ecco come metterci i dati raccolti prima in "dati":
d <- dati[1]; for(i in 2:length(dati)) d <- paste(d,",",dati[i],sep="")
# A questo punto se batto "d" ottengo i dati, che se voglio copio e
# incollo in una assegnazione del tipo dati2 <- c(...)
[1] "156,168,162,150,167,157,170,157,159,164,157,165,163,165,166,160,163,162,155"
#
# Vediamo come raccogliere ed esaminare da rete un file di dati con frequenza
readLines("http://macosa.dima.unige.it/om/prg/R/altezzef.txt",n=3)
[1] "# Altezze di ragazze 20 enni di un dato paese (distrib. o/oo)"
[2] "146 1"
[3] "147 1"
# Vedo dal commento inziale che si tratta di dati dotati di frequenza
# Li esamino come tabella (solo alcune righe) (non indico come sono
# separati - dovrei farlo se lo fossero da ";" o da ",", non da " ")
read.table("http://macosa.dima.unige.it/om/prg/R/altezzef.txt",nrows=2)
V1 V2
1 146 1
2 147 1
# OK. Li carico in una variabile (dati)
dati <- read.table("http://macosa.dima.unige.it/om/prg/R/altezzef.txt")
# Ne visulizzo le dimensioni (39 righe di 2 dati ciascuna)
dim(dati)
[1] 39 2
# Controlliamo quanti sono i dati. Le colonne, come visto, sono V1 e V2
sum(dati$V2)
[1] 998
# In tutto sono 998 valori (essendo una distribuzione per 1000 è giusto
# che siano circa 1000; essendo 39 intervalli sarebbe non facile, a
# causa degli arrotondamenti, che la somma fosse proprio 1000).
# Ecco (per inciso) come tende a distribuirsi la somma:
# I dati raccolti da rete posso poi metterli (usando paste) in una variabile;
# ecco come metterci i dati raccolti prima in "dati":
d <- dati[1]; for(i in 2:length(dati)) d <- paste(d,",",dati[i],sep="")
# A questo punto se batto "d" ottengo i dati, che se voglio copio e
# incollo in una assegnazione del tipo dati2 <- c(...)
[1] "156,168,162,150,167,157,170,157,159,164,157,165,163,165,166,160,163,162,155"
#
# Vediamo come raccogliere ed esaminare da rete un file di dati con frequenza
readLines("http://macosa.dima.unige.it/om/prg/R/altezzef.txt",n=3)
[1] "# Altezze di ragazze 20 enni di un dato paese (distrib. o/oo)"
[2] "146 1"
[3] "147 1"
# Vedo dal commento inziale che si tratta di dati dotati di frequenza
# Li esamino come tabella (solo alcune righe) (non indico come sono
# separati - dovrei farlo se lo fossero da ";" o da ",", non da " ")
read.table("http://macosa.dima.unige.it/om/prg/R/altezzef.txt",nrows=2)
V1 V2
1 146 1
2 147 1
# OK. Li carico in una variabile (dati)
dati <- read.table("http://macosa.dima.unige.it/om/prg/R/altezzef.txt")
# Ne visulizzo le dimensioni (39 righe di 2 dati ciascuna)
dim(dati)
[1] 39 2
# Controlliamo quanti sono i dati. Le colonne, come visto, sono V1 e V2
sum(dati$V2)
[1] 998
# In tutto sono 998 valori (essendo una distribuzione per 1000 è giusto
# che siano circa 1000; essendo 39 intervalli sarebbe non facile, a
# causa degli arrotondamenti, che la somma fosse proprio 1000).
# Ecco (per inciso) come tende a distribuirsi la somma:
 # È una tabella di dati e relative frequenze. Vediamo uno dei modi
# in cui possiamo analizzarla.
# Metto in una variabile i dati e le loro frequenze usando il comando
# rep già visto.
dati2 <- rep(dati$V1,times=dati$V2)
# Col comando hist ne costruisco l'istogramma
hist(dati2,right=FALSE)
# Se voglio avere le freq. percentuali invece delle assolute aggiungo
# probability=TRUE o freq=FALSE
hist(dati2,right=FALSE,probability=TRUE)
# Se voglio classificare in intervalli a mio piacimento faccio:
hist(dati2,c(145,150,155,160,161,162,163,164,165,170,175,180,185),right=FALSE)
# In questo caso vengono visualizzate solo le frequenze percentuali
# È una tabella di dati e relative frequenze. Vediamo uno dei modi
# in cui possiamo analizzarla.
# Metto in una variabile i dati e le loro frequenze usando il comando
# rep già visto.
dati2 <- rep(dati$V1,times=dati$V2)
# Col comando hist ne costruisco l'istogramma
hist(dati2,right=FALSE)
# Se voglio avere le freq. percentuali invece delle assolute aggiungo
# probability=TRUE o freq=FALSE
hist(dati2,right=FALSE,probability=TRUE)
# Se voglio classificare in intervalli a mio piacimento faccio:
hist(dati2,c(145,150,155,160,161,162,163,164,165,170,175,180,185),right=FALSE)
