Valori medi (2)
 La media aritmetica, o più semplicemente media, di un insieme di dati [
La media aritmetica, o più semplicemente media, di un insieme di dati [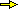 valori medi 1] consente di fornire con un unico numero un'idea complessiva del fenomeno a cui i dati si riferiscono (altezze delle femmine di una certa età, consumo di carne degli abitanti di un certo paese, …..).
valori medi 1] consente di fornire con un unico numero un'idea complessiva del fenomeno a cui i dati si riferiscono (altezze delle femmine di una certa età, consumo di carne degli abitanti di un certo paese, …..).
In alcune situazioni particolari conviene usare altri valori medi, cioè numeri che sintetizzano il fenomeno ma che non si ottengono calcolando medie aritmetiche di altri dati: la velocità media, la pendenza media, ... non sono medie aritmetiche di velocità, di pendenze, … [ valori medi 1];
la variazione percentuale media non è la media aritmetica di una sequenza di variazioni percentuali [ variazione].
Si tratta, comunque, di concetti simili: in tutti i casi si è
preso come valore "medio" il valore uguale (consumo di carne, velocità, pendenza, variazione percentuale, …:) che
dovrebbe riscontarsi in ogni rilevamento (quanta carne dovrebbe consumare ogni cittadino, quale velocità
media dovrebbe essere mantenuta in ogni tratto, quale pendenza dovrebbe avere ogni segmento, quale valore dovrebbe
avere ciascuna variazione percentuale, …) in modo da rappresentare fedelmente l'esito complessivo (ossia il consumo totale di carne, la
velocità media sull'intero percorso, la pendenza del segmento che congiunge
punto iniziale e punto finale, la variazione percentuale complessiva, … siano quelli effettivamente rilevati).
Anche nel caso delle indagini statistiche, per caratterizzare una distribuzione con un'unica informazione si può ricorrere a indicatori diversi dalla media aritmetica, la moda e la mediana. Anche questi indicatori, chiamati in genere, assieme alla media artirmetica, indici di posizione della distribuzione,
vengono considerati dei valori medi, nononostante che ad essi non possa essere estesa l'interpretazione
dell'aggettivo "medio" spiegata nel capoverso precedente.
| Nel caso in cui le modalità non siano di tipo numerico non ha senso considerare la media aritmetica. Si possono invece considerare le mode (o classi modali), cioè le modalità con frequenza massima. Se l'istogramma a fianco rappresentasse la distribuzione degli alunni di una classe rispetto al cantante preferito, potremmo dire che quella classe preferisce i cantanti B ed E. | |
x x
x x
x x x x
x x x x x x
x x x x x x x
—————————————
A B C D E F G
 classi modali
classi modali |
Soffermiamoci sul caso delle modalità di tipo numerico. Si possono usare come indicatori medi: la media, la moda (o le mode: possono essere piů di una) e la mediana.
• La media (aritmetica) di una sequenza di dati può essere calcolata direttamente [ valori medi 1] o, se vi sono dati con valore uguale, contando prima la frequenza dei vari valori:
| Valore1·FrequenzaDelValore1 + Valore2·FrequenzaDelValore2 + ... | (*) |
| ———————————————————————————————————————————————————————————————— |
| NumeroDeiDati |
• Per calcolare la media dei dati 253, 254, 259 e 256, tutti vicini a 250, conviene fare la media di 3, 4, 9 e 6 e poi aggiungere 250; più in generale se x1, x2, ….., xN sono tutti dati vicini a H può convenire trasformare il calcolo della media nel modo seguente:
| x1+x2+x3+...+xN |
→ |
(x1-H)+(x2-H)+(x3-H)+...+(xN-H) |
+ H |
|
——————————————— |
—————————————————————————————— |
| N | N |
Se i dati di cui ho calcolato la media erano approssimati, devo approssimare anche il risultato.
Ad esempio se calcolo la media di 19 altezze arrotondate ai centimetri 156, 168, ... (vedi la tabella riportata più avanti), ottengo 161.3684, risultato approssimato di (156+168+...)/19. Non tutte le cifre di esso sono significative, poiché i dati erano arrotondati agli interi. Se i dati sono pochi la media che si ottiene deve essere arrotondata agli interi.
