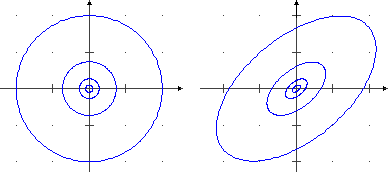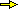 dipendenza e indipendenza
stocastica.
dipendenza e indipendenza
stocastica. Approfondiamo lo studio dei rapporti tra variabili casuali,
già avviato introducendo i concetti di
dipendenza e indipendenza
stocastica.
 Esempio 1
Esempio 1
Due tipi di cadute a caso di proiettili in un bersaglio. Vogliamo stimare sperimentalmente la probabilità che, prendendo "a caso" un punto in un bersaglio composto da due cerchi concentrici con raggi uno doppio dell'altro, il punto cada nel cerchio centrale. Consideriamo due possibili procedimenti, di cui puoi esaminare una versione come "script" (bersaglio) o in R (vedi qui), mediante i quali viene generato un punto che cade nel cerchio di centro O=(0,0) e raggio 1 e verificato se la sua distanza da O è minore di 1/2 (ovvero se il quadrato di essa è minore di 0.25):
Qui sotto sono riprodotti le parti dei due procedimenti con il contenuto del ciclo (le variabili lanci e ok contano una i lanci, l'altra quelli per i quali viene centrato il cerchio piccolo).
x=random()*2-1; y=random()*2-1;
if (x*x+y*y<1) {lanci=lanci+1; if (x*x+y*y<0.25) {ok=ok+1} } | |
|
| Con il primo procedimento ottengo esiti simili ai seguenti: | ||
|
n.lanci % OK 7856 25.58554 |
Col secondo: |
n.lanci % OK 10000 50.01 |
|
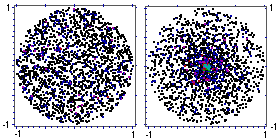
Rappresentazione grafica con gli script: |  |
I due procedimenti generano i punti in modo diverso: mentre il primo usa
il generatore di numeri casuali per ottenere un punto nel quadrato
Mentre col primo i proiettili si distribuiscono in modo uniforme nel cerchio, col secondo si distribuiscono concentrandosi maggiormente intorno a (0,0). Mentre col primo la frequenza tende a stabilizzarsi su 1/4, pari al rapporto tra area del centro e area del bersaglio, col secondo tende a stabilizzarsi su 1/2: il fatto che il punto generati disti meno di metà raggio dal centro dipende solo dal valore di r, che essendo con distribuzione uniforme in [0,1), ha il 50% di probabilità di essere minore di 1/2.
Si tratta di due cadute casuali con diverse leggi di distribuzione.
Qui stiamo estendendo il concetto di legge di distribuzione dal caso di una variabile casuale U a valori numerici al caso di U = (X,Y) con X e Y variabili casuali a valori in
Esempio 2
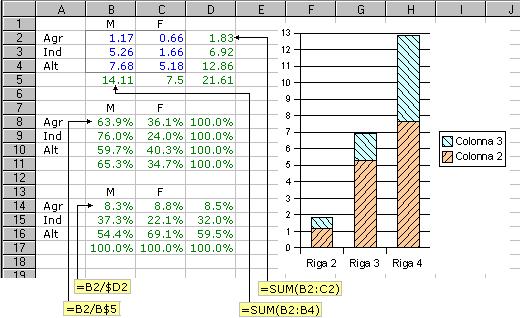
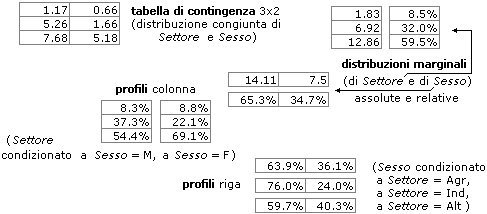
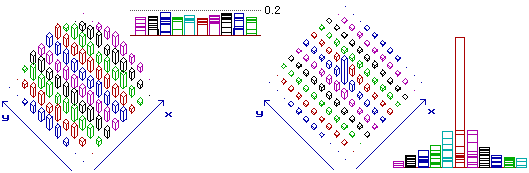
Calcolando le distribuzioni percentuali riga per riga (vedi seconda tabella nella figura sottostante, che, come la seguente, puoi cliccare per ingrandirla) posso valutare meglio le relazioni di dipendenza/indipendenza tra le due variabili. Concludo immediatamente che le variabili "sesso" (a uscite: M, F) e "settore" (a uscite: agr., ind., altro) non sono indipendenti: le righe dei dati non sono più o meno proporzionali (ovvero le righe delle percentuali non sono più o meno uguali). Posso invece ritenere indipendenti "sesso" (degli occupati) e "occupazione in agricoltura" (a uscite: sì, no): 1ª e 4ª riga sono "quasi" proporzionali.