# In questo caso vengono visualizzate solo le frequenze percentuali
 #
# Per avere la media di dati dotati di frequenza, oltre che procedere ad es.
# come qui, posso calcolarne la media pesata usando un apposito comando:
freq <- c(729,35,77,132,134,285,457,1401,1569)
dati <- c(2.5,7.5,15,25,35,45,55,67.5,87.5)
weighted.mean(dati, freq)
[1] 58.32019
# Posso fare la media pesata anche se ho le fr. rel.: 23.6% sono 5, gli altri 9:
weighted.mean(c(5,9), c(23.6,100-23.6))
[1] 8.056
# invece che calcolare: (5*23.6+9*(100-23.6))/100
#
# R è in grado di rappresentare dati memorizzati in quasi ogni formato.
# Se essi sono in un file occorre esaminarli prima di decidere come analizzarli.
# Vediamo un esempio di uso di un file recuperato da rete
readLines("http://macosa.dima.unige.it/om/prg/stf/alimger.txt",n=7)
[1] "' Consumo procapite in kg in Germania nel 1993 di alcuni generi alimentari:"
[2] "' cereali(escluso riso) patate ortaggi zucchero carne latte/latticini"
[3] "' vino"
[4] "71 cereali"
[5] "74 patate"
[6] "83 ortaggi"
[7] "34 zucch"
# Vedo che si tratta di dati rappresentabili con una diagramma
# a barre o un settore circolare, e che la seconda colonna
# ha la descrizione delle categorie. Metto i dati in una tabella
read.table("http://macosa.dima.unige.it/om/prg/stf/alimger.txt",skip=3, nrows=2)
V1 V2
1 71 cereali
2 74 patate
alimger <- read.table("http://macosa.dima.unige.it/om/prg/stf/alimger.txt",skip=3)
alimger
V1 V2
1 71 cereali
2 74 patate
3 83 ortaggi
4 34 zucch
5 86 carne
6 93 latte/ni
7 23 vino
# Rappresento la prima colonna e uso la seconda come nomi
barplot(alimger$V1,horiz=TRUE,names.arg=substr(alimger$V2,1,8),las=1)
abline(v=c(20,40,60,80), lty=3)
#
# Per avere la media di dati dotati di frequenza, oltre che procedere ad es.
# come qui, posso calcolarne la media pesata usando un apposito comando:
freq <- c(729,35,77,132,134,285,457,1401,1569)
dati <- c(2.5,7.5,15,25,35,45,55,67.5,87.5)
weighted.mean(dati, freq)
[1] 58.32019
# Posso fare la media pesata anche se ho le fr. rel.: 23.6% sono 5, gli altri 9:
weighted.mean(c(5,9), c(23.6,100-23.6))
[1] 8.056
# invece che calcolare: (5*23.6+9*(100-23.6))/100
#
# R è in grado di rappresentare dati memorizzati in quasi ogni formato.
# Se essi sono in un file occorre esaminarli prima di decidere come analizzarli.
# Vediamo un esempio di uso di un file recuperato da rete
readLines("http://macosa.dima.unige.it/om/prg/stf/alimger.txt",n=7)
[1] "' Consumo procapite in kg in Germania nel 1993 di alcuni generi alimentari:"
[2] "' cereali(escluso riso) patate ortaggi zucchero carne latte/latticini"
[3] "' vino"
[4] "71 cereali"
[5] "74 patate"
[6] "83 ortaggi"
[7] "34 zucch"
# Vedo che si tratta di dati rappresentabili con una diagramma
# a barre o un settore circolare, e che la seconda colonna
# ha la descrizione delle categorie. Metto i dati in una tabella
read.table("http://macosa.dima.unige.it/om/prg/stf/alimger.txt",skip=3, nrows=2)
V1 V2
1 71 cereali
2 74 patate
alimger <- read.table("http://macosa.dima.unige.it/om/prg/stf/alimger.txt",skip=3)
alimger
V1 V2
1 71 cereali
2 74 patate
3 83 ortaggi
4 34 zucch
5 86 carne
6 93 latte/ni
7 23 vino
# Rappresento la prima colonna e uso la seconda come nomi
barplot(alimger$V1,horiz=TRUE,names.arg=substr(alimger$V2,1,8),las=1)
abline(v=c(20,40,60,80), lty=3)
 # A destra la sua rappresentazione con un diagramma a torta:
pie(alimger$V1, substr(alimger$V2,1,8))
# La analoga rappresentazione grafica dei dati relativi all'Italia
# A destra la sua rappresentazione con un diagramma a torta:
pie(alimger$V1, substr(alimger$V2,1,8))