Ma se i dati sono almeno una decina, come in questo caso, poiché le approssimazioni per difetto e quelle per eccesso in parte si compensano, si puň prendere la media arrotondata ai decimi. Piů in generale se i dati fossero arrotondati alla cifra di posto n si puň arrotondare la media alla cifra di posto n-1 (ossia prendere una cifra in più rispetto ai dati di cui si fa la media). Clicca qui se vuoi fare
delle prove.
Quindi possiamo prendere come altezza media 161.4.
Se i dati sono almeno un migliaio si puň arrotondare la media fino alla cifra di
posto n-2 (ad es. se i dati arrotondati agli interi la media puň essere arrotondata ai centesimi:
si prendono 2 cifre in più). Questa scelta puň essere motivata con considerazioni di calcolo
delle probabilitŕ che, per ora, non siamo in grado di affrontare
( limiti
in probabilità).
Vediamo come comportarsi se i dati sono troncati.
Ad es. se ho 47 misure di tempo troncate ai centesimi di secondo 97, 102, ... alla media 99.42553 che
ottengo come valore di (97+102+...)/47 devo aggiungere 0.5, cioè considerare 99.42553 + 0.5 = 99.92553.
Infatti: i singoli dati sono troncati, cioè hanno tutti errore negativo; per una stima migliore della media sarebbero serviti dati approssimati "al numero piů vicino", i cui errori, sommando, in parte si compensano (come nel caso dei dati arrotondati); ma posso osservare che per passare a dati approssimati "al numero piů vicino" basta aggiungere 0.5 ai dati originali: vedi la figura a seguente; e ciò equivale ad aggiungere 0.5 alla media (0.5 è l'"H" del punto precedente).
Il valore 99.92553 così ottenuto può poi essere arrotondato a 99.9 (infatti i dati sono più di una decina).

Nel caso della altezze (in cm) considerate  sopra, per le quali SommaDati/QuantitàDati vale 161.3684, se si fosse trattato di troncamenti avremmo potuto prendere come media 161, da intendersi come valore troncato, o 162 (arrotondamento agli interi di 161.3684+0.5), da intendersi come valore arrotondato, o, essendo i dati abbastanza numerosi, prendere come valore arrotondato ai decimi 161.9 (arrotondamento di 161.3684+0.5).
sopra, per le quali SommaDati/QuantitàDati vale 161.3684, se si fosse trattato di troncamenti avremmo potuto prendere come media 161, da intendersi come valore troncato, o 162 (arrotondamento agli interi di 161.3684+0.5), da intendersi come valore arrotondato, o, essendo i dati abbastanza numerosi, prendere come valore arrotondato ai decimi 161.9 (arrotondamento di 161.3684+0.5).
Se non dispongo dei dati originali ma solo di una tabella di distribuzione, posso stimare la media con la precedente formula (*) prendendo come Valore1, Valore2, ... i centri degli intervalli.
Ad esempio nel caso della tabella considerata alla voce distribuzione posso fare:
729·2.5+35·7.5+77·15+132·25+134·35+285·45+457·55+1401·67.5+1569·87.5
———————————————————————————————————————————————————————————————————— =
729+35+77+132+134+285+1401+1569 |
281045
———————— = 58.32019
4819 |
e dire che nel 1951 l'età media di morte era circa 58 anni. La stima non può essere più precisa in quanto gli intervalli erano molto ampi [si pensi, per es., all'ultimo intervallo: [75,100); ho proceduto come se tutti i morti oltre i 75 anni fossero deceduti a 87.5 anni, ma probabilmente la maggior parte sono deceduti a un'età inferiore].
Le mode dipendono dalla distribuzione: gli stessi dati classificati in modalità diverse possono dar luogo a istogrammi con forme molto differenti. Sotto sono riprodotti gli istogrammi delle tre distribuzioni di uno stesso insieme di dati ottenute suddividendo lo stesso intervallo in 6, in 8 e in 12 sottointervalli uguali.