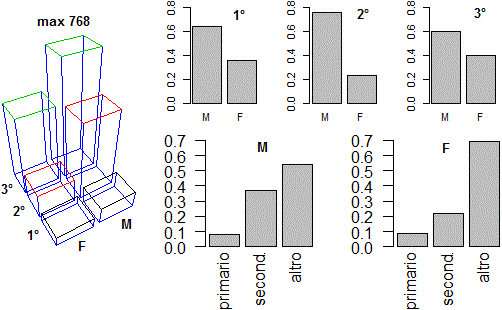
A volte, nella manipolazione delle tabelle di contingenza, si usano alcune terminologie specifiche (distribuzioni marginali, profili riga e colonna), richiamate (riferendosi al nostro esempio) nelle figure sopra e sottostanti, che illustrano anche come un foglio di calcolo elettronico può essere utile per rappresentare (percentualmente e graficamente) ed elaborare tabelle di dati (i dati sono stati scritti nel "rettangolo" B2-C4, le elaborazioni numeriche sono state ottenute con le 4 "formule" riprodotte, che sono state "estese" verticalmente od orizzontalmente alle altre celle, con una modifica automatica dei "riferimenti" ai dati da elaborare; l'istogramma rappresenta sia la distribuzione di Settore che le tre distribuzioni condizionate di Sesso).
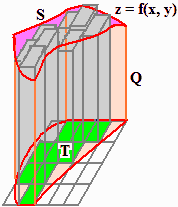
Possiamo rappresentarne completamente la distribuzione con un istogramma tridimensionale, come quello sotto a sinistra: le altezze delle colonne rappresentano le frequenze relative; le altre figure rappresentano le distribuzioni percentuali delle due variabili. Qui trovi come elaborare i dati mediante R.
Nel caso di una singola variabile a valori in un intervallo di numeri reali realizzavamo un istogramma classificando
le uscite in intervallini; analogamente, nel nuovo caso, possiamo rappresentare le distribuzioni classificando le uscite
in tanti rettangolini.