# La analoga rappresentazione grafica dei dati relativi all'Italia
 # Vedi qui per sovrapporre diagrammi a barre, qui per giustapporli.
# Vedi qui per sovrapporre diagrammi a barre, qui per giustapporli.

 # Vedi qui per realizzare diagrammi a striscia come i seguenti:
# Vedi qui per realizzare diagrammi a striscia come i seguenti:
 #
# Vediamo come analizzare dati da rete organizzati in altro modo:
readLines("http://macosa.dima.unige.it/om/prg/stf/alt87.txt",n=3)
[1] "'commento: altezze dei ventenni maschi italiani nel 1987"
[2] "'in [150,160), ..., [190,200) (distribuzione per 1000)"
[3] "150,20"
# Sono dati simili a quelli considerati qui, ma in rete
alt <- read.table("http://macosa.dima.unige.it/om/prg/stf/alt87.txt",sep=",",skip=2); alt
V1 V2
1 150 20
2 160 73
3 165 194
4 170 290
5 175 248
6 180 126
7 185 39
8 190 10
9 200 0
# Lo 0 finale non entra in gioco (vedi sotto). Metto gli estremi
# degli intervalli in interv e le frequenze in altezze
interv <- alt$V1; n <- length(interv); num_int <- n-1
# Gli estremi degli intervalli sono uno in più delle frequenze
altezze <- alt$V2[1:num_int]
totale <- sum(altezze); fr_perc <- altezze/totale*100; fr_perc
[1] 2.0 7.3 19.4 29.0 24.8 12.6 3.9 1.0
# Per avere la rappresentazione grafica procedo come già fatto per
# gli analoghi dati già considerati (devo togliere lo 0 finale in "freq")
interv <- alt$V1; freq <- alt$V2[1:(length(interv)-1)]
source("http://macosa.dima.unige.it/om/prg/r/daticlas.txt")
Frequenze percentuali:
2.0 7.3 19.4 29.0 24.8 12.6 3.9 1.0
Min. 1st Qu. Median Mean 3rd Qu. Max.
150.0 169.0 173.7 173.8 178.5 200.0
griglia <- seq(0.01,0.06,0.01); abline(h = griglia, lty=3)
#
# Vediamo come analizzare dati da rete organizzati in altro modo:
readLines("http://macosa.dima.unige.it/om/prg/stf/alt87.txt",n=3)
[1] "'commento: altezze dei ventenni maschi italiani nel 1987"
[2] "'in [150,160), ..., [190,200) (distribuzione per 1000)"
[3] "150,20"
# Sono dati simili a quelli considerati qui, ma in rete
alt <- read.table("http://macosa.dima.unige.it/om/prg/stf/alt87.txt",sep=",",skip=2); alt
V1 V2
1 150 20
2 160 73
3 165 194
4 170 290
5 175 248
6 180 126
7 185 39
8 190 10
9 200 0
# Lo 0 finale non entra in gioco (vedi sotto). Metto gli estremi
# degli intervalli in interv e le frequenze in altezze
interv <- alt$V1; n <- length(interv); num_int <- n-1
# Gli estremi degli intervalli sono uno in più delle frequenze
altezze <- alt$V2[1:num_int]
totale <- sum(altezze); fr_perc <- altezze/totale*100; fr_perc
[1] 2.0 7.3 19.4 29.0 24.8 12.6 3.9 1.0
# Per avere la rappresentazione grafica procedo come già fatto per
# gli analoghi dati già considerati (devo togliere lo 0 finale in "freq")
interv <- alt$V1; freq <- alt$V2[1:(length(interv)-1)]
source("http://macosa.dima.unige.it/om/prg/r/daticlas.txt")
Frequenze percentuali:
2.0 7.3 19.4 29.0 24.8 12.6 3.9 1.0
Min. 1st Qu. Median Mean 3rd Qu. Max.
150.0 169.0 173.7 173.8 178.5 200.0
griglia <- seq(0.01,0.06,0.01); abline(h = griglia, lty=3)
 #
# Qui vedi come costruire un diagramma in coordinate polari
#
# Qui vedi come costruire un diagramma in coordinate polari
 # un altro
# un altro
 # e un altro ancora
# e un altro ancora
 # e come realizzare la ripartizione di un cerchio in centesimi
# e come realizzare la ripartizione di un cerchio in centesimi


 # e di un rettangolo in mm quadrati (che poi puoi stampare e usare a mano)
# e di un rettangolo in mm quadrati (che poi puoi stampare e usare a mano)
 #
# Qui vedi come costruire un diagramma a bolle (bubble chart)
#
# Qui vedi come costruire un diagramma a bolle (bubble chart)
 |
Area dei dischi proporzionale alla densità di popolazione di alcune regioni;
dischi centrati nei capoluoghi di regione (ogni disco rappresenta tre dati: la densità di popolazione e le due
coordinate geografiche della città). I diagrammi a bolle sono rappresentazioni "carine" ma che
(tranne in pochi casi, come questo) non sono facilmente "leggibili".