|
Nota. La forma dell'istogramma con cui si rappresenta
la distribuzione di un insieme di dati dipende dalla scelta del numero delle classi. Si possono fare tentativi con diverse scelte e prendere l'istogramma che sembra dare un'idea migliore dell'andamento dei dati. Non esiste un criterio rigoroso, ma come primo tentativo si può prendere un numero di classi pari circa alla radice quadrata del numero dei dati: |
| si pensi a un istogramma a crocette: una crocetta per ogni dato che cade in una classe; se i dati fossero distribuiti uniformemente e si prendessero tante classi quanti i dati si avrebbe una crocetta per colonna, se si prende NumeroClassi ≈ √(NumeroDati) si hanno in ogni colonna circa tante crocette quante sono le classi. |  |
La mediana di una sequenza di dati è il valore del dato che sta al centro dell'elenco dei dati disposti in ordine crescente (in altre parole è il 50° percentile); nel caso dei dati riportati nella prima riga della tabella seguente (sono le altezze di alunni considerate sopra ) la mediana è 162:
dati
dati ordinati |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 156 |
168 |
162 |
150 |
167 |
157 |
170 |
157 |
159 |
164 |
157 |
165 |
163 |
165 |
166 |
160 |
163 |
162 |
155 |
| 150 |
155 |
156 |
157 |
157 |
157 |
159 |
160 |
162 |
162 |
163 |
163 |
164 |
165 |
165 |
166 |
167 |
168 |
170 | |
Se i dati sono in quantità pari, i valori al centro dell'elenco ordinato sono due. Si può convenire di scegliere l'uno o l'altro. Noi adotteremo la convenzione di prendere il primo di essi; nel caso sotto considerato è 171.
dati ordinati |
| 1 | 2 |
3 | 4 |
5 | 6 |
7 | 8 |
9 | 10 |
11 | 12 |
13 | 14 |
15 | 16 |
17 | 18 |
| 165 | 166 |
167 | 167 |
167 | 169 |
170 | 171 |
171 | 172 |
173 | 174 |
175 | 175 |
176 | 177 |
178 | 179 |
|
|
Nota. Alcuni, in casi come questo, usano una terza convenzione: invece di prendere come mediana il primo o il secondo dei due dati centrali, ne prendono la media aritmetica. Nell'esempio soprastante sarebbe da prendere la media tra 171 e 172, ossia 171.5. Si tratta di una convenzione non sempre sensata:
• si possono ottenere dati con più cifre significative di quelle che sono effettivamente "significative": se i dati fossero "giorni del mese in cui è piovuto" e i dati centrali fossero 6 e 7, che senso avrebbe considerare come mediana 6.5 giorni di pioggia, ossia un valore espresso in decimi di giorno?
• non si tiene conto dell'eventuale approssimazione dei dati: nel caso delle altezze già considerato, se si trattasse di dati troncati il valore 171.5 non avrebbe alcun senso: 171 indica l'intervallo [171,172], 172 indica [172,173], e 171.5 non starebbe al centro dell'intervallo [171,173]; ma anche se si trattasse di dati arrotondati, nel qual caso i due dati centrali rappresenterebbero [170.5, 172.5], il valore 171.5 susciterebbe considerazioni illusorie sulla precisione dei dati.
Se non dispongo dei dati originali ma solo di una tabella di distribuzione, posso stimare la mediana calcolando le frequenze cumulate.
Ad es. nel caso della tabella considerata alla voce distribuzione, sommando le frequenze di [0,5) e di [5,10) trovo la frequenza di [0,10), aggiungendo la frequenza di [10,20) trovo la frequenza di [0,20), e così via, fino a completare la prima riga della seguente tabella (dove "< 5" sta per [0,5), "< 10" sta per [0,10),...).