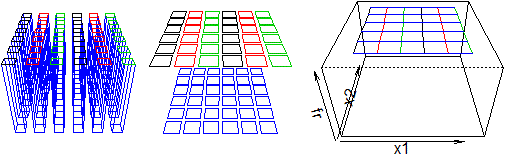
Nel caso dell'esempio iniziale, la caduta dei proiettili, siamo di fronte a un sistema (X,Y) di variabili casuali non discrete. Un'idea della distribuzione mi è fornita dal grafico di dispersione (scatter diagram), ossia dalla rappresentazione grafica delle coppie di uscite sperimentali:
Per una rappresentazione tridimensionale osserviamo che, come nel caso di una singola variabile a valori in un intervallo di numeri reali realizzavamo un istogramma classificando le uscite in intervallini, analogamente, ora, possiamo rappresentare le distribuzioni classificando le uscite in tanti rettangolini la cui unione copra il dominio delle uscite. Ecco possibili rappresentazioni per i due tipi di cadute, in cui le colonnine sono state separate per facilitare la "lettura". [vedi qui se vuoi ottenerle con R]
Nel caso di una variabile continua X all'aumentare delle prove e all'infittirsi della partizione il contorno superiore
dell'istogramma sperimentale (normalizzato, in modo che sia di area 1) tende a stabilizzarsi su una curva tale che
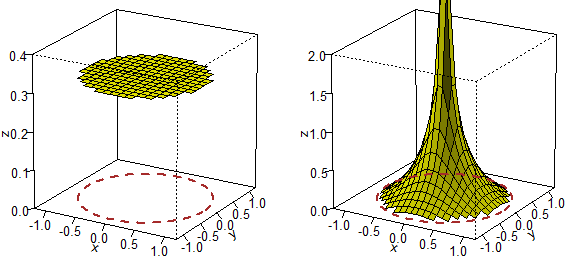
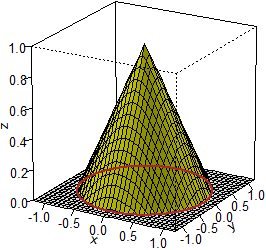
Sotto sono raffigurate la funzione di densitŕ f corrispondente al secondo caso e alcune relative curve di livello (vedi qui come realizzarle con R). Tenendo conto che, per come sono generati i punti, il grafico deve essere simmetrico rispetto all'asse z e del fatto che la probabilità che un punto cadi a meno della distanza R da (0,0) è R, si puň ricavare che si tratta della superficie generata dalla rotazione attorno all'asse z di una curva del piano xz che ha l'asse z come asintoto verticale. La figura non è limitata superiormente, ma ha volume finito (uguale ad 1).
Osserviamo che, come abbiamo già visto che una
superficie illimitata può avere area finita (
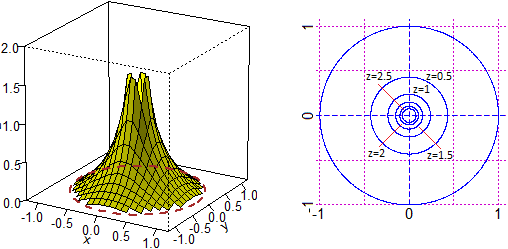
Come si fa a capire dal grafico della distribuzione di U=(X,Y) se X e Y sono variabili casuali indipendenti o no? In generale, passando alle funzioni di densità al posto delle righe e delle file di colonnine si considerano le sezioni parallele al piano xz e le sezioni parellele al piano yz: due qualunque sezioni, ad esempio parallele al piano xz, devono essere ottenibili una dall'altra mediante una dilatazione/contrazione verticale. Nel caso delle funzioni densità dei due esempi inziali, dei proettili, ciò non accade mai: ad esempio la sezione determinata dal piano yz non ha lo stesso andamento (a meno di un fattore di scala) di nessuna delle altre sezioni ad essa parallela. Del resto è intuitivo che il valore di X e quello di Y sono tra loro condizionati: devono essere le coordinate di un punto che sta nel cerchio (X2+Y2 deve essere al più 1; se X è vicino ad 1 Y per forza deve essere vicino a 0). Nel caso del sistema di variabili avente densità che ha per grafico un cono circolare retto, considerato sopra, X e Y sono indipendenti? Evidentemente no, per le stesse motivazioni usate per le altre densità appena considerate.