Sotto (vedi) una variante e, (poi)
una in cui l'intensità del colore delle bolle indica un'altra grandezza: |

 #
# Qui trovi come costruire grafi di flusso e simili ...
#
# Qui trovi come costruire grafi di flusso e simili ...



 #
# runif è il generatore di numeri pseudocasuali
runif(1); runif(1); runif(1)
[1] 0.889635
[1] 0.7682307
[1] 0.3944371
# vengono generati numeri con valori "casuali" tra 0 ed 1 (che
# sono uniformemente distribuiti, ossia che tendono ad avere la
# stessa frequenza in sottointervalli di eguale ampiezza; tra 0
# e 1/3 e tra 2/3 ed 1 abbiamo percentuali di uscite che tendono
# ad eguagliarsi); con runif posso ottenere altri valori casuali,
# ad es. relativi al lancio di un dado (per floor vedi):
floor(runif(1)*6)+1; floor(runif(1)*6)+1; floor(runif(1)*6)+1
[1] 4
[1] 1
[1] 6
# Opzioni: runif(7) o runif(3,min=1,max=7) generano 7 "numeri casuali" tra
# 0 ed 1 o 3 tra 1 e 7. Ecco come ottenere 25 lanci di un dado equo:
floor(runif(25,min=1,max=7))
[1] 3 6 5 4 2 4 3 4 3 1 3 6 2 4 1 4 6 1 2 2 5 1 4 1 5
# il comando set.seed(n) ("stabilire il seme") con n numero naturale fa partire la
# successione "casuale" da un dato valore (con lo stesso n ho la stessa sequenza):
set.seed(3); floor( runif(20,min=1,max=7) )
[1] 2 5 3 2 4 4 1 2 4 4 4 4 4 4 6 5 1 5 6 2
set.seed(3); floor( runif(20,min=1,max=7) )
[1] 2 5 3 2 4 4 1 2 4 4 4 4 4 4 6 5 1 5 6 2
# C'è, tuttavia, la possibilità di usare sample ("campione") per generare uscite casuali
# come runif ma arrotondate agli interi: qui sotto 1:6 specifica il range delle uscite,
# 20 la quantità, replace=TRUE specifica che le stesse uscite possono ripetersi
set.seed(3); sample(1:6,20,replace=TRUE)
[1] 2 5 3 2 4 4 1 2 4 4 4 4 4 4 6 5 1 5 6 2
# Invece con sample(m:n) vengono generate tutte le uscite m, m+1, …, n ordinate a caso
sample(1:6); set.seed(3); sample(1:6); set.seed(3); sample(1:6)
sample(1:6); set.seed(3); sample(1:6); set.seed(3); sample(1:6)
[1] 4 3 5 2 6 1
[1] 2 5 6 1 4 3
[1] 2 5 6 1 4 3
# Ecco la media del lancio di 1000 dadi (che si avvicina a 3.5), in vari modi. Metto
# i dati in una variabile indiciata (x) [o vettore] che inizializzo con x <- NULL (vedi)
tot<-1000; x<-NULL; for (i in 1:tot) x[i] <- floor(runif(1)*6)+1; mean(x)
[1] 3.426
# ovvero:
tot<-1000; x<-NULL; x[1:tot] <- floor(runif(tot)*6)+1; mean(x)
[1] 3.472
# o (usando sample):
tot <- 1000; x <- NULL; x[1:tot] <- sample(1:6,tot,replace=TRUE)
[1] 3.505
# Il lancio di due dadi:
tot <- 10000; x <- NULL
for (i in 1:tot) x[i] <- sample(1:6,1)+sample(1:6,1)
# o, ad esempio:
tot <- 10000; x <- NULL
x[1:tot] <- sample(1:6,tot,replace=TRUE)+sample(1:6,tot,replace=TRUE)
# e poi:
hist(x,seq(1.5,12.5,1),right=FALSE,xlab="",main="",freq=FALSE)
#
# runif è il generatore di numeri pseudocasuali
runif(1); runif(1); runif(1)
[1] 0.889635
[1] 0.7682307
[1] 0.3944371