Calcolando il rapporto con il totale trovo le frequenze cumulate percentuali, che mi dicono che il primo 38.3% delle età di morte sono inferiori a 60 e che il 32.6% finale, dal 67.4% al 100%, di età di morte sono superiori a 75.
| età dei morti (Italia,1951) | | freq. cumulata (in migliaia) | | freq. cumulata relativa |
|
| <5 |
<10 |
<20 |
<30 |
<40 |
<50 |
<60 |
<75 |
totale |
| 729 |
764 |
841 |
973 |
1107 |
1392 |
1849 |
3250 |
4819 |
| 15.1% |
15.8% |
17.4% |
20.1% |
22.9% |
28.8% |
38.3% |
67.4% |
100% |
|
| | Quindi il dato che sta a metà nell'elenco delle età di morte, cioè che delimita il primo 50% dei dati dai dati rimanenti, cade tra 60 anni e 75 anni. Cioè posso dire che il dato centrale cade nella classe [60,75). |
 |
| Per stimare con più precisione la mediana posso cercare la ascissa che corrisponde alla linea verticale che taglia l'istogramma in due parti di area uguale e trovare che è circa 66. Per determinare numericamente questo valore posso procedere nel modo seguente: |  |
parte 50-38.3
? = 60 + —————— · (ampiezza di [60,75)) = 60 + ————————— · 15 =
totale 67.4-38.3
= [con la CT] 66.03... = [troncando] 66
|
Ho troncato agli interi in quanto questo è il modo in cui in genere si esprimono le età. L'età mediana di morte nel 1951 è quindi di circa 66 anni.
Devo dire "circa" perchè nel fare il calcolo ho fatto finta che (tra 60 e 75 anni) le variazioni di età e le variazioni della frequenza cumulata siano proporzionali (cioè che per ogni anno ci sia lo stesso numero di morti). Per una stima più precisa dovrei disporre di una classificazione in intervalli di età più piccoli. Per una spiegazione geometrica del metodo con cui è stata stimata la mediana vedi qui.
Se ho un istogramma di distribuzione dalla forma simmetrica, in cui media e mediana cadono entrambe nella classe centrale, e tolgo pezzi da colonne a destra della colonna centrale e li sposto più a destra, la media ovviamente aumenta (alcuni dati sono sostituiti da dati dal valore maggiore) mentre la mediana resta immutata (infatti alla sua destra e alla sua sinistra rimane comunque il 50% dei dati):

Per questo motivo la mediana spesso è un indicatore più significativo della media: se fra i dati con valore alto ve ne sono alcuni con valore altissimo (che danno luogo a una "coda" sulla destra dell'istogramma), questa presenza "strana", mentre non incide sul valore della mediana, può influenzare molto il valore della media. Lo stesso si può dire nel caso di alcuni dati dal valore "bassisimo" rispetto agli altri (che danno luogo a una "coda" sulla sinistra dell'istogramma).
| Ad esempio supponiamo che i 100 abitanti adulti di un certo paese rispetto al reddito annuo (in milioni di lire) si distribuiscano così: 4 in [0,10) - cioè 4 abitanti con reddito inferiore a 10 milioni -, 30 in [10,20), 38 in [20,40), 11 in [40,60), 11 in [60,100), 2 in [100,150), 4 in [150,200), come nell'istogramma a lato. Il reddito medio è circa 40 milioni, quello mediano è circa 28 milioni: la presenza della coda destra (le poche persone con reddito molto alto) aumenta il valore medio. | |  |
Se al posto dei 4 "ricchi" arrivassero 4 "superricchi" di cui 3 con reddito tra 2 e 3 miliardi (2000 e 3000 milioni) e l'altro tra 4 e 5 miliardi, il fenomeno diverrebbe ancora più evidente: l'ultima colonna dell'istogramma sarebbe stata sostituita da due molto più a destra, per cui la coda si allungherebbe ulteriormente; il reddito mediano resterebbe immutato (28 milioni), mentre il reddito medio diventerebbe circa 150 milioni, dando l'impressione, distorta, che il tenore di vita degli abitanti del paese sia mutato profondamente.
• L'esercizio a cui puoi accedere da qui
illustra un modo semplice e comodo per riportare informazioni numeriche sui
dati raccolti e, contestualmente, di darne una rappresentazione grafica:
i diagrammi stem-and-leaf. Vedi l'esercizio e il suo svolgimento
per prendere confidenza con essi.
• Col computer
puoi provare a rivedere alcuni esempi o affrontare alcuni degli esercizi proposti usando il
programma R, il cui uso è discusso ed esemplificato qui.
Esercizi: testo 1 e soluzione,
altri: .
 altri collegamenti [nuova pagina]
altri collegamenti [nuova pagina]