Potrebbe avere una forma simile la distribuzione di (X,Y) con X e Y altezze di marito e moglie di una coppia sorteggiata a caso: l'altezza di uomini spostati con donne di una certa altezza ha andamento più o meno gaussiano, ma la loro altezza media è maggiore di quella degli uomini sposati con donne più basse (uomini più alti tendenzialmente sposano donne più alte: non è affatto vero che l'amore è cieco!). Ma la dipendenza tra X e Y in questo ultimo caso è in un qualche senso "più forte" di quella che c'era tra X e Y nel caso dei proiettili: là avevamo che i valori che poteva assumere una delle due variabili era condizionato da quello che assumeva l'altra, qui abbiamo qualcosa di più: al crescere di X anche Y tende a crescere. Su questo aspetto ci si sofferma nella successiva voce "correlazione". Sotto sono tracciate alcune curve di livello delle due ultimi superfici considerate. Nel primo caso sono ellissi simmetriche rispetto agli assi x e y, nel secondo hanno assi di simmetria obliqui, a conferma del fatto che al crescere dell'uscita X l'uscita di Y tende a crescere anch'essa.
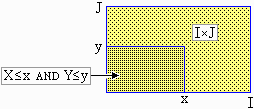
Vediamo, a grandi linee, come precisare le considerazioni precedenti. Consideriamo U = (X ,Y) con X e Y variabili casuali a valori in IR. Siano X e Y a valori negli intervalli, rispettivamente, I e J. U ha valori in I×J. La legge di distribuzione di U è nota quando so calcolare i valori di una misura di probabilità Pr su tutti gli eventi del tipo U∈E×F con E e F sottointervalli di I e J: Pr(U∈E×F) = Pr(X∈E and Y∈F). Con la additività posso poi valutare Pr(U∈D) per altri domini D (cioè per altri insiemi ottenibili come "unioni numerabili di rettangolini"). I punti in cui cadono i
Nel caso discreto (X e Y variabili discrete) la legge di distribuzione è
nota se so calcolare i valori della misura di probabilità Pr su tutti gli eventi del tipo
U = In tal caso la legge di distribuzione è rappresentabile con un istogramma tridimensionale, come quello raffigurato all'inizio del
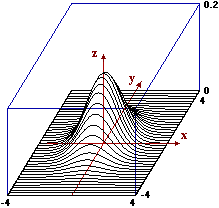
Si ha che X e Y (continue) sono indipendenti sse f(x,y) = f1(x)·f2(y), dove f1 e f2 sono le funzioni di densità di X e Y. In altre parole, le sezioni con piani y=k sono tra loro scalate verticalmente (f(x,k) = f1(x)·f2(k)) e una cosa analoga accade per le sezioni con piani x=k. Nel caso discreto, si ha un istogramma tridimensionale le cui righe [colonne] di parallelepipedi sono istogrammi (bidimensionali) che sarebbero tra loro uguali se normalizzati. Ciò traduce il fatto che comunque fissi X [Y], la variabile Y [X] si distribuisce sempre allo stesso modo, senza subire influenze. Nel paragrafo precedente il primo grafico riprodotto è della funzione di densità di U=(X,Y)
dove X e Y hanno densità gaussiana di media 0 e s.q.m. 1 e sono indipendenti. Le curve di livello sono cerchi con centro (0,0).
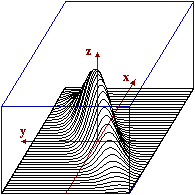
Anche la seconda funzione rappresentata graficamente nel precedente paragrafo è la densità di U=(X,Y) con X e Y aventi densità gaussiana di media 0 e s.q.m. 1, ma in questo caso X e Y non sono indipendenti; ad es., è evidente che le sezioni parallele al piano yz sono curve con il punto di massimo che man mano si sposta verso destra (avanza lungo la direzione dell'asse y). Le curve di livello in questo caso particolare sono ellissi aventi le bisettrici dei quadranti come assi di simmetria. Gli integrali di funzioni di due variabili possono essere affrontati facilmente
con WolframAlpha: per calcolare l'integrale per x ed y tra −∞ e ∞ della prima delle
funzioni precedenti basta battere: Esercizi: Vedi qui per un uso di R impiegando la libreria
| |||||||||||||||||||||||||||||||||||||||