# vengono generati numeri con valori "casuali" tra 0 ed 1 (che
# sono uniformemente distribuiti, ossia che tendono ad avere la
# stessa frequenza in sottointervalli di eguale ampiezza; tra 0
# e 1/3 e tra 2/3 ed 1 abbiamo percentuali di uscite che tendono
# ad eguagliarsi); con runif posso ottenere altri valori casuali,
# ad es. relativi al lancio di un dado (per floor vedi):
floor(runif(1)*6)+1; floor(runif(1)*6)+1; floor(runif(1)*6)+1
[1] 4
[1] 1
[1] 6
# Opzioni: runif(7) o runif(3,min=1,max=7) generano 7 "numeri casuali" tra
# 0 ed 1 o 3 tra 1 e 7. Ecco come ottenere 25 lanci di un dado equo:
floor(runif(25,min=1,max=7))
[1] 3 6 5 4 2 4 3 4 3 1 3 6 2 4 1 4 6 1 2 2 5 1 4 1 5
# il comando set.seed(n) ("stabilire il seme") con n numero naturale fa partire la
# successione "casuale" da un dato valore (con lo stesso n ho la stessa sequenza):
set.seed(3); floor( runif(20,min=1,max=7) )
[1] 2 5 3 2 4 4 1 2 4 4 4 4 4 4 6 5 1 5 6 2
set.seed(3); floor( runif(20,min=1,max=7) )
[1] 2 5 3 2 4 4 1 2 4 4 4 4 4 4 6 5 1 5 6 2
# C'è, tuttavia, la possibilità di usare sample ("campione") per generare uscite casuali
# come runif ma arrotondate agli interi: qui sotto 1:6 specifica il range delle uscite,
# 20 la quantità, replace=TRUE specifica che le stesse uscite possono ripetersi
set.seed(3); sample(1:6,20,replace=TRUE)
[1] 2 5 3 2 4 4 1 2 4 4 4 4 4 4 6 5 1 5 6 2
# Invece con sample(m:n) vengono generate tutte le uscite m, m+1, …, n ordinate a caso
sample(1:6); set.seed(3); sample(1:6); set.seed(3); sample(1:6)
sample(1:6); set.seed(3); sample(1:6); set.seed(3); sample(1:6)
[1] 4 3 5 2 6 1
[1] 2 5 6 1 4 3
[1] 2 5 6 1 4 3
# Ecco la media del lancio di 1000 dadi (che si avvicina a 3.5), in vari modi. Metto
# i dati in una variabile indiciata (x) [o vettore] che inizializzo con x <- NULL (vedi)
tot<-1000; x<-NULL; for (i in 1:tot) x[i] <- floor(runif(1)*6)+1; mean(x)
[1] 3.426
# ovvero:
tot<-1000; x<-NULL; x[1:tot] <- floor(runif(tot)*6)+1; mean(x)
[1] 3.472
# o (usando sample):
tot <- 1000; x <- NULL; x[1:tot] <- sample(1:6,tot,replace=TRUE)
[1] 3.505
# Il lancio di due dadi:
tot <- 10000; x <- NULL
for (i in 1:tot) x[i] <- sample(1:6,1)+sample(1:6,1)
# o, ad esempio:
tot <- 10000; x <- NULL
x[1:tot] <- sample(1:6,tot,replace=TRUE)+sample(1:6,tot,replace=TRUE)
# e poi:
hist(x,seq(1.5,12.5,1),right=FALSE,xlab="",main="",freq=FALSE)
 # Nota: se i dati sono interi 1,2,3,… scelgo gli estremi degli intervalli 0.5,1.5,2.5,3.5,…
# in modo che le colonne sia centrate sugli interi; se i dati sono arrotondati ai decimi
# come 7.2,7.3,7.4,… scelgo gli estremi 7.15,7.25,7.35,7.45,… in modo che le colonne siano
# centrate in 7.2,7.3,7.4,… E così via.
#
# Vediamo l'istogramma della distribuzione teorica, ossia delle probabilità
# Introduciamo i singoli dati ciascuno con la sua frequenza (per due
# dadi equi mettiamo le freq. attese 1,2,3,4,5,6,5,4,3,2,1)
dadi <- c(rep(2,1),rep(3,2),rep(4,3),rep(5,4),rep(6,5),rep(7,6),
rep(8,5),rep(9,4),rep(10,3),rep(11,2),rep(12,1))
hist(dadi,seq(1.5,12.5,1))
# Come per ogni istogramma, posso controllare le frequenze con counts:
hist(dadi,seq(1.5,12.5,1))$counts
[1] 1 2 3 4 5 6 5 4 3 2 1
# Per avere sulla scala verticale le freq. relative uso:
hist(dadi,seq(1.5,12.5,1), probability=TRUE)
# o: hist(dadi,seq(1.5,12.5,1), freq=FALSE)
# Nota: se i dati sono interi 1,2,3,… scelgo gli estremi degli intervalli 0.5,1.5,2.5,3.5,…
# in modo che le colonne sia centrate sugli interi; se i dati sono arrotondati ai decimi
# come 7.2,7.3,7.4,… scelgo gli estremi 7.15,7.25,7.35,7.45,… in modo che le colonne siano
# centrate in 7.2,7.3,7.4,… E così via.
#
# Vediamo l'istogramma della distribuzione teorica, ossia delle probabilità
# Introduciamo i singoli dati ciascuno con la sua frequenza (per due
# dadi equi mettiamo le freq. attese 1,2,3,4,5,6,5,4,3,2,1)
dadi <- c(rep(2,1),rep(3,2),rep(4,3),rep(5,4),rep(6,5),rep(7,6),
rep(8,5),rep(9,4),rep(10,3),rep(11,2),rep(12,1))
hist(dadi,seq(1.5,12.5,1))
# Come per ogni istogramma, posso controllare le frequenze con counts:
hist(dadi,seq(1.5,12.5,1))$counts
[1] 1 2 3 4 5 6 5 4 3 2 1
# Per avere sulla scala verticale le freq. relative uso:
hist(dadi,seq(1.5,12.5,1), probability=TRUE)
# o: hist(dadi,seq(1.5,12.5,1), freq=FALSE)
 summary(dadi)
Min. 1st Qu. Median Mean 3rd Qu. Max.
2 5 7 7 9 12
#
# Un esempio di come, con runif, si può simulare il lancio di un dado non equo:
# [ricordiamo che e' un grave errore, didattico e concettuale, definire la
# probabilità come "casi favorevoli"/"totale dei casi": bisogna fare l'ipotesi
# che le uscite siano equiprobabili, il che è un evidente circolo vizioso, e che
# siano finite, il che elimina gran parte dei casi; occorre poi escludere tutti
# i casi in cui non si ha ripetizione (la valutazione probabilistica "per me 40
# su 100 il Doria vincerà la partita" verrebbe esclusa), … (vedi)]
summary(dadi)
Min. 1st Qu. Median Mean 3rd Qu. Max.
2 5 7 7 9 12
#
# Un esempio di come, con runif, si può simulare il lancio di un dado non equo:
# [ricordiamo che e' un grave errore, didattico e concettuale, definire la
# probabilità come "casi favorevoli"/"totale dei casi": bisogna fare l'ipotesi
# che le uscite siano equiprobabili, il che è un evidente circolo vizioso, e che
# siano finite, il che elimina gran parte dei casi; occorre poi escludere tutti
# i casi in cui non si ha ripetizione (la valutazione probabilistica "per me 40
# su 100 il Doria vincerà la partita" verrebbe esclusa), … (vedi)]
 #
# Vedi qui per come usare sample o runif per ordinare casualmente una quantità
# finita di oggetti, ad es. per generare un mazzo di carte.
#
# Vedi qui o l'es. 2.11 qui o l'es. 4.1 qui per esempi d'uso del generatore di
# numeri casuali per valutare la precisione di termini "complessi" contenenti
# dati approssimati. Per esempi più semplici vedi quanto segue.
#
# Se ho valori approssimati, ecco come posso calcolare l'intervallo di
# indeterminazione di somma, prodotto, differenza e rapporto tra essi:
# (NULL serve per avviare l'uso di una variabile senza assegnarle valori;
# è utile soprattutto per avviare l'uso di una variabile indiciata)
x <- c(4.6, 4.7); y <- c(3.1, 3.2); I <- 1:2
r <- NULL;for(i in I)for(j in I)r <- c(r,x[i]+y[j]);c(min(r),max(r))
[1] 7.7 7.9
r <- NULL;for(i in I)for(j in I)r <- c(r,x[i]*y[j]);c(min(r),max(r))
[1] 14.26 15.04
# che posso approssimare a [14.2, 15.1]
r <- NULL;for(i in I)for(j in I)r <- c(r,x[i]-y[j]);c(min(r),max(r))
[1] 1.4 1.6
r <- NULL;for(i in I)for(j in I)r <- c(r,x[i]/y[j]);c(min(r),max(r))
[1] 1.437500 1.516129
# che posso approssimare a [1.43, 1.52]
# Ovvero:
r<- c(x[1]+y[1],x[1]+y[2],x[2]+y[1],x[2]+y[2]); r<- c(min(r),max(r)); r; r[2]-r[1]
r<- c(x[1]-y[1],x[1]-y[2],x[2]-y[1],x[2]-y[2]); r<- c(min(r),max(r)); r; r[2]-r[1]
r<- c(x[1]*y[1],x[1]*y[2],x[2]*y[1],x[2]*y[2]); r<- c(min(r),max(r)); r; r[2]-r[1]
r<- c(x[1]/y[1],x[1]/y[2],x[2]/y[1],x[2]/y[2]); r<- c(min(r),max(r)); r; r[2]-r[1]
[1] 7.7 7.9
[1] 0.2
[1] 1.4 1.6
[1] 0.2
[1] 14.26 15.04
[1] 0.78
[1] 1.43750000 1.51612903
[1] 0.07862903
# Ovvero:
f <- function(x,y) x+y; H <- function(i,j) f(x[i],y[j])
r <- c(H(1,1),H(1,2),H(2,1),H(2,2)); r <- c(min(r),max(r)); r; r[2]-r[1]
[1] 7.7 7.9
[1] 0.2
f <- function(x,y) x/y; H <- function(i,j) f(x[i],y[j])
r <- c(H(1,1),H(1,2),H(2,1),H(2,2)); r <- c(min(r),max(r)); r; r[2]-r[1]
[1] 1.437500 1.516129
[1] 0.07862903
#
# la rappresentazione grafica di dati dotati di precisione (±10 per le x, ±20
# per le y); rect traccia un rettangolo (i parametri sono 2 vertici opposti).
x1 <- -10; x2 <- 300; y1 <- -20; y2 <- 500
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="",las=1)
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
abline(h=0, col="brown"); abline(v=0, col="brown")
x<-c(50,130,230); y <-c(90,240,470)
eps1<-10; eps2<-20; rect(x-eps1,y-eps2,x+eps1,y+eps2)
#
# Vedi qui per come usare sample o runif per ordinare casualmente una quantità
# finita di oggetti, ad es. per generare un mazzo di carte.
#
# Vedi qui o l'es. 2.11 qui o l'es. 4.1 qui per esempi d'uso del generatore di
# numeri casuali per valutare la precisione di termini "complessi" contenenti
# dati approssimati. Per esempi più semplici vedi quanto segue.
#
# Se ho valori approssimati, ecco come posso calcolare l'intervallo di
# indeterminazione di somma, prodotto, differenza e rapporto tra essi:
# (NULL serve per avviare l'uso di una variabile senza assegnarle valori;
# è utile soprattutto per avviare l'uso di una variabile indiciata)
x <- c(4.6, 4.7); y <- c(3.1, 3.2); I <- 1:2
r <- NULL;for(i in I)for(j in I)r <- c(r,x[i]+y[j]);c(min(r),max(r))
[1] 7.7 7.9
r <- NULL;for(i in I)for(j in I)r <- c(r,x[i]*y[j]);c(min(r),max(r))
[1] 14.26 15.04
# che posso approssimare a [14.2, 15.1]
r <- NULL;for(i in I)for(j in I)r <- c(r,x[i]-y[j]);c(min(r),max(r))
[1] 1.4 1.6
r <- NULL;for(i in I)for(j in I)r <- c(r,x[i]/y[j]);c(min(r),max(r))
[1] 1.437500 1.516129
# che posso approssimare a [1.43, 1.52]
# Ovvero:
r<- c(x[1]+y[1],x[1]+y[2],x[2]+y[1],x[2]+y[2]); r<- c(min(r),max(r)); r; r[2]-r[1]
r<- c(x[1]-y[1],x[1]-y[2],x[2]-y[1],x[2]-y[2]); r<- c(min(r),max(r)); r; r[2]-r[1]
r<- c(x[1]*y[1],x[1]*y[2],x[2]*y[1],x[2]*y[2]); r<- c(min(r),max(r)); r; r[2]-r[1]
r<- c(x[1]/y[1],x[1]/y[2],x[2]/y[1],x[2]/y[2]); r<- c(min(r),max(r)); r; r[2]-r[1]
[1] 7.7 7.9
[1] 0.2
[1] 1.4 1.6
[1] 0.2
[1] 14.26 15.04
[1] 0.78
[1] 1.43750000 1.51612903
[1] 0.07862903
# Ovvero:
f <- function(x,y) x+y; H <- function(i,j) f(x[i],y[j])
r <- c(H(1,1),H(1,2),H(2,1),H(2,2)); r <- c(min(r),max(r)); r; r[2]-r[1]
[1] 7.7 7.9
[1] 0.2
f <- function(x,y) x/y; H <- function(i,j) f(x[i],y[j])
r <- c(H(1,1),H(1,2),H(2,1),H(2,2)); r <- c(min(r),max(r)); r; r[2]-r[1]
[1] 1.437500 1.516129
[1] 0.07862903
#
# la rappresentazione grafica di dati dotati di precisione (±10 per le x, ±20
# per le y); rect traccia un rettangolo (i parametri sono 2 vertici opposti).
x1 <- -10; x2 <- 300; y1 <- -20; y2 <- 500
plot(c(x1,x2),c(y1,y2),type="n",xlab="", ylab="",las=1)
abline(v=axTicks(1), h=axTicks(2), col="blue",lty=3)
abline(h=0, col="brown"); abline(v=0, col="brown")
x<-c(50,130,230); y <-c(90,240,470)
eps1<-10; eps2<-20; rect(x-eps1,y-eps2,x+eps1,y+eps2)
 # se so che il fenomeno è del tipo y = kx posso trovare un intervallo
# di indeterminazione per k in questo modo:
a1 <- max((90-eps2)/(50+eps1), (240-eps2)/(130+eps1), (470-eps2)/(230+eps1))
a2 <- min((90+eps2)/(50-eps1), (240+eps2)/(130-eps1), (470+eps2)/(230-eps1))
a1; a2
# o più in breve:
a1 <- max((y-eps2)/(x+eps1)); a2 <- min((y+eps2)/(x-eps1)); a1; a2
[1] 1.875
[1] 2.166667
# k sta in [1.9, 2.2], o in [1.87, 2.17]
# le rette corrispondenti sono state tracciate con:
abline(0,a1); abline(0,a2)
# Vedi qui per un esempio un po' più complesso.
#
# Tre macchine che producono in tre fasi successive certi pezzi hanno, in
# ordine, rendimenti dell'89% (l'89% dei pezzi è trasformato correttamente),
# del 51% e del 70%. Quanto vale il rendimento percentuale medio complessivo?
# In questo caso devo fare la media geometrica, ossia trovare il fattore
# moltiplicativo medio (la radice n-ma del prodotto degli n dati):
rend <- c(89,70,51)/100
geomean <- function(dati) prod(dati)^(1/length(dati))
geomean(rend)
[1] 0.6823692
# È la percentuale che applicata 3 volte equivale alla successiva
# applicazione delle tre percentuali date:
p <- geomean(rend); geomean(c(p,p,p))
[1] 0.6823692
#
# Se i dati sono in quantità N pari R, con median, ordinati i dati, interpola
# tra quello di posto [N/2] e quello di posto [N/2]+1. Se si vuole prendere
# come mediana il dato di posto [N/2] si può usare:
mediana <- function(x) {n <- length(x); ifelse(floor(n/2)!=n/2,median(x),median(sort(x)[1:(n-1)]))}
a <- c(1,2,4,6,7,9,3,1); sort(a); median(a); mediana(a)
[1] 1 1 2 3 4 6 7 9
[1] 3.5
[1] 3
#
# Ricordiamo che hist consente di classificare i dati. Un esempio:
esDati <- c(1,2,2,3,3,3,4,4,4,4,5,5,5,5,5,6,7,8,9)
# Classifico negli intervalli aperti a destra [0,3), [3,6), [6,10)
hist(esDati,c(0,3,6,10), plot=FALSE, right=FALSE)$counts
[1] 3 12 4
# e negli intervalli ampi 1 e centrati in 1, 2, …, 9
hist(esDati, seq(0.5, 9.5, 1), plot=FALSE)$counts
[1] 1 2 3 4 5 1 1 1 1
# se so che il fenomeno è del tipo y = kx posso trovare un intervallo
# di indeterminazione per k in questo modo:
a1 <- max((90-eps2)/(50+eps1), (240-eps2)/(130+eps1), (470-eps2)/(230+eps1))
a2 <- min((90+eps2)/(50-eps1), (240+eps2)/(130-eps1), (470+eps2)/(230-eps1))
a1; a2
# o più in breve:
a1 <- max((y-eps2)/(x+eps1)); a2 <- min((y+eps2)/(x-eps1)); a1; a2
[1] 1.875
[1] 2.166667
# k sta in [1.9, 2.2], o in [1.87, 2.17]
# le rette corrispondenti sono state tracciate con:
abline(0,a1); abline(0,a2)
# Vedi qui per un esempio un po' più complesso.
#
# Tre macchine che producono in tre fasi successive certi pezzi hanno, in
# ordine, rendimenti dell'89% (l'89% dei pezzi è trasformato correttamente),
# del 51% e del 70%. Quanto vale il rendimento percentuale medio complessivo?
# In questo caso devo fare la media geometrica, ossia trovare il fattore
# moltiplicativo medio (la radice n-ma del prodotto degli n dati):
rend <- c(89,70,51)/100
geomean <- function(dati) prod(dati)^(1/length(dati))
geomean(rend)
[1] 0.6823692
# È la percentuale che applicata 3 volte equivale alla successiva
# applicazione delle tre percentuali date:
p <- geomean(rend); geomean(c(p,p,p))
[1] 0.6823692
#
# Se i dati sono in quantità N pari R, con median, ordinati i dati, interpola
# tra quello di posto [N/2] e quello di posto [N/2]+1. Se si vuole prendere
# come mediana il dato di posto [N/2] si può usare:
mediana <- function(x) {n <- length(x); ifelse(floor(n/2)!=n/2,median(x),median(sort(x)[1:(n-1)]))}
a <- c(1,2,4,6,7,9,3,1); sort(a); median(a); mediana(a)
[1] 1 1 2 3 4 6 7 9
[1] 3.5
[1] 3
#
# Ricordiamo che hist consente di classificare i dati. Un esempio:
esDati <- c(1,2,2,3,3,3,4,4,4,4,5,5,5,5,5,6,7,8,9)
# Classifico negli intervalli aperti a destra [0,3), [3,6), [6,10)
hist(esDati,c(0,3,6,10), plot=FALSE, right=FALSE)$counts
[1] 3 12 4
# e negli intervalli ampi 1 e centrati in 1, 2, …, 9
hist(esDati, seq(0.5, 9.5, 1), plot=FALSE)$counts
[1] 1 2 3 4 5 1 1 1 